 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Spatial Architectures for Sparse Attention: STAR Accelerator via Cross-Stage Tiling
Dec 24, 2025Large language models (LLMs) rely on self-attention for contextual understanding, demanding high-throughput inference and large-scale token parallelism (LTPP). Existing dynamic sparsity accelerators falter under LTPP scenarios due to stage-isolated optimizations. Revisiting the end-to-end sparsity acceleration flow, we identify an overlooked opportunity: cross-stage coordination can substantially reduce redundant computation and memory access. We propose STAR, a cross-stage compute- and memory-efficient algorithm-hardware co-design tailored for Transformer inference under LTPP. STAR introduces a leading-zero-based sparsity prediction using log-domain add-only operations to minimize prediction overhead. It further employs distributed sorting and a sorted updating FlashAttention mechanism, guided by a coordinated tiling strategy that enables fine-grained stage interaction for improved memory efficiency and latency. These optimizations are supported by a dedicated STAR accelerator architecture, achieving up to 9.2$\times$ speedup and 71.2$\times$ energy efficiency over A100, and surpassing SOTA accelerators by up to 16.1$\times$ energy and 27.1$\times$ area efficiency gains. Further, we deploy STAR onto a multi-core spatial architecture, optimizing dataflow and execution orchestration for ultra-long sequence processing. Architectural evaluation shows that, compared to the baseline design, Spatial-STAR achieves a 20.1$\times$ throughput improvement.
MoBiLE: Efficient Mixture-of-Experts Inference on Consumer GPU with Mixture of Big Little Experts
Oct 14, 2025
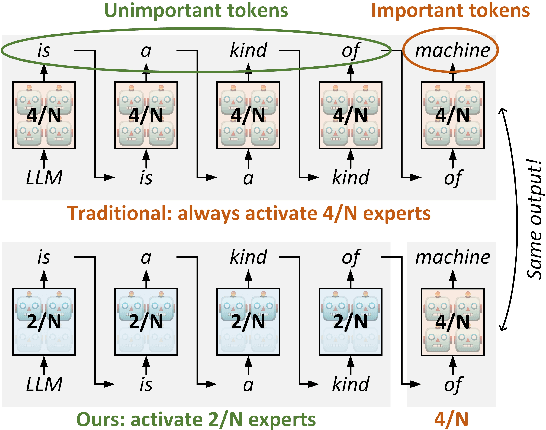


Mixture-of-Experts (MoE) models have recently demonstrated exceptional performance across a diverse range of applications. The principle of sparse activation in MoE models facilitates an offloading strategy, wherein active experts are maintained in GPU HBM, while inactive experts are stored in CPU DRAM. The efficacy of this approach, however, is fundamentally constrained by the limited bandwidth of the CPU-GPU interconnect. To mitigate this bottleneck, existing approaches have employed prefetching to accelerate MoE inference. These methods attempt to predict and prefetch the required experts using specially trained modules. Nevertheless, such techniques are often encumbered by significant training overhead and have shown diminished effectiveness on recent MoE models with fine-grained expert segmentation. In this paper, we propose MoBiLE, a plug-and-play offloading-based MoE inference framework with \textit{mixture of big-little experts}. It reduces the number of experts for unimportant tokens to half for acceleration while maintaining full experts for important tokens to guarantee model quality. Further, a dedicated fallback and prefetching mechanism is designed for switching between little and big experts to improve memory efficiency. We evaluate MoBiLE on four typical modern MoE architectures and challenging generative tasks. Our results show that MoBiLE achieves a speedup of 1.60x to 1.72x compared to the baseline on a consumer GPU system, with negligible degradation in accuracy.
