 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphWalker: Graph-Guided In-Context Learning for Clinical Reasoning on Electronic Health Records
Apr 08, 2026Clinical Reasoning on Electronic Health Records (EHRs) is a fundamental yet challenging task in modern healthcare. While in-context learning (ICL) offers a promising inference-time adaptation paradigm for large language models (LLMs) in EHR reasoning, existing methods face three fundamental challenges: (1) Perspective Limitation, where data-driven similarity fails to align with LLM reasoning needs and model-driven signals are constrained by limited clinical competence; (2) Cohort Awareness, as demonstrations are selected independently without modeling population-level structure; and (3) Information Aggregation, where redundancy and interaction effects among demonstrations are ignored, leading to diminishing marginal gains. To address these challenges, we propose GraphWalker, a principled demonstration selection framework for EHR-oriented ICL. GraphWalker (i) jointly models patient clinical information and LLM-estimated information gain by integrating data-driven and model-driven perspectives, (ii) incorporates Cohort Discovery to avoid noisy local optima, and (iii) employs a Lazy Greedy Search with Frontier Expansion algorithm to mitigate diminishing marginal returns in information aggregation. Extensive experiments on multiple real-world EHR benchmarks demonstrate that GraphWalker consistently outperforms state-of-the-art ICL baselines, yielding substantial improvements in clinical reasoning performance. Our code is open-sourced at https://github.com/PuppyKnightUniversity/GraphWalker
Augmenting Clinical Decision-Making with an Interactive and Interpretable AI Copilot: A Real-World User Study with Clinicians in Nephrology and Obstetrics
Jan 31, 2026Clinician skepticism toward opaque AI hinders adoption in high-stakes healthcare. We present AICare, an interactive and interpretable AI copilot for collaborative clinical decision-making. By analyzing longitudinal electronic health records, AICare grounds dynamic risk predictions in scrutable visualizations and LLM-driven diagnostic recommendations. Through a within-subjects counterbalanced study with 16 clinicians across nephrology and obstetrics, we comprehensively evaluated AICare using objective measures (task completion time and error rate), subjective assessments (NASA-TLX, SUS, and confidence ratings), and semi-structured interviews. Our findings indicate AICare's reduced cognitive workload. Beyond performance metrics, qualitative analysis reveals that trust is actively constructed through verification, with interaction strategies diverging by expertise: junior clinicians used the system as cognitive scaffolding to structure their analysis, while experts engaged in adversarial verification to challenge the AI's logic. This work offers design implications for creating AI systems that function as transparent partners, accommodating diverse reasoning styles to augment rather than replace clinical judgment.
Magical: Medical Lay Language Generation via Semantic Invariance and Layperson-tailored Adaptation
Aug 12, 2025
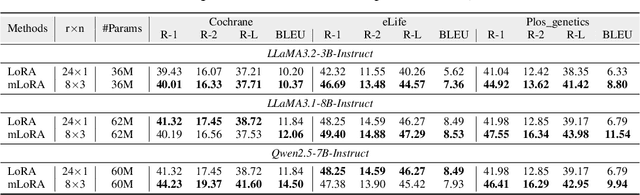
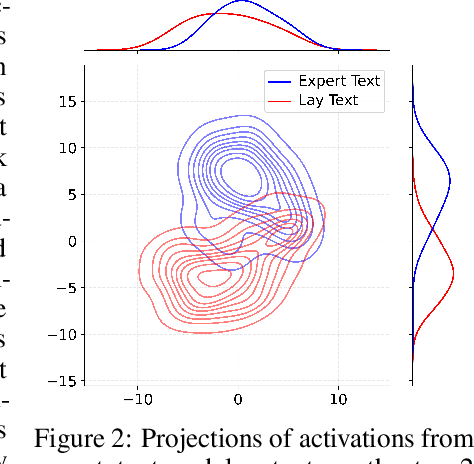
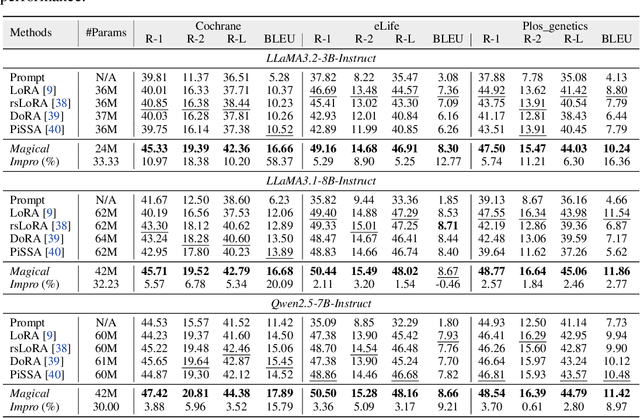
Medical Lay Language Generation (MLLG) plays a vital role in improving the accessibility of complex scientific content for broader audiences. Recent literature to MLLG commonly employ parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA) to fine-tuning large language models (LLMs) using paired expert-lay language datasets. However, LoRA struggles with the challenges posed by multi-source heterogeneous MLLG datasets. Specifically, through a series of exploratory experiments, we reveal that standard LoRA fail to meet the requirement for semantic fidelity and diverse lay-style generation in MLLG task. To address these limitations, we propose Magical, an asymmetric LoRA