 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Spatial Architectures for Sparse Attention: STAR Accelerator via Cross-Stage Tiling
Dec 24, 2025Large language models (LLMs) rely on self-attention for contextual understanding, demanding high-throughput inference and large-scale token parallelism (LTPP). Existing dynamic sparsity accelerators falter under LTPP scenarios due to stage-isolated optimizations. Revisiting the end-to-end sparsity acceleration flow, we identify an overlooked opportunity: cross-stage coordination can substantially reduce redundant computation and memory access. We propose STAR, a cross-stage compute- and memory-efficient algorithm-hardware co-design tailored for Transformer inference under LTPP. STAR introduces a leading-zero-based sparsity prediction using log-domain add-only operations to minimize prediction overhead. It further employs distributed sorting and a sorted updating FlashAttention mechanism, guided by a coordinated tiling strategy that enables fine-grained stage interaction for improved memory efficiency and latency. These optimizations are supported by a dedicated STAR accelerator architecture, achieving up to 9.2$\times$ speedup and 71.2$\times$ energy efficiency over A100, and surpassing SOTA accelerators by up to 16.1$\times$ energy and 27.1$\times$ area efficiency gains. Further, we deploy STAR onto a multi-core spatial architecture, optimizing dataflow and execution orchestration for ultra-long sequence processing. Architectural evaluation shows that, compared to the baseline design, Spatial-STAR achieves a 20.1$\times$ throughput improvement.
cuPilot: A Strategy-Coordinated Multi-agent Framework for CUDA Kernel Evolution
Dec 23, 2025Optimizing CUDA kernels is a challenging and labor-intensive task, given the need for hardware-software co-design expertise and the proprietary nature of high-performance kernel libraries. While recent large language models (LLMs) combined with evolutionary algorithms show promise in automatic kernel optimization, existing approaches often fall short in performance due to their suboptimal agent designs and mismatched evolution representations. This work identifies these mismatches and proposes cuPilot, a strategy-coordinated multi-agent framework that introduces strategy as an intermediate semantic representation for kernel evolution. Key contributions include a strategy-coordinated evolution algorithm, roofline-guided prompting, and strategy-level population initialization. Experimental results show that the generated kernels by cuPilot achieve an average speed up of 3.09$\times$ over PyTorch on a benchmark of 100 kernels. On the GEMM tasks, cuPilot showcases sophisticated optimizations and achieves high utilization of critical hardware units. The generated kernels are open-sourced at https://github.com/champloo2878/cuPilot-Kernels.git.
PADE: A Predictor-Free Sparse Attention Accelerator via Unified Execution and Stage Fusion
Dec 16, 2025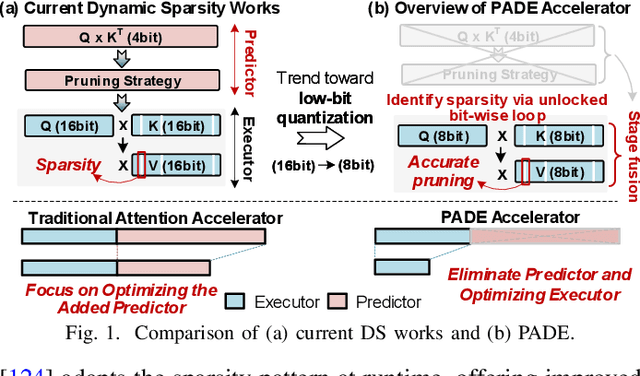
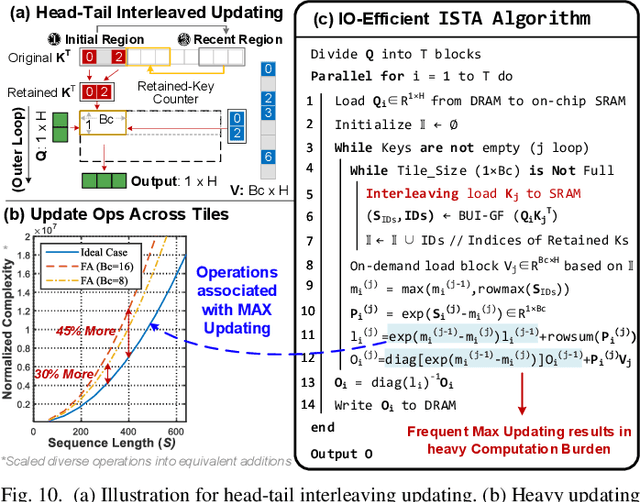
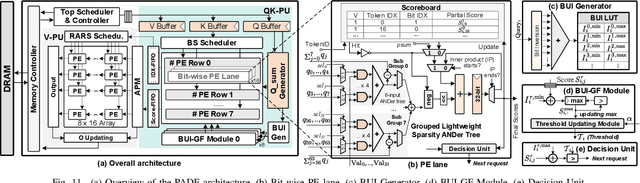
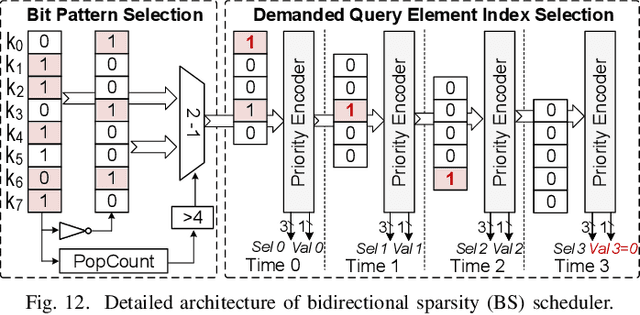
