 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Dynamicity in a Production LLM Serving System with SOTA Optimizations via Hybrid Prefill/Decode/Verify Scheduling on Efficient Meta-kernels
Dec 24, 2024



Meeting growing demands for low latency and cost efficiency in production-grade large language model (LLM) serving systems requires integrating advanced optimization techniques. However, dynamic and unpredictable input-output lengths of LLM, compounded by these optimizations, exacerbate the issues of workload variability, making it difficult to maintain high efficiency on AI accelerators, especially DSAs with tile-based programming models. To address this challenge, we introduce XY-Serve, a versatile, Ascend native, end-to-end production LLM-serving system. The core idea is an abstraction mechanism that smooths out the workload variability by decomposing computations into unified, hardware-friendly, fine-grained meta primitives. For attention, we propose a meta-kernel that computes the basic pattern of matmul-softmax-matmul with architectural-aware tile sizes. For GEMM, we introduce a virtual padding scheme that adapts to dynamic shape changes while using highly efficient GEMM primitives with assorted fixed tile sizes. XY-Serve sits harmoniously with vLLM. Experimental results show up to 89% end-to-end throughput improvement compared with current publicly available baselines on Ascend NPUs. Additionally, our approach outperforms existing GEMM (average 14.6% faster) and attention (average 21.5% faster) kernels relative to existing libraries. While the work is Ascend native, we believe the approach can be readily applicable to SIMT architectures as well.
Deepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Oct 13, 2022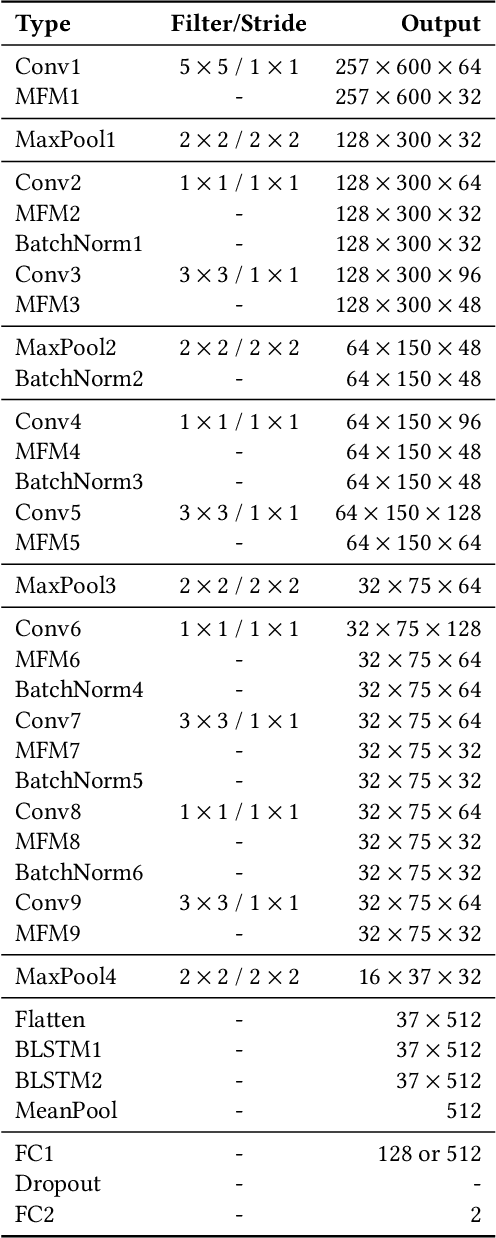
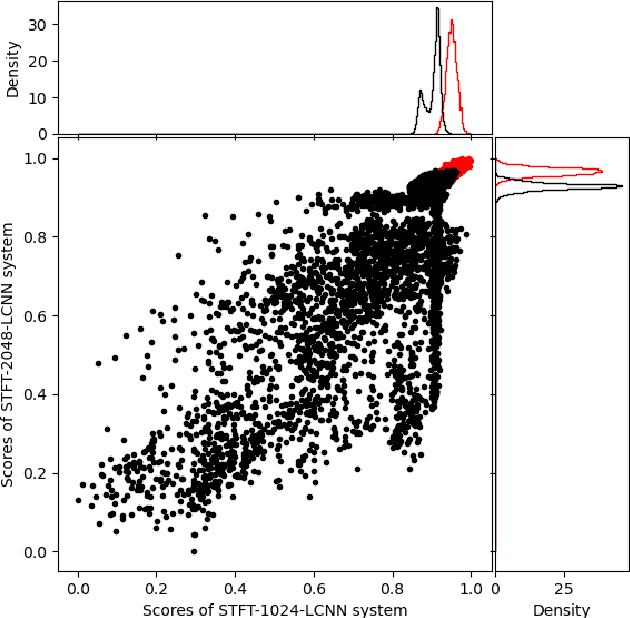
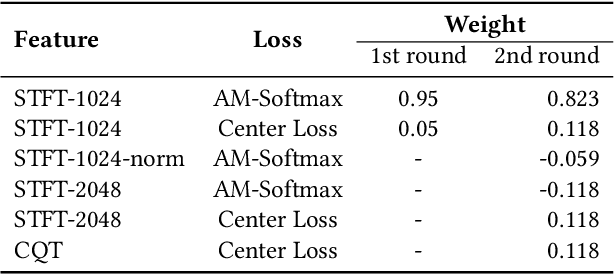
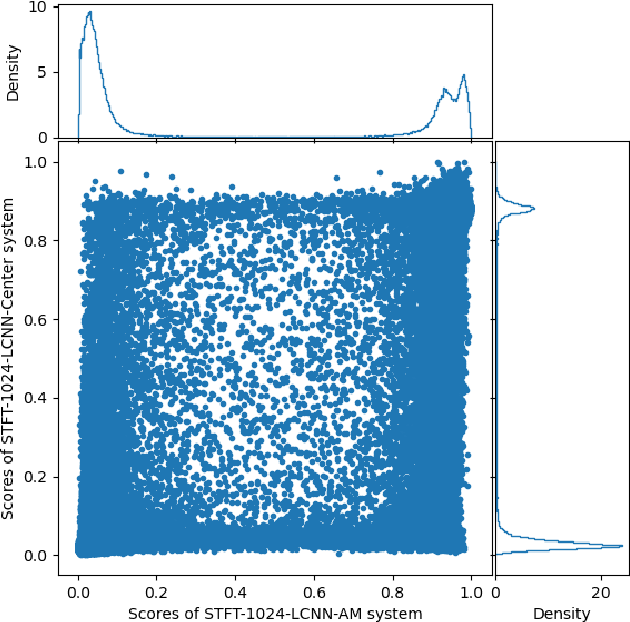
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.
The HCCL System for the NIST SRE21
Jul 11, 2022
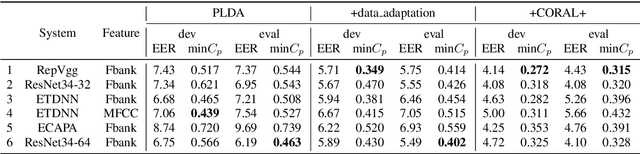
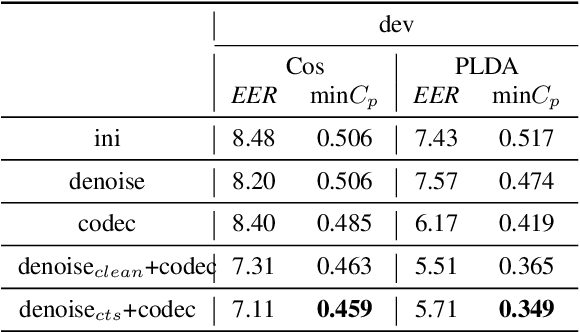
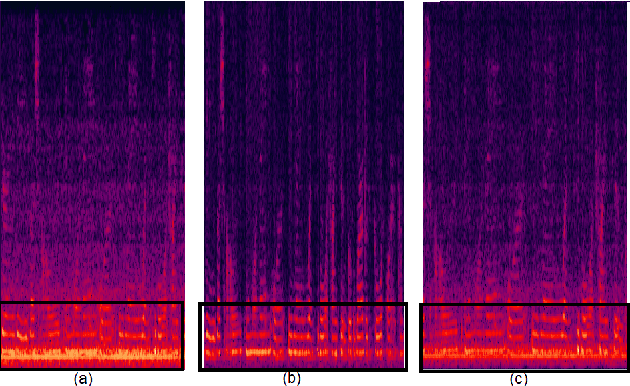
This paper describes the systems developed by the HCCL team for the NIST 2021 speaker recognition evaluation (NIST SRE21).We first explore various state-of-the-art speaker embedding extractors combined with a novel circle loss to obtain discriminative deep speaker embeddings. Considering that cross-channel and cross-linguistic speaker recognition are the key challenges of SRE21, we introduce several techniques to reduce the cross-domain mismatch. Specifically, Codec and speech enhancement are directly applied to the raw speech to eliminate the codecs and the environment noise mismatch. We denote the methods that work directly on speech to eliminate the relatively explicit mismatches collectively as data adaptation methods. Experiments show that data adaption methods achieve 15\% improvements over our baseline. Furthermore, some popular back-ends domain adaptation algorithms are deployed on speaker embeddings to alleviate speaker performance degradation caused by the implicit mismatch. Score calibration is a major failure for us in SRE21. The reason is that score calibration with too many parameters easily lead to overfitting problems.
