 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKirchhoff-Inspired Neural Networks for Evolving High-Order Perception
Mar 25, 2026Deep learning architectures are fundamentally inspired by neuroscience, particularly the structure of the brain's sensory pathways, and have achieved remarkable success in learning informative data representations. Although these architectures mimic the communication mechanisms of biological neurons, their strategies for information encoding and transmission are fundamentally distinct. Biological systems depend on dynamic fluctuations in membrane potential; by contrast, conventional deep networks optimize weights and biases by adjusting the strengths of inter-neural connections, lacking a systematic mechanism to jointly characterize the interplay among signal intensity, coupling structure, and state evolution. To tackle this limitation, we propose the Kirchhoff-Inspired Neural Network (KINN), a state-variable-based network architecture constructed based on Kirchhoff's current law. KINN derives numerically stable state updates from fundamental ordinary differential equations, enabling the explicit decoupling and encoding of higher-order evolutionary components within a single layer while preserving physical consistency, interpretability, and end-to-end trainability. Extensive experiments on partial differential equation (PDE) solving and ImageNet image classification validate that KINN outperforms state-of-the-art existing methods.
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Mar 23, 2026Dexterous manipulation remains challenging due to the cost of collecting real-robot teleoperation data, the heterogeneity of hand embodiments, and the high dimensionality of control. We present UniDex, a robot foundation suite that couples a large-scale robot-centric dataset with a unified vision-language-action (VLA) policy and a practical human-data capture setup for universal dexterous hand control. First, we construct UniDex-Dataset, a robot-centric dataset over 50K trajectories across eight dexterous hands (6--24 DoFs), derived from egocentric human video datasets. To transform human data into robot-executable trajectories, we employ a human-in-the-loop retargeting procedure to align fingertip trajectories while preserving plausible hand-object contacts, and we operate on explicit 3D pointclouds with human hands masked to narrow kinematic and visual gaps. Second, we introduce the Function-Actuator-Aligned Space (FAAS), a unified action space that maps functionally similar actuators to shared coordinates, enabling cross-hand transfer. Leveraging FAAS as the action parameterization, we train UniDex-VLA, a 3D VLA policy pretrained on UniDex-Dataset and finetuned with task demonstrations. In addition, we build UniDex-Cap, a simple portable capture setup that records synchronized RGB-D streams and human hand poses and converts them into robot-executable trajectories to enable human-robot data co-training that reduces reliance on costly robot demonstrations. On challenging tool-use tasks across two different hands, UniDex-VLA achieves 81% average task progress and outperforms prior VLA baselines by a large margin, while exhibiting strong spatial, object, and zero-shot cross-hand generalization. Together, UniDex-Dataset, UniDex-VLA, and UniDex-Cap provide a scalable foundation suite for universal dexterous manipulation.
JC5A: Service Delay Minimization for Aerial MEC-assisted Industrial Cyber-Physical Systems
Nov 07, 2024



In the era of the sixth generation (6G) and industrial Internet of Things (IIoT), an industrial cyber-physical system (ICPS) drives the proliferation of sensor devices and computing-intensive tasks. To address the limited resources of IIoT sensor devices, unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) has emerged as a promising solution, providing flexible and cost-effective services in close proximity of IIoT sensor devices (ISDs). However, leveraging aerial MEC to meet the delay-sensitive and computation-intensive requirements of the ISDs could face several challenges, including the limited communication, computation and caching (3C) resources, stringent offloading requirements for 3C services, and constrained on-board energy of UAVs. To address these issues, we first present a collaborative aerial MEC-assisted ICPS architecture by incorporating the computing capabilities of the macro base station (MBS) and UAVs. We then formulate a service delay minimization optimization problem (SDMOP). Since the SDMOP is proved to be an NP-hard problem, we propose a joint computation offloading, caching, communication resource allocation, computation resource allocation, and UAV trajectory control approach (JC5A). Specifically, JC5A consists of a block successive upper bound minimization method of multipliers (BSUMM) for computation offloading and service caching, a convex optimization-based method for communication and computation resource allocation, and a successive convex approximation (SCA)-based method for UAV trajectory control. Moreover, we theoretically prove the convergence and polynomial complexity of JC5A. Simulation results demonstrate that the proposed approach can achieve superior system performance compared to the benchmark approaches and algorithms.
REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models
Feb 10, 2024The integration of multimodal Electronic Health Records (EHR) data has significantly improved clinical predictive capabilities. Leveraging clinical notes and multivariate time-series EHR, existing models often lack the medical context relevent to clinical tasks, prompting the incorporation of external knowledge, particularly from the knowledge graph (KG). Previous approaches with KG knowledge have primarily focused on structured knowledge extraction, neglecting unstructured data modalities and semantic high dimensional medical knowledge. In response, we propose REALM, a Retrieval-Augmented Generation (RAG) driven framework to enhance multimodal EHR representations that address these limitations. Firstly, we apply Large Language Model (LLM) to encode long context clinical notes and GRU model to encode time-series EHR data. Secondly, we prompt LLM to extract task-relevant medical entities and match entities in professionally labeled external knowledge graph (PrimeKG) with corresponding medical knowledge. By matching and aligning with clinical standards, our framework eliminates hallucinations and ensures consistency. Lastly, we propose an adaptive multimodal fusion network to integrate extracted knowledge with multimodal EHR data. Our extensive experiments on MIMIC-III mortality and readmission tasks showcase the superior performance of our REALM framework over baselines, emphasizing the effectiveness of each module. REALM framework contributes to refining the use of multimodal EHR data in healthcare and bridging the gap with nuanced medical context essential for informed clinical predictions.
Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
Sep 17, 2023
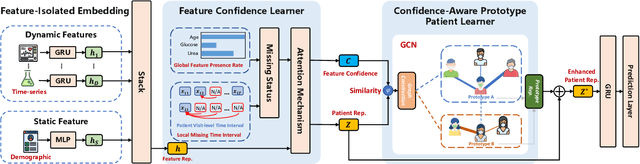
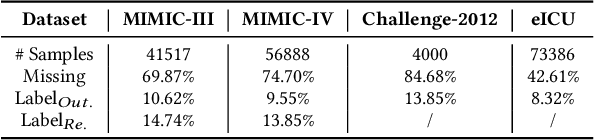
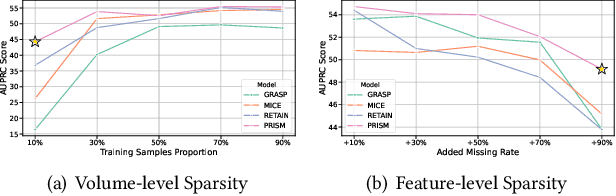
Electronic Health Record (EHR) data frequently exhibits sparse characteristics, posing challenges for predictive modeling. Current direct imputation such as matrix imputation approaches hinge on referencing analogous rows or columns to complete raw missing data and do not differentiate between imputed and actual values. As a result, models may inadvertently incorporate irrelevant or deceptive information with respect to the prediction objective, thereby compromising the efficacy of downstream performance. While some methods strive to recalibrate or augment EHR embeddings after direct imputation, they often mistakenly prioritize imputed features. This misprioritization can introduce biases or inaccuracies into the model. To tackle these issues, our work resorts to indirect imputation, where we leverage prototype representations from similar patients to obtain a denser embedding. Recognizing the limitation that missing features are typically treated the same as present ones when measuring similar patients, our approach designs a feature confidence learner module. This module is sensitive to the missing feature status, enabling the model to better judge the reliability of each feature. Moreover, we propose a novel patient similarity metric that takes feature confidence into account, ensuring that evaluations are not based merely on potentially inaccurate imputed values. Consequently, our work captures dense prototype patient representations with feature-missing-aware calibration process. Comprehensive experiments demonstrate that designed model surpasses established EHR-focused models with a statistically significant improvement on MIMIC-III and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code is publicly available at \url{https://github.com/yhzhu99/SparseEHR} to assure the reproducibility.
