 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation
Feb 13, 2025Code generation has attracted increasing attention with the rise of Large Language Models (LLMs). Many studies have developed powerful code LLMs by synthesizing code-related instruction data and applying supervised fine-tuning. However, these methods are limited by teacher model distillation and ignore the potential of iterative refinement by self-generated code. In this paper, we propose Adaptive Critique Refinement (ACR), which enables the model to refine itself by self-generated code and external critique, rather than directly imitating the code responses of the teacher model. Concretely, ACR includes a composite scoring system with LLM-as-a-Judge to evaluate the quality of code responses and a selective critique strategy with LLM-as-a-Critic to critique self-generated low-quality code responses. We develop the RefineCoder series by iteratively applying ACR, achieving continuous performance improvement on multiple code generation benchmarks. Compared to the baselines of the same size, our proposed RefineCoder series can achieve comparable or even superior performance using less data.
Laser: Parameter-Efficient LLM Bi-Tuning for Sequential Recommendation with Collaborative Information
Sep 03, 2024



Sequential recommender systems are essential for discerning user preferences from historical interactions and facilitating targeted recommendations. Recent innovations employing Large Language Models (LLMs) have advanced the field by encoding item semantics, yet they often necessitate substantial parameter tuning and are resource-demanding. Moreover, these works fails to consider the diverse characteristics of different types of users and thus diminishes the recommendation accuracy. In this paper, we propose a parameter-efficient Large Language Model Bi-Tuning framework for sequential recommendation with collaborative information (Laser). Specifically, Bi-Tuning works by inserting trainable virtual tokens at both the prefix and suffix of the input sequence and freezing the LLM parameters, thus optimizing the LLM for the sequential recommendation. In our Laser, the prefix is utilized to incorporate user-item collaborative information and adapt the LLM to the recommendation task, while the suffix converts the output embeddings of the LLM from the language space to the recommendation space for the follow-up item recommendation. Furthermore, to capture the characteristics of different types of users when integrating the collaborative information via the prefix, we introduce M-Former, a lightweight MoE-based querying transformer that uses a set of query experts to integrate diverse user-specific collaborative information encoded by frozen ID-based sequential recommender systems, significantly improving the accuracy of recommendations. Extensive experiments on real-world datasets demonstrate that Laser can parameter-efficiently adapt LLMs to effective recommender systems, significantly outperforming state-of-the-art methods.
Dialogue State Distillation Network with Inter-Slot Contrastive Learning for Dialogue State Tracking
Feb 16, 2023



In task-oriented dialogue systems, Dialogue State Tracking (DST) aims to extract users' intentions from the dialogue history. Currently, most existing approaches suffer from error propagation and are unable to dynamically select relevant information when utilizing previous dialogue states. Moreover, the relations between the updates of different slots provide vital clues for DST. However, the existing approaches rely only on predefined graphs to indirectly capture the relations. In this paper, we propose a Dialogue State Distillation Network (DSDN) to utilize relevant information of previous dialogue states and migrate the gap of utilization between training and testing. Thus, it can dynamically exploit previous dialogue states and avoid introducing error propagation simultaneously. Further, we propose an inter-slot contrastive learning loss to effectively capture the slot co-update relations from dialogue context. Experiments are conducted on the widely used MultiWOZ 2.0 and MultiWOZ 2.1 datasets. The experimental results show that our proposed model achieves the state-of-the-art performance for DST.
A Multi-turn Machine Reading Comprehension Framework with Rethink Mechanism for Emotion-Cause Pair Extraction
Sep 16, 2022