Back-ends Selection for Deep Speaker Embeddings
Apr 25, 2022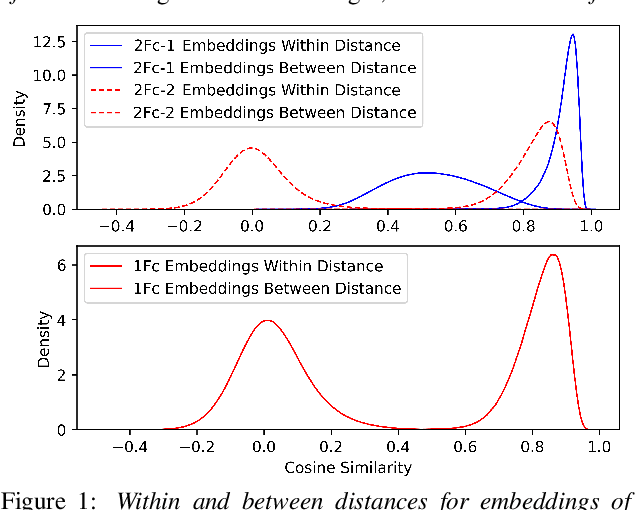
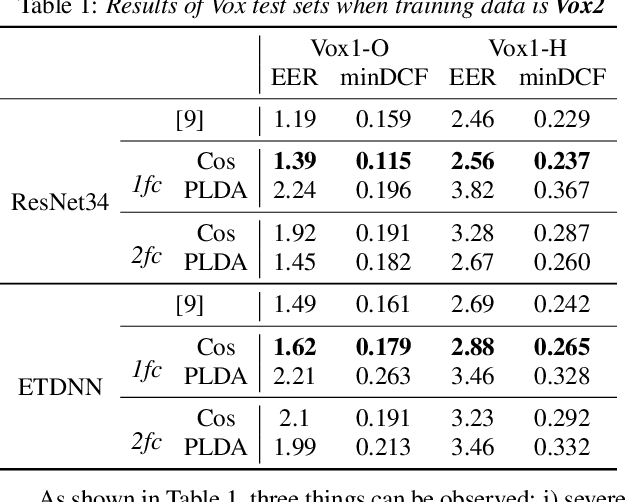
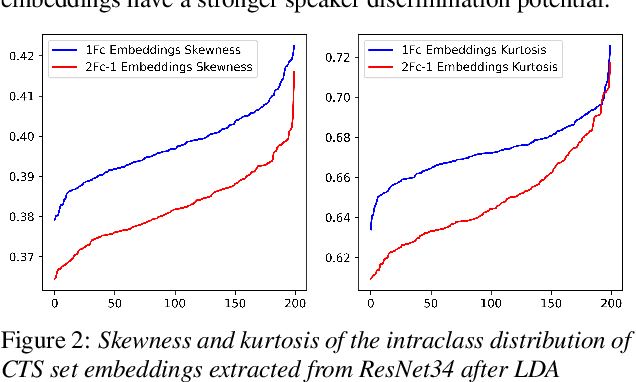
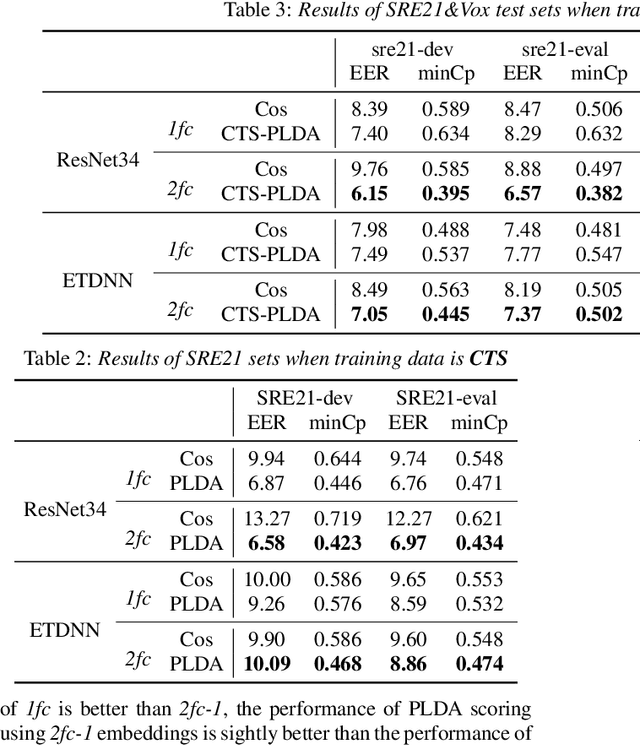
Probabilistic Linear Discriminant Analysis (PLDA) was the dominant and necessary back-end for early speaker recognition approaches, like i-vector and x-vector. However, with the development of neural networks and margin-based loss functions, we can obtain deep speaker embeddings (DSEs), which have advantages of increased inter-class separation and smaller intra-class distances. In this case, PLDA seems unnecessary or even counterproductive for the discriminative embeddings, and cosine similarity scoring (Cos) achieves better performance than PLDA in some situations. Motivated by this, in this paper, we systematically explore how to select back-ends (Cos or PLDA) for deep speaker embeddings to achieve better performance in different situations. By analyzing PLDA and the properties of DSEs extracted from models with different numbers of segment-level layers, we make the conjecture that Cos is better in same-domain situations and PLDA is better in cross-domain situations. We conduct experiments on VoxCeleb and NIST SRE datasets in four application situations, single-/multi-domain training and same-/cross-domain test, to validate our conjecture and briefly explain why back-ends adaption algorithms work.