Prescriptive PCA: Dimensionality Reduction for Two-stage Stochastic Optimization
Jun 04, 2023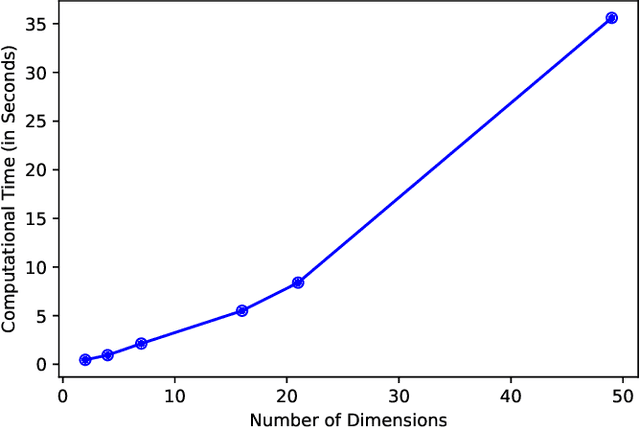
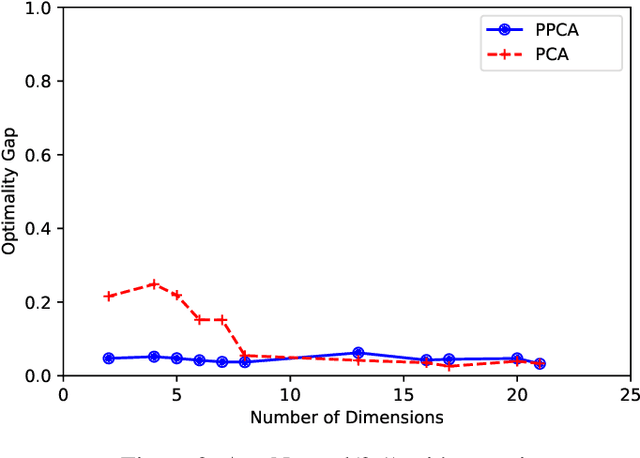
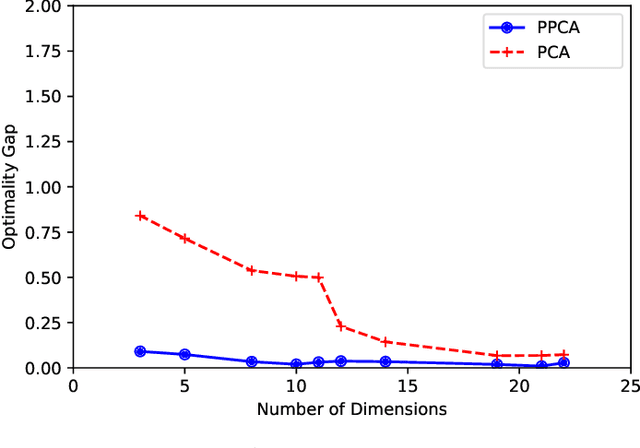
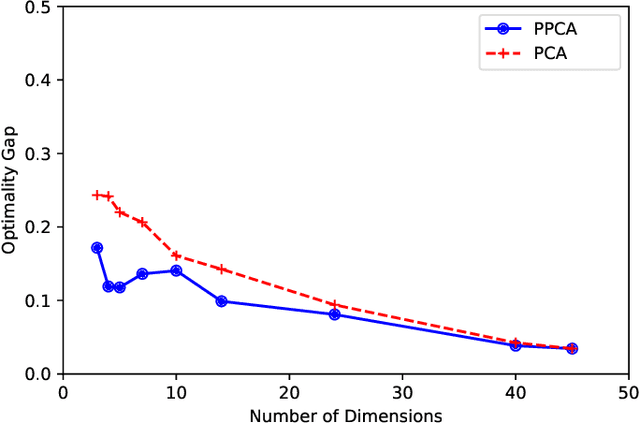
In this paper, we consider the alignment between an upstream dimensionality reduction task of learning a low-dimensional representation of a set of high-dimensional data and a downstream optimization task of solving a stochastic program parameterized by said representation. In this case, standard dimensionality reduction methods (e.g., principal component analysis) may not perform well, as they aim to maximize the amount of information retained in the representation and do not generally reflect the importance of such information in the downstream optimization problem. To address this problem, we develop a prescriptive dimensionality reduction framework that aims to minimize the degree of suboptimality in the optimization phase. For the case where the downstream stochastic optimization problem has an expected value objective, we show that prescriptive dimensionality reduction can be performed via solving a distributionally-robust optimization problem, which admits a semidefinite programming relaxation. Computational experiments based on a warehouse transshipment problem and a vehicle repositioning problem show that our approach significantly outperforms principal component analysis with real and synthetic data sets.