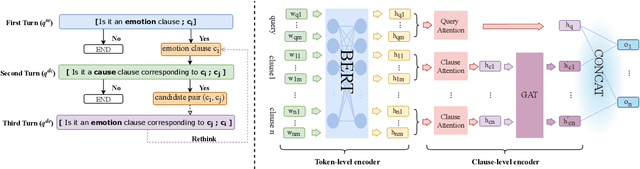

Emotion-cause pair extraction (ECPE) is an emerging task in emotion cause analysis, which extracts potential emotion-cause pairs from an emotional document. Most recent studies use end-to-end methods to tackle the ECPE task. However, these methods either suffer from a label sparsity problem or fail to model complicated relations between emotions and causes. Furthermore, they all do not consider explicit semantic information of clauses. To this end, we transform the ECPE task into a document-level machine reading comprehension (MRC) task and propose a Multi-turn MRC framework with Rethink mechanism (MM-R). Our framework can model complicated relations between emotions and causes while avoiding generating the pairing matrix (the leading cause of the label sparsity problem). Besides, the multi-turn structure can fuse explicit semantic information flow between emotions and causes. Extensive experiments on the benchmark emotion cause corpus demonstrate the effectiveness of our proposed framework, which outperforms existing state-of-the-art methods.
Hierarchical Image Classification with A Literally Toy Dataset
Nov 01, 2021
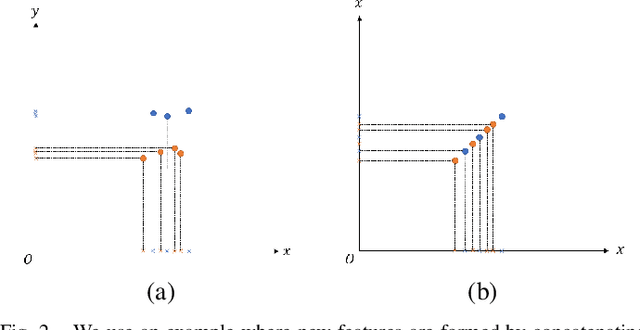
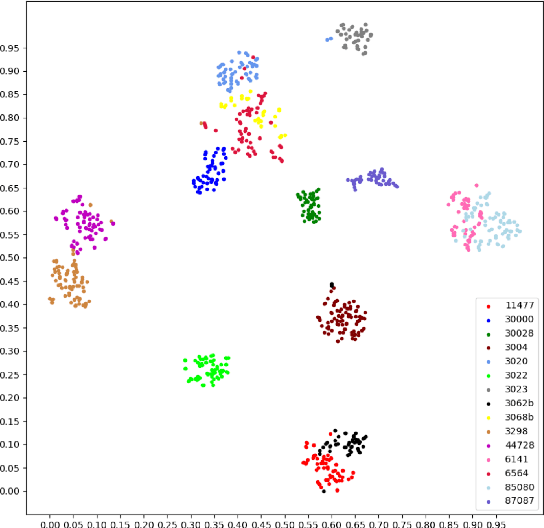
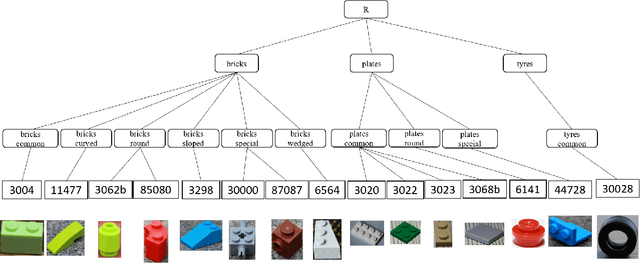
Unsupervised domain adaptation (UDA) in image classification remains a big challenge. In existing UDA image dataset, classes are usually organized in a flattened way, where a plain classifier can be trained. Yet in some scenarios, the flat categories originate from some base classes. For example, buggies belong to the class bird. We define the classification task where classes have characteristics above and the flat classes and the base classes are organized hierarchically as hierarchical image classification. Intuitively, leveraging such hierarchical structure will benefit hierarchical image classification, e.g., two easily confusing classes may belong to entirely different base classes. In this paper, we improve the performance of classification by fusing features learned from a hierarchy of labels. Specifically, we train feature extractors supervised by hierarchical labels and with UDA technology, which will output multiple features for an input image. The features are subsequently concatenated to predict the finest-grained class. This study is conducted with a new dataset named Lego-15. Consisting of synthetic images and real images of the Lego bricks, the Lego-15 dataset contains 15 classes of bricks. Each class originates from a coarse-level label and a middle-level label. For example, class "85080" is associated with bricks (coarse) and bricks round (middle). In this dataset, we demonstrate that our method brings about consistent improvement over the baseline in UDA in hierarchical image classification. Extensive ablation and variant studies provide insights into the new dataset and the investigated algorithm.
Dynamic Multi-scale Convolution for Dialect Identification
Aug 02, 2021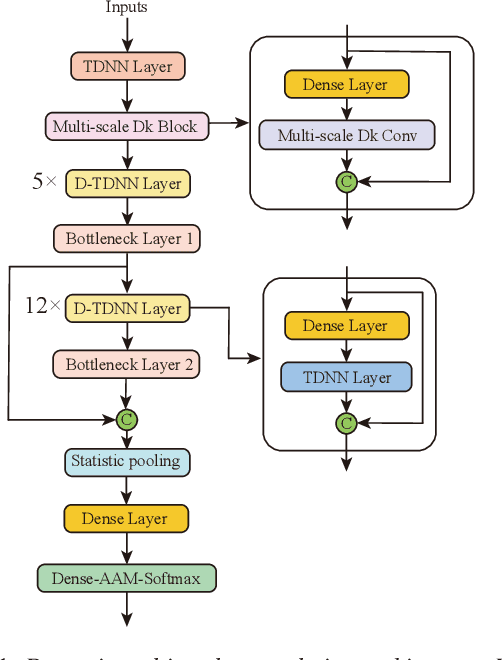