The HCCL Speaker Verification System for Far-Field Speaker Verification Challenge
Jul 03, 2021


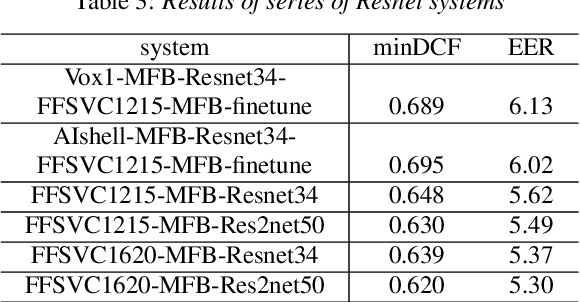
This paper describes the systems submitted by team HCCL to the Far-Field Speaker Verification Challenge. Our previous work in the AIshell Speaker Verification Challenge 2019 shows that the powerful modeling abilities of Neural Network architectures can provide exceptional performance for this kind of task. Therefore, in this challenge, we focus on constructing deep Neural Network architectures based on TDNN, Resnet and Res2net blocks. Most of the developed systems consist of Neural Network embeddings are applied with PLDA backend. Firstly, the speed perturbation method is applied to augment data and significant performance improvements are achieved. Then, we explore the use of AMsoftmax loss function and propose to join a CE-loss branch when we train model using AMsoftmax loss. In addition, the impact of score normalization on performance is also investigated. The final system, a fusion of four systems, achieves minDCF 0.5342, EER 5.05\% on task1 eval set, and achieves minDCF 0.5193, EER 5.47\% on task3 eval set.
Adaptive Margin Circle Loss for Speaker Verification
Jun 15, 2021

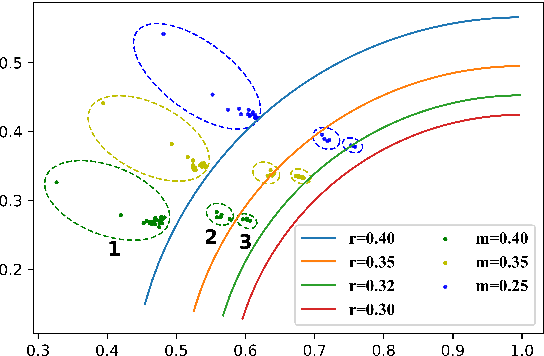
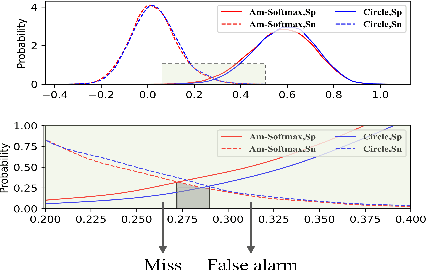
Deep-Neural-Network (DNN) based speaker verification sys-tems use the angular softmax loss with margin penalties toenhance the intra-class compactness of speaker embeddings,which achieved remarkable performance. In this paper, we pro-pose a novel angular loss function called adaptive margin cir-cle loss for speaker verification. The stage-based margin andchunk-based margin are applied to improve the angular discrim-ination of circle loss on the training set. The analysis on gradi-ents shows that, compared with the previous angular loss likeAdditive Margin Softmax(Am-Softmax), circle loss has flexi-ble optimization and definite convergence status. Experimentsare carried out on the Voxceleb and SITW. By applying adap-tive margin circle loss, our best system achieves 1.31%EER onVoxceleb1 and 2.13% on SITW core-core.