FAQS: Communication-efficient Federate DNN Architecture and Quantization Co-Search for personalized Hardware-aware Preferences
Oct 16, 2022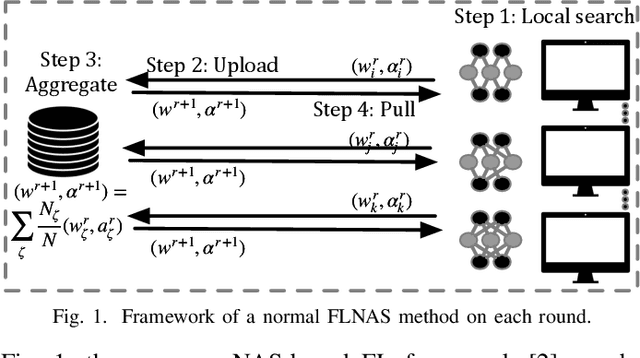
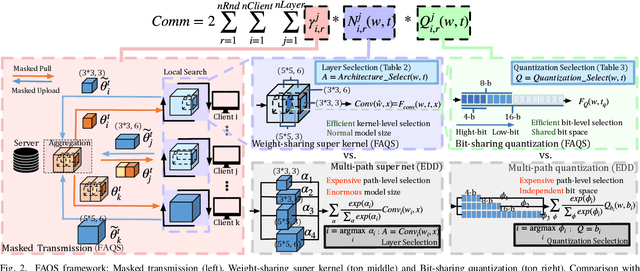
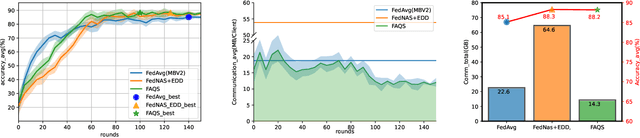
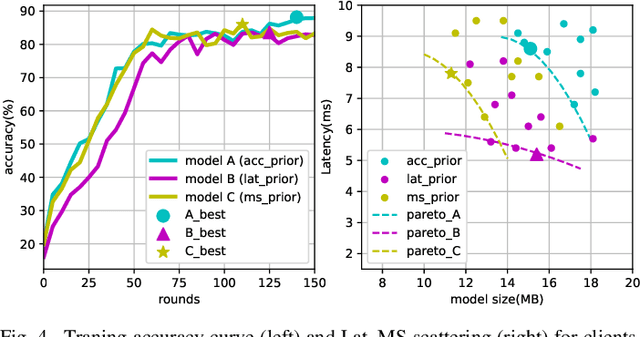
Due to user privacy and regulatory restrictions, federate learning (FL) is proposed as a distributed learning framework for training deep neural networks (DNN) on decentralized data clients. Recent advancements in FL have applied Neural Architecture Search (NAS) to replace the predefined one-size-fit-all DNN model, which is not optimal for all tasks of various data distributions, with searchable DNN architectures. However, previous methods suffer from expensive communication cost rasied by frequent large model parameters transmission between the server and clients. Such difficulty is further amplified when combining NAS algorithms, which commonly require prohibitive computation and enormous model storage. Towards this end, we propose FAQS, an efficient personalized FL-NAS-Quantization framework to reduce the communication cost with three features: weight-sharing super kernels, bit-sharing quantization and masked transmission. FAQS has an affordable search time and demands very limited size of transmitted messages at each round. By setting different personlized pareto function loss on local clients, FAQS can yield heterogeneous hardware-aware models for various user preferences. Experimental results show that FAQS achieves average reduction of 1.58x in communication bandwith per round compared with normal FL framework and 4.51x compared with FL+NAS framwork.
HQNAS: Auto CNN deployment framework for joint quantization and architecture search
Oct 16, 2022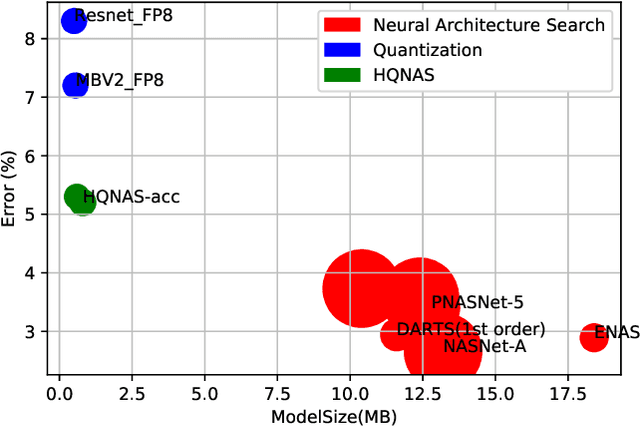
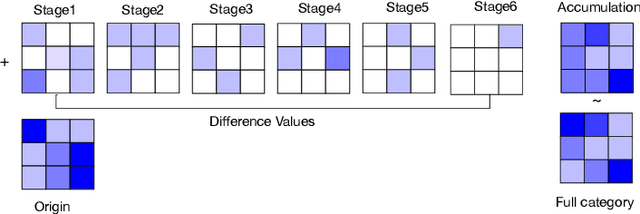
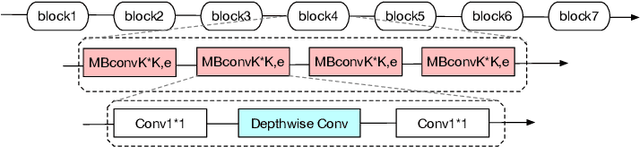
Deep learning applications are being transferred from the cloud to edge with the rapid development of embedded computing systems. In order to achieve higher energy efficiency with the limited resource budget, neural networks(NNs) must be carefully designed in two steps, the architecture design and the quantization policy choice. Neural Architecture Search(NAS) and Quantization have been proposed separately when deploying NNs onto embedded devices. However, taking the two steps individually is time-consuming and leads to a sub-optimal final deployment. To this end, we propose a novel neural network design framework called Hardware-aware Quantized Neural Architecture Search(HQNAS) framework which combines the NAS and Quantization together in a very efficient manner using weight-sharing and bit-sharing. It takes only 4 GPU hours to discover an outstanding NN policy on CIFAR10. It also takes only %10 GPU time to generate a comparable model on Imagenet compared to the traditional NAS method with 1.8x decrease of latency and a negligible accuracy loss of only 0.7%. Besides, our method can be adapted in a lifelong situation where the neural network needs to evolve occasionally due to changes of local data, environment and user preference.