Attention-based models have revolutionized AI, but the quadratic cost of self-attention incurs severe computational and memory overhead. Sparse attention methods alleviate this by skipping low-relevance token pairs. However, current approaches lack practicality due to the heavy expense of added sparsity predictor, which severely drops their hardware efficiency. This paper advances the state-of-the-art (SOTA) by proposing a bit-serial enable stage-fusion (BSF) mechanism, which eliminates the need for a separate predictor. However, it faces key challenges: 1) Inaccurate bit-sliced sparsity speculation leads to incorrect pruning; 2) Hardware under-utilization due to fine-grained and imbalanced bit-level workloads. 3) Tiling difficulty caused by the row-wise dependency in sparsity pruning criteria. We propose PADE, a predictor-free algorithm-hardware co-design for dynamic sparse attention acceleration. PADE features three key innovations: 1) Bit-wise uncertainty interval-enabled guard filtering (BUI-GF) strategy to accurately identify trivial tokens during each bit round; 2) Bidirectional sparsity-based out-of-order execution (BS-OOE) to improve hardware utilization; 3) Interleaving-based sparsity-tiled attention (ISTA) to reduce both I/O and computational complexity. These techniques, combined with custom accelerator designs, enable practical sparsity acceleration without relying on an added sparsity predictor. Extensive experiments on 22 benchmarks show that PADE achieves 7.43x speed up and 31.1x higher energy efficiency than Nvidia H100 GPU. Compared to SOTA accelerators, PADE achieves 5.1x, 4.3x and 3.4x energy saving than Sanger, DOTA and SOFA.
WATOS: Efficient LLM Training Strategies and Architecture Co-exploration for Wafer-scale Chip
Dec 13, 2025Training large language models (LLMs) imposes extreme demands on computation, memory capacity, and interconnect bandwidth, driven by their ever-increasing parameter scales and intensive data movement. Wafer-scale integration offers a promising solution by densely integrating multiple single-die chips with high-speed die-to-die (D2D) interconnects. However, the limited wafer area necessitates trade-offs among compute, memory, and communication resources. Fully harnessing the potential of wafer-scale integration while mitigating its architectural constraints is essential for maximizing LLM training performance. This imposes significant challenges for the co-optimization of architecture and training strategies. Unfortunately, existing approaches all fall short in addressing these challenges. To bridge the gap, we propose WATOS, a co-exploration framework for LLM training strategy and wafer-scale architecture. We first define a highly configurable hardware template designed to explore optimal architectural parameters for wafer-scale chips. Based on it, we capitalize on the high D2D bandwidth and fine-grained operation advantages inherent to wafer-scale chips to explore optimal parallelism and resource allocation strategies, effectively addressing the memory underutilization issues during LLM training. Compared to the state-of-the-art (SOTA) LLM training framework Megatron and Cerebras' weight streaming wafer training strategy, WATOS can achieve an average overall throughput improvement of 2.74x and 1.53x across various LLM models, respectively. In addition, we leverage WATOS to reveal intriguing insights about wafer-scale architecture design with the training of LLM workloads.