architecture tailored for MLLG under heterogeneous data scenarios. Magical employs a shared matrix $A$ for abstractive summarization, along with multiple isolated matrices $B$ for diverse lay-style generation. To preserve semantic fidelity during the lay language generation process, Magical introduces a Semantic Invariance Constraint to mitigate semantic subspace shifts on matrix $A$. Furthermore, to better adapt to diverse lay-style generation, Magical incorporates the Recommendation-guided Switch, an externally interface to prompt the LLM to switch between different matrices $B$. Experimental results on three real-world lay language generation datasets demonstrate that Magical consistently outperforms prompt-based methods, vanilla LoRA, and its recent variants, while also reducing trainable parameters by 31.66%.
ConfAgents: A Conformal-Guided Multi-Agent Framework for Cost-Efficient Medical Diagnosis
Aug 06, 2025



The efficacy of AI agents in healthcare research is hindered by their reliance on static, predefined strategies. This creates a critical limitation: agents can become better tool-users but cannot learn to become better strategic planners, a crucial skill for complex domains like healthcare. We introduce HealthFlow, a self-evolving AI agent that overcomes this limitation through a novel meta-level evolution mechanism. HealthFlow autonomously refines its own high-level problem-solving policies by distilling procedural successes and failures into a durable, strategic knowledge base. To anchor our research and facilitate reproducible evaluation, we introduce EHRFlowBench, a new benchmark featuring complex, realistic health data analysis tasks derived from peer-reviewed clinical research. Our comprehensive experiments demonstrate that HealthFlow's self-evolving approach significantly outperforms state-of-the-art agent frameworks. This work marks a necessary shift from building better tool-users to designing smarter, self-evolving task-managers, paving the way for more autonomous and effective AI for scientific discovery.
MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks
May 18, 2025The rapid advancement of Large Language Models (LLMs) has stimulated interest in multi-agent collaboration for addressing complex medical tasks. However, the practical advantages of multi-agent collaboration approaches remain insufficiently understood. Existing evaluations often lack generalizability, failing to cover diverse tasks reflective of real-world clinical practice, and frequently omit rigorous comparisons against both single-LLM-based and established conventional methods. To address this critical gap, we introduce MedAgentBoard, a comprehensive benchmark for the systematic evaluation of multi-agent collaboration, single-LLM, and conventional approaches. MedAgentBoard encompasses four diverse medical task categories: (1) medical (visual) question answering, (2) lay summary generation, (3) structured Electronic Health Record (EHR) predictive modeling, and (4) clinical workflow automation, across text, medical images, and structured EHR data. Our extensive experiments reveal a nuanced landscape: while multi-agent collaboration demonstrates benefits in specific scenarios, such as enhancing task completeness in clinical workflow automation, it does not consistently outperform advanced single LLMs (e.g., in textual medical QA) or, critically, specialized conventional methods that generally maintain better performance in tasks like medical VQA and EHR-based prediction. MedAgentBoard offers a vital resource and actionable insights, emphasizing the necessity of a task-specific, evidence-based approach to selecting and developing AI solutions in medicine. It underscores that the inherent complexity and overhead of multi-agent collaboration must be carefully weighed against tangible performance gains. All code, datasets, detailed prompts, and experimental results are open-sourced at https://medagentboard.netlify.app/.