Hierarchical Image Classification with A Literally Toy Dataset
Nov 01, 2021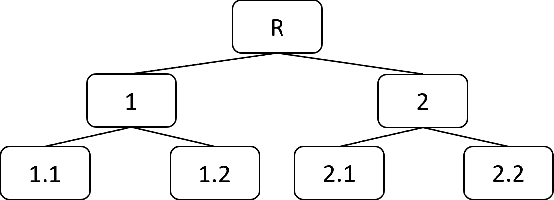
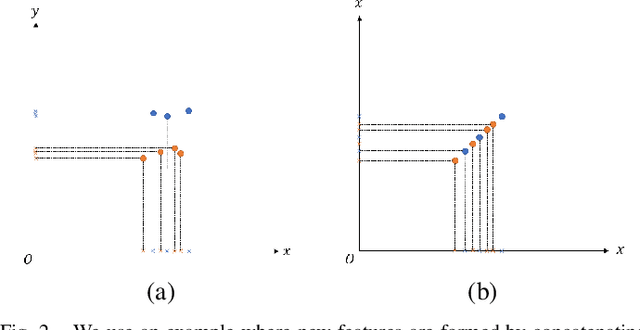
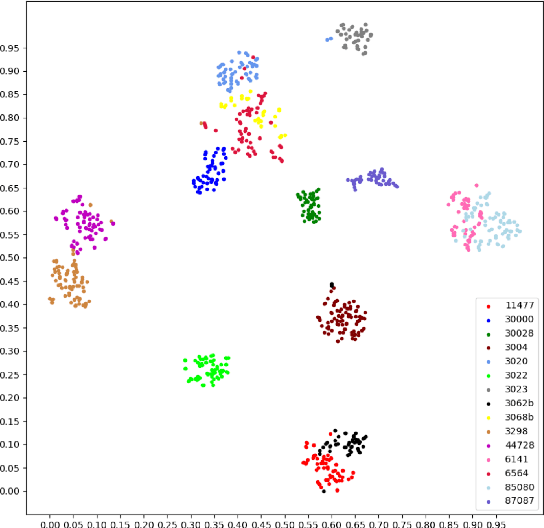
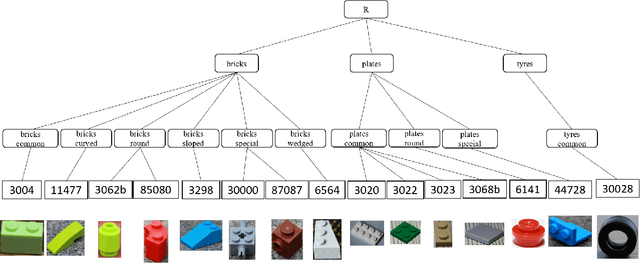
Unsupervised domain adaptation (UDA) in image classification remains a big challenge. In existing UDA image dataset, classes are usually organized in a flattened way, where a plain classifier can be trained. Yet in some scenarios, the flat categories originate from some base classes. For example, buggies belong to the class bird. We define the classification task where classes have characteristics above and the flat classes and the base classes are organized hierarchically as hierarchical image classification. Intuitively, leveraging such hierarchical structure will benefit hierarchical image classification, e.g., two easily confusing classes may belong to entirely different base classes. In this paper, we improve the performance of classification by fusing features learned from a hierarchy of labels. Specifically, we train feature extractors supervised by hierarchical labels and with UDA technology, which will output multiple features for an input image. The features are subsequently concatenated to predict the finest-grained class. This study is conducted with a new dataset named Lego-15. Consisting of synthetic images and real images of the Lego bricks, the Lego-15 dataset contains 15 classes of bricks. Each class originates from a coarse-level label and a middle-level label. For example, class "85080" is associated with bricks (coarse) and bricks round (middle). In this dataset, we demonstrate that our method brings about consistent improvement over the baseline in UDA in hierarchical image classification. Extensive ablation and variant studies provide insights into the new dataset and the investigated algorithm.