MoBiLE: Efficient Mixture-of-Experts Inference on Consumer GPU with Mixture of Big Little Experts
Oct 14, 2025
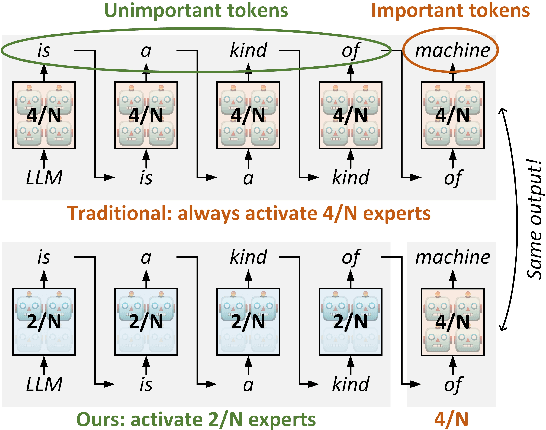


Mixture-of-Experts (MoE) models have recently demonstrated exceptional performance across a diverse range of applications. The principle of sparse activation in MoE models facilitates an offloading strategy, wherein active experts are maintained in GPU HBM, while inactive experts are stored in CPU DRAM. The efficacy of this approach, however, is fundamentally constrained by the limited bandwidth of the CPU-GPU interconnect. To mitigate this bottleneck, existing approaches have employed prefetching to accelerate MoE inference. These methods attempt to predict and prefetch the required experts using specially trained modules. Nevertheless, such techniques are often encumbered by significant training overhead and have shown diminished effectiveness on recent MoE models with fine-grained expert segmentation. In this paper, we propose MoBiLE, a plug-and-play offloading-based MoE inference framework with \textit{mixture of big-little experts}. It reduces the number of experts for unimportant tokens to half for acceleration while maintaining full experts for important tokens to guarantee model quality. Further, a dedicated fallback and prefetching mechanism is designed for switching between little and big experts to improve memory efficiency. We evaluate MoBiLE on four typical modern MoE architectures and challenging generative tasks. Our results show that MoBiLE achieves a speedup of 1.60x to 1.72x compared to the baseline on a consumer GPU system, with negligible degradation in accuracy.
HPCTransCompile: An AI Compiler Generated Dataset for High-Performance CUDA Transpilation and LLM Preliminary Exploration
Jun 12, 2025The rapid growth of deep learning has driven exponential increases in model parameters and computational demands. NVIDIA GPUs and their CUDA-based software ecosystem provide robust support for parallel computing, significantly alleviating computational bottlenecks. Meanwhile, due to the cultivation of user programming habits and the high performance of GPUs, the CUDA ecosystem has established a dominant position in the field of parallel software. This dominance requires other hardware platforms to support CUDA-based software with performance portability. However, translating CUDA code to other platforms poses significant challenges due to differences in parallel programming paradigms and hardware architectures. Existing approaches rely on language extensions, domain-specific languages (DSLs), or compilers but face limitations in workload coverage and generalizability. Moreover, these methods often incur substantial development costs. Recently, LLMs have demonstrated extraordinary potential in various vertical domains, especially in code-related tasks. However, the performance of existing LLMs in CUDA transpilation, particularly for high-performance code, remains suboptimal. The main reason for this limitation lies in the lack of high-quality training datasets. To address these challenges, we propose a novel framework for generating high-performance CUDA and corresponding platform code pairs, leveraging AI compiler and automatic optimization technology. We further enhance the framework with a graph-based data augmentation method and introduce HPCTransEval, a benchmark for evaluating LLM performance on CUDA transpilation. We conduct experiments using CUDA-to-CPU transpilation as a case study on leading LLMs. The result demonstrates that our framework significantly improves CUDA transpilation, highlighting the potential of LLMs to address compatibility challenges within the CUDA ecosystem.