ColaCare: Enhancing Electronic Health Record Modeling through Large Language Model-Driven Multi-Agent Collaboration
Oct 03, 2024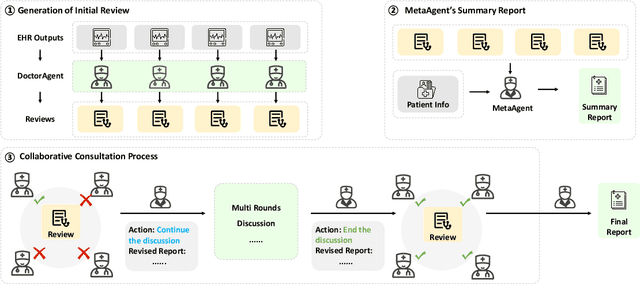
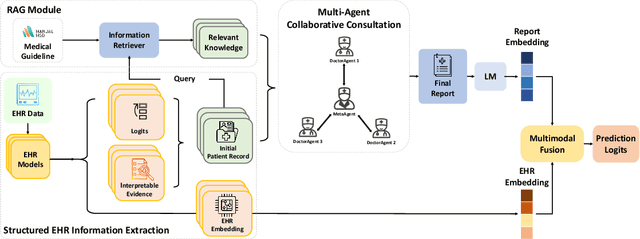

We introduce ColaCare, a framework that enhances Electronic Health Record (EHR) modeling through multi-agent collaboration driven by Large Language Models (LLMs). Our approach seamlessly integrates domain-specific expert models with LLMs to bridge the gap between structured EHR data and text-based reasoning. Inspired by clinical consultations, ColaCare employs two types of agents: DoctorAgent and MetaAgent, which collaboratively analyze patient data. Expert models process and generate predictions from numerical EHR data, while LLM agents produce reasoning references and decision-making reports within the collaborative consultation framework. We additionally incorporate the Merck Manual of Diagnosis and Therapy (MSD) medical guideline within a retrieval-augmented generation (RAG) module for authoritative evidence support. Extensive experiments conducted on four distinct EHR datasets demonstrate ColaCare's superior performance in mortality prediction tasks, underscoring its potential to revolutionize clinical decision support systems and advance personalized precision medicine. The code, complete prompt templates, more case studies, etc. are publicly available at the anonymous link: https://colacare.netlify.app.
Is larger always better? Evaluating and prompting large language models for non-generative medical tasks
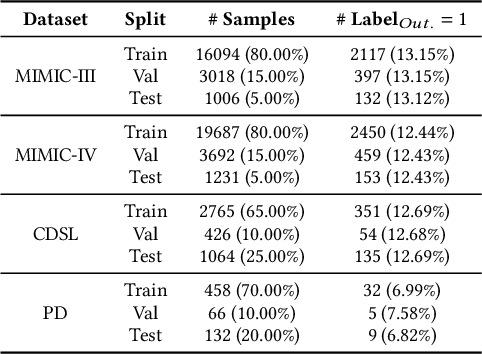
Jul 26, 2024The use of Large Language Models (LLMs) in medicine is growing, but their ability to handle both structured Electronic Health Record (EHR) data and unstructured clinical notes is not well-studied. This study benchmarks various models, including GPT-based LLMs, BERT-based models, and traditional clinical predictive models, for non-generative medical tasks utilizing renowned datasets. We assessed 14 language models (9 GPT-based and 5 BERT-based) and 7 traditional predictive models using the MIMIC dataset (ICU patient records) and the TJH dataset (early COVID-19 EHR data), focusing on tasks such as mortality and readmission prediction, disease hierarchy reconstruction, and biomedical sentence matching, comparing both zero-shot and finetuned performance. Results indicated that LLMs exhibited robust zero-shot predictive capabilities on structured EHR data when using well-designed prompting strategies, frequently surpassing traditional models. However, for unstructured medical texts, LLMs did not outperform finetuned BERT models, which excelled in both supervised and unsupervised tasks. Consequently, while LLMs are effective for zero-shot learning on structured data, finetuned BERT models are more suitable for unstructured texts, underscoring the importance of selecting models based on specific task requirements and data characteristics to optimize the application of NLP technology in healthcare.