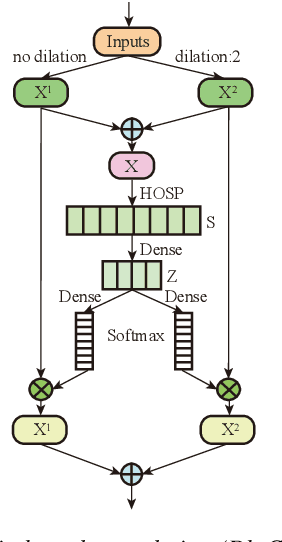

Time Delay Neural Networks (TDNN)-based methods are widely used in dialect identification. However, in previous work with TDNN application, subtle variant is being neglected in different feature scales. To address this issue, we propose a new architecture, named dynamic multi-scale convolution, which consists of dynamic kernel convolution, local multi-scale learning, and global multi-scale pooling. Dynamic kernel convolution captures features between short-term and long-term context adaptively. Local multi-scale learning, which represents multi-scale features at a granular level, is able to increase the range of receptive fields for convolution operation. Besides, global multi-scale pooling is applied to aggregate features from different bottleneck layers in order to collect information from multiple aspects. The proposed architecture significantly outperforms state-of-the-art system on the AP20-OLR-dialect-task of oriental language recognition (OLR) challenge 2020, with the best average cost performance (Cavg) of 0.067 and the best equal error rate (EER) of 6.52%. Compared with the known best results, our method achieves 9% of Cavg and 45% of EER relative improvement, respectively. Furthermore, the parameters of proposed model are 91% fewer than the best known model.
KVL-BERT: Knowledge Enhanced Visual-and-Linguistic BERT for Visual Commonsense Reasoning
Dec 13, 2020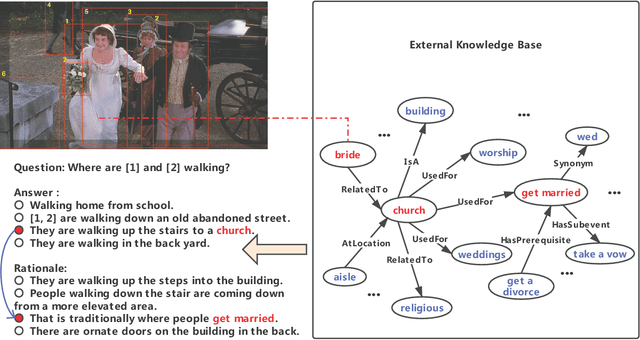