Tackling the Dynamicity in a Production LLM Serving System with SOTA Optimizations via Hybrid Prefill/Decode/Verify Scheduling on Efficient Meta-kernels
Dec 24, 2024



Meeting growing demands for low latency and cost efficiency in production-grade large language model (LLM) serving systems requires integrating advanced optimization techniques. However, dynamic and unpredictable input-output lengths of LLM, compounded by these optimizations, exacerbate the issues of workload variability, making it difficult to maintain high efficiency on AI accelerators, especially DSAs with tile-based programming models. To address this challenge, we introduce XY-Serve, a versatile, Ascend native, end-to-end production LLM-serving system. The core idea is an abstraction mechanism that smooths out the workload variability by decomposing computations into unified, hardware-friendly, fine-grained meta primitives. For attention, we propose a meta-kernel that computes the basic pattern of matmul-softmax-matmul with architectural-aware tile sizes. For GEMM, we introduce a virtual padding scheme that adapts to dynamic shape changes while using highly efficient GEMM primitives with assorted fixed tile sizes. XY-Serve sits harmoniously with vLLM. Experimental results show up to 89% end-to-end throughput improvement compared with current publicly available baselines on Ascend NPUs. Additionally, our approach outperforms existing GEMM (average 14.6% faster) and attention (average 21.5% faster) kernels relative to existing libraries. While the work is Ascend native, we believe the approach can be readily applicable to SIMT architectures as well.
Catch-Up Distillation: You Only Need to Train Once for Accelerating Sampling
May 21, 2023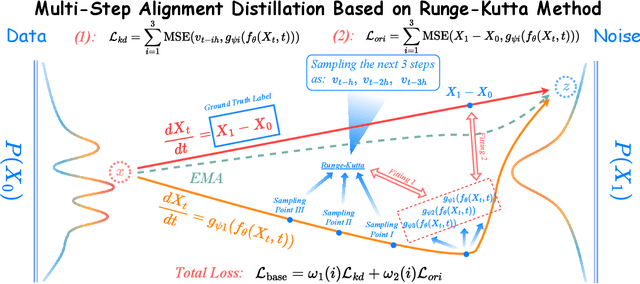


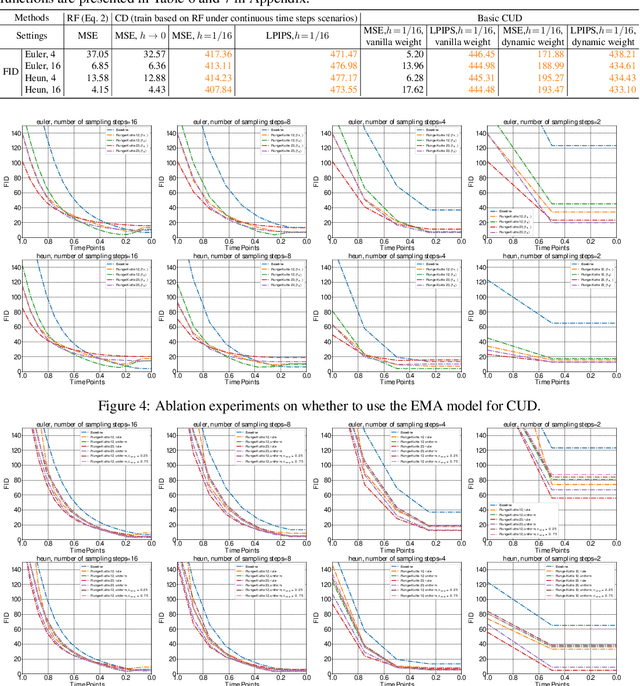
Diffusion Probability Models (DPMs) have made impressive advancements in various machine learning domains. However, achieving high-quality synthetic samples typically involves performing a large number of sampling steps, which impedes the possibility of real-time sample synthesis. Traditional accelerated sampling algorithms via knowledge distillation rely on pre-trained model weights and discrete time step scenarios, necessitating additional training sessions to achieve their goals. To address these issues, we propose the Catch-Up Distillation (CUD), which encourages the current moment output of the velocity estimation model ``catch up'' with its previous moment output. Specifically, CUD adjusts the original Ordinary Differential Equation (ODE) training objective to align the current moment output with both the ground truth label and the previous moment output, utilizing Runge-Kutta-based multi-step alignment distillation for precise ODE estimation while preventing asynchronous updates. Furthermore, we investigate the design space for CUDs under continuous time-step scenarios and analyze how to determine the suitable strategies. To demonstrate CUD's effectiveness, we conduct thorough ablation and comparison experiments on CIFAR-10, MNIST, and ImageNet-64. On CIFAR-10, we obtain a FID of 2.80 by sampling in 15 steps under one-session training and the new state-of-the-art FID of 3.37 by sampling in one step with additional training. This latter result necessitated only 62w iterations with a batch size of 128, in contrast to Consistency Distillation, which demanded 210w iterations with a larger batch size of 256. Our code is released at https://anonymous.4open.science/r/Catch-Up-Distillation-E31F.