Small-footprint Keyword Spotting with Graph Convolutional Network
Dec 11, 2019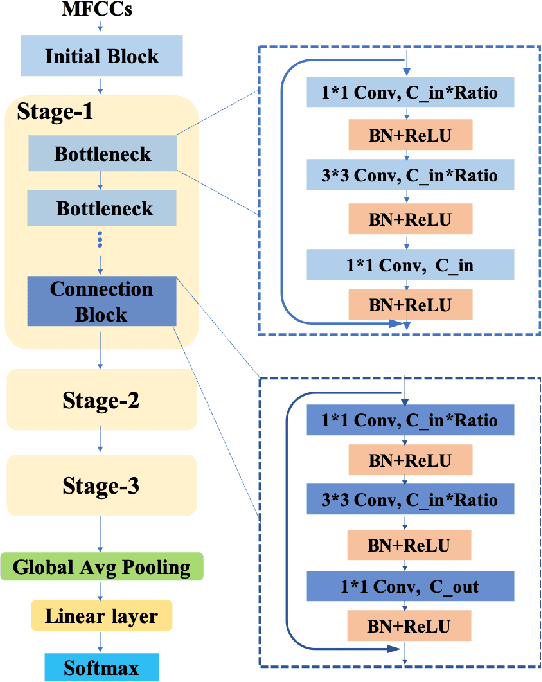

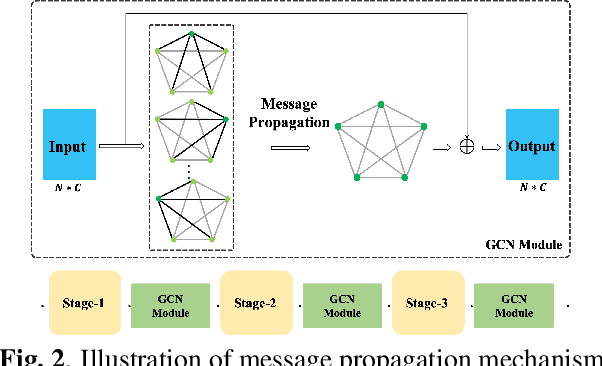
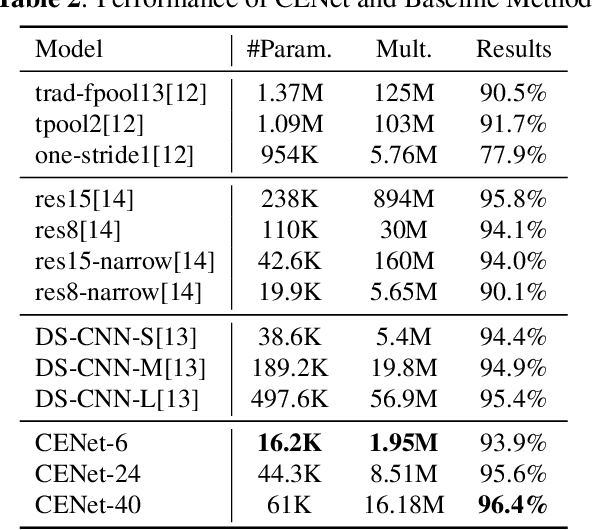
Despite the recent successes of deep neural networks, it remains challenging to achieve high precision keyword spotting task (KWS) on resource-constrained devices. In this study, we propose a novel context-aware and compact architecture for keyword spotting task. Based on residual connection and bottleneck structure, we design a compact and efficient network for KWS task. To leverage the long range dependencies and global context of the convolutional feature maps, the graph convolutional network is introduced to encode the non-local relations. By evaluated on the Google Speech Command Dataset, the proposed method achieves state-of-the-art performance and outperforms the prior works by a large margin with lower computational cost.