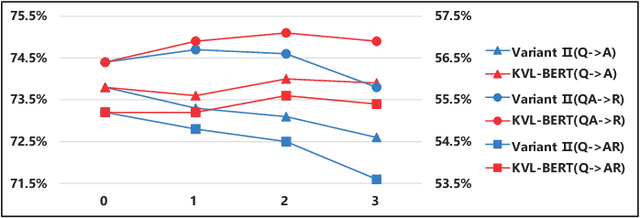
Reasoning is a critical ability towards complete visual understanding. To develop machine with cognition-level visual understanding and reasoning abilities, the visual commonsense reasoning (VCR) task has been introduced. In VCR, given a challenging question about an image, a machine must answer correctly and then provide a rationale justifying its answer. The methods adopting the powerful BERT model as the backbone for learning joint representation of image content and natural language have shown promising improvements on VCR. However, none of the existing methods have utilized commonsense knowledge in visual commonsense reasoning, which we believe will be greatly helpful in this task. With the support of commonsense knowledge, complex questions even if the required information is not depicted in the image can be answered with cognitive reasoning. Therefore, we incorporate commonsense knowledge into the cross-modal BERT, and propose a novel Knowledge Enhanced Visual-and-Linguistic BERT (KVL-BERT for short) model. Besides taking visual and linguistic contents as input, external commonsense knowledge extracted from ConceptNet is integrated into the multi-layer Transformer. In order to reserve the structural information and semantic representation of the original sentence, we propose using relative position embedding and mask-self-attention to weaken the effect between the injected commonsense knowledge and other unrelated components in the input sequence. Compared to other task-specific models and general task-agnostic pre-training models, our KVL-BERT outperforms them by a large margin.
Transformer with Bidirectional Decoder for Speech Recognition
Aug 11, 2020Attention-based models have made tremendous progress on end-to-end automatic speech recognition(ASR) recently. However, the conventional transformer-based approaches usually generate the sequence results token by token from left to right, leaving the right-to-left contexts unexploited. In this work, we introduce a bidirectional speech transformer to utilize the different directional contexts simultaneously. Specifically, the outputs of our proposed transformer include a left-to-right target, and a right-to-left target. In inference stage, we use the introduced bidirectional beam search method, which can not only generate left-to-right candidates but also generate right-to-left candidates, and determine the best hypothesis by the score. To demonstrate our proposed speech transformer with a bidirectional decoder(STBD), we conduct extensive experiments on the AISHELL-1 dataset. The results of experiments show that STBD achieves a 3.6\% relative CER reduction(CERR) over the unidirectional speech transformer baseline. Besides, the strongest model in this paper called STBD-Big can achieve 6.64\% CER on the test set, without language model rescoring and any extra data augmentation strategies.
Small-footprint Keyword Spotting with Graph Convolutional Network
Dec 11, 2019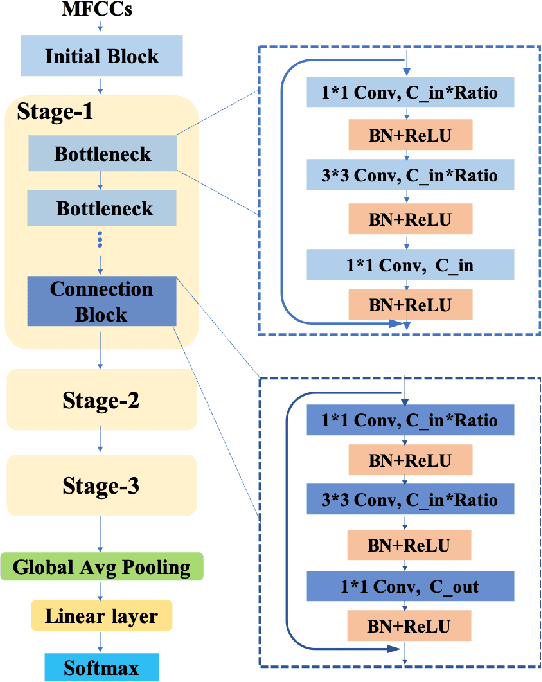

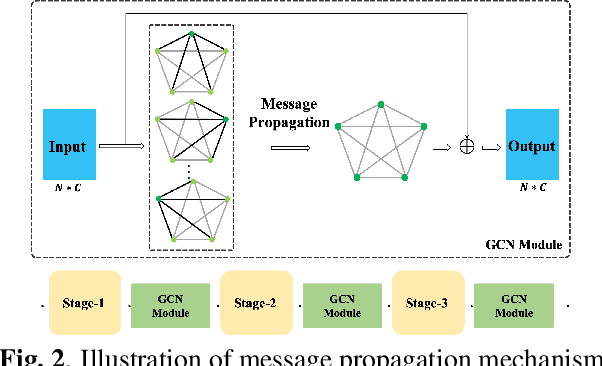
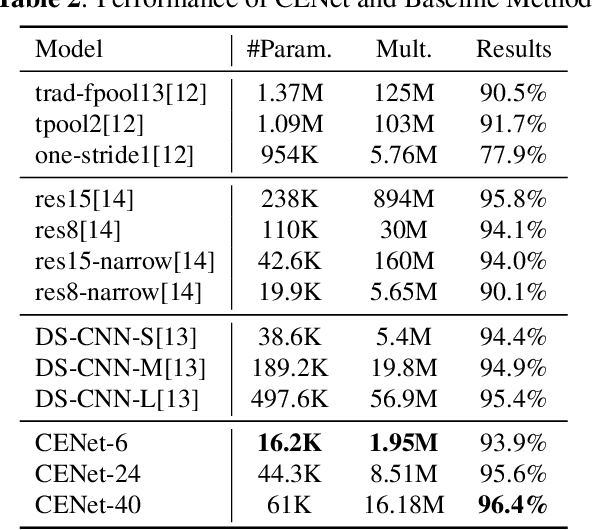
Despite the recent successes of deep neural networks, it remains challenging to achieve high precision keyword spotting task (KWS) on resource-constrained devices. In this study, we propose a novel context-aware and compact architecture for keyword spotting task. Based on residual connection and bottleneck structure, we design a compact and efficient network for KWS task. To leverage the long range dependencies and global context of the convolutional feature maps, the graph convolutional network is introduced to encode the non-local relations. By evaluated on the Google Speech Command Dataset, the proposed method achieves state-of-the-art performance and outperforms the prior works by a large margin with lower computational cost.