FAQS: Communication-efficient Federate DNN Architecture and Quantization Co-Search for personalized Hardware-aware Preferences
Oct 16, 2022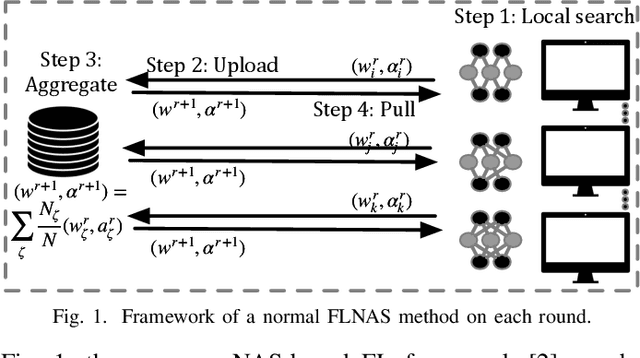
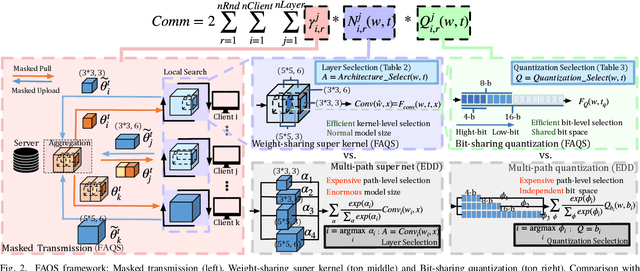
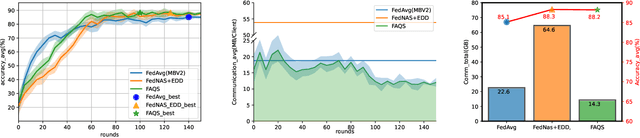
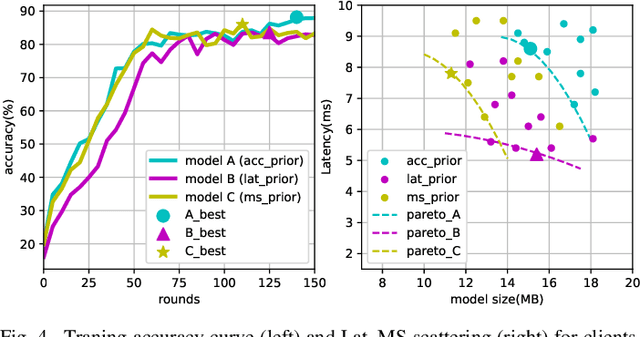
Due to user privacy and regulatory restrictions, federate learning (FL) is proposed as a distributed learning framework for training deep neural networks (DNN) on decentralized data clients. Recent advancements in FL have applied Neural Architecture Search (NAS) to replace the predefined one-size-fit-all DNN model, which is not optimal for all tasks of various data distributions, with searchable DNN architectures. However, previous methods suffer from expensive communication cost rasied by frequent large model parameters transmission between the server and clients. Such difficulty is further amplified when combining NAS algorithms, which commonly require prohibitive computation and enormous model storage. Towards this end, we propose FAQS, an efficient personalized FL-NAS-Quantization framework to reduce the communication cost with three features: weight-sharing super kernels, bit-sharing quantization and masked transmission. FAQS has an affordable search time and demands very limited size of transmitted messages at each round. By setting different personlized pareto function loss on local clients, FAQS can yield heterogeneous hardware-aware models for various user preferences. Experimental results show that FAQS achieves average reduction of 1.58x in communication bandwith per round compared with normal FL framework and 4.51x compared with FL+NAS framwork.