EMERGE: Integrating RAG for Improved Multimodal EHR Predictive Modeling
May 27, 2024



The integration of multimodal Electronic Health Records (EHR) data has notably advanced clinical predictive capabilities. However, current models that utilize clinical notes and multivariate time-series EHR data often lack the necessary medical context for precise clinical tasks. Previous methods using knowledge graphs (KGs) primarily focus on structured knowledge extraction. To address this, we propose EMERGE, a Retrieval-Augmented Generation (RAG) driven framework aimed at enhancing multimodal EHR predictive modeling. Our approach extracts entities from both time-series data and clinical notes by prompting Large Language Models (LLMs) and aligns them with professional PrimeKG to ensure consistency. Beyond triplet relationships, we include entities' definitions and descriptions to provide richer semantics. The extracted knowledge is then used to generate task-relevant summaries of patients' health statuses. These summaries are fused with other modalities utilizing an adaptive multimodal fusion network with cross-attention. Extensive experiments on the MIMIC-III and MIMIC-IV datasets for in-hospital mortality and 30-day readmission tasks demonstrate the superior performance of the EMERGE framework compared to baseline models. Comprehensive ablation studies and analyses underscore the efficacy of each designed module and the framework's robustness to data sparsity. EMERGE significantly enhances the use of multimodal EHR data in healthcare, bridging the gap with nuanced medical contexts crucial for informed clinical predictions.
Adaptive Activation Steering: A Tuning-Free LLM Truthfulness Improvement Method for Diverse Hallucinations Categories
May 26, 2024Recent studies have indicated that Large Language Models (LLMs) harbor an inherent understanding of truthfulness, yet often fail to express fully and generate false statements. This gap between "knowing" and "telling" poses a challenge for ensuring the truthfulness of generated content. To address this, we introduce Adaptive Activation Steering (ACT), a tuning-free method that adaptively shift LLM's activations in "truthful" direction during inference. ACT addresses diverse categories of hallucinations by utilizing diverse steering vectors and adjusting the steering intensity adaptively. Applied as an add-on across various models, ACT significantly improves truthfulness in LLaMA ($\uparrow$ 142\%), LLaMA2 ($\uparrow$ 24\%), Alpaca ($\uparrow$ 36\%), Vicuna ($\uparrow$ 28\%), and LLaMA2-Chat ($\uparrow$ 19\%). Furthermore, we verify ACT's scalability across larger models (13B, 33B, 65B), underscoring the adaptability of ACT to large-scale language models.
LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation
Mar 11, 2024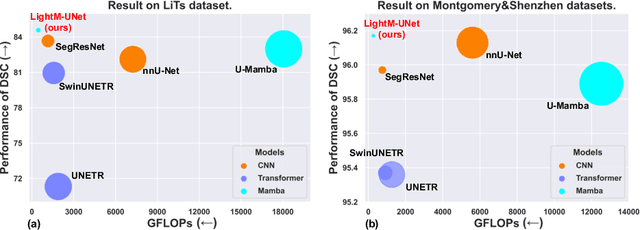