Physics-guided Design and Learning of Neural Networks for Predicting Drag Force on Particle Suspensions in Moving Fluids
Nov 06, 2019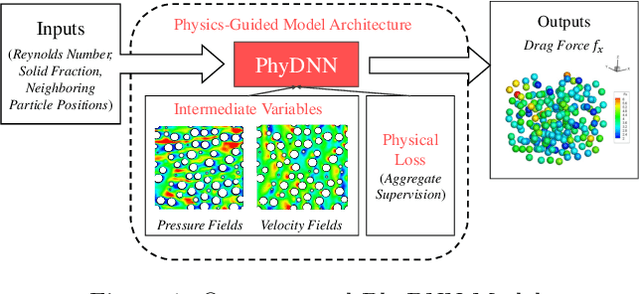

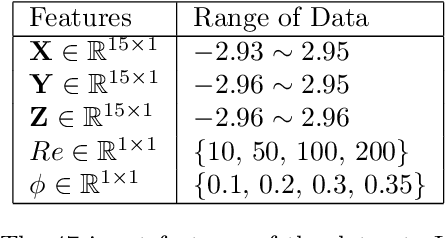
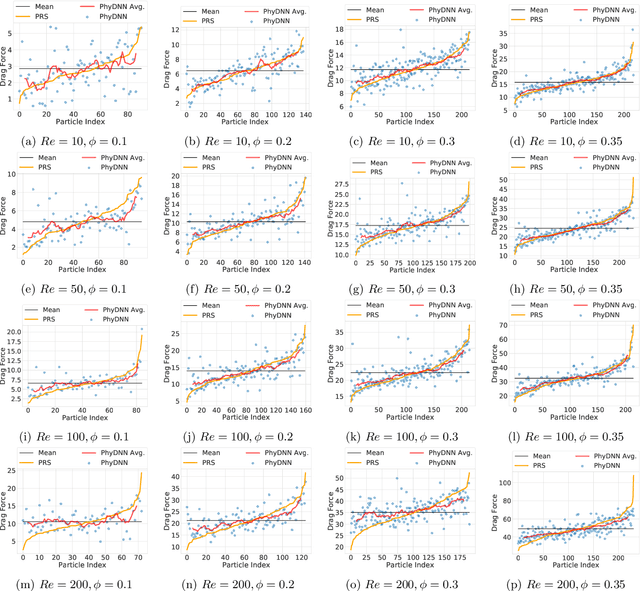
Physics-based simulations are often used to model and understand complex physical systems and processes in domains like fluid dynamics. Such simulations, although used frequently, have many limitations which could arise either due to the inability to accurately model a physical process owing to incomplete knowledge about certain facets of the process or due to the underlying process being too complex to accurately encode into a simulation model. In such situations, it is often useful to rely on machine learning methods to fill in the gap by learning a model of the complex physical process directly from simulation data. However, as data generation through simulations is costly, we need to develop models, being cognizant of data paucity issues. In such scenarios it is often helpful if the rich physical knowledge of the application domain is incorporated in the architectural design of machine learning models. Further, we can also use information from physics-based simulations to guide the learning process using aggregate supervision to favorably constrain the learning process. In this paper, we propose PhyDNN, a deep learning model using physics-guided structural priors and physics-guided aggregate supervision for modeling the drag forces acting on each particle in a Computational Fluid Dynamics-Discrete Element Method(CFD-DEM). We conduct extensive experiments in the context of drag force prediction and showcase the usefulness of including physics knowledge in our deep learning formulation both in the design and through learning process. Our proposed PhyDNN model has been compared to several state-of-the-art models and achieves a significant performance improvement of 8.46% on average across all baseline models. The source code has been made available and the dataset used is detailed in [1, 2].