HQNAS: Auto CNN deployment framework for joint quantization and architecture search
Oct 16, 2022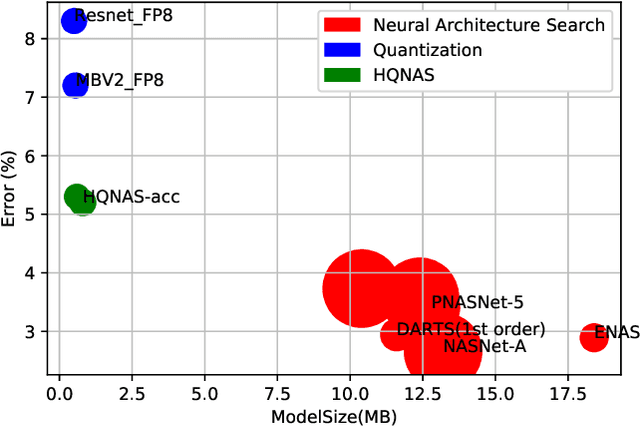
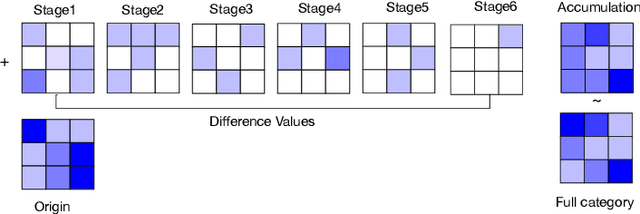
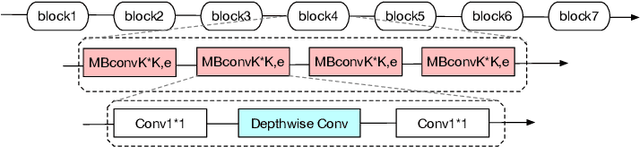
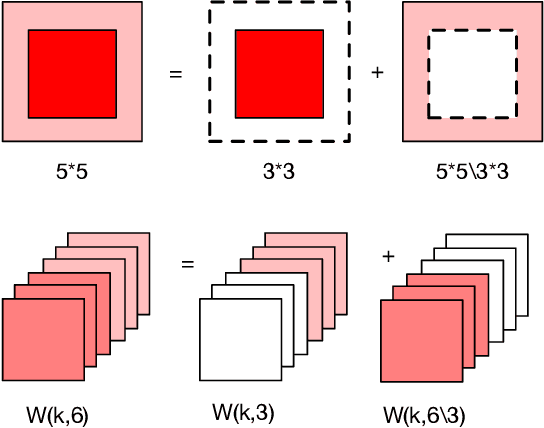
Deep learning applications are being transferred from the cloud to edge with the rapid development of embedded computing systems. In order to achieve higher energy efficiency with the limited resource budget, neural networks(NNs) must be carefully designed in two steps, the architecture design and the quantization policy choice. Neural Architecture Search(NAS) and Quantization have been proposed separately when deploying NNs onto embedded devices. However, taking the two steps individually is time-consuming and leads to a sub-optimal final deployment. To this end, we propose a novel neural network design framework called Hardware-aware Quantized Neural Architecture Search(HQNAS) framework which combines the NAS and Quantization together in a very efficient manner using weight-sharing and bit-sharing. It takes only 4 GPU hours to discover an outstanding NN policy on CIFAR10. It also takes only %10 GPU time to generate a comparable model on Imagenet compared to the traditional NAS method with 1.8x decrease of latency and a negligible accuracy loss of only 0.7%. Besides, our method can be adapted in a lifelong situation where the neural network needs to evolve occasionally due to changes of local data, environment and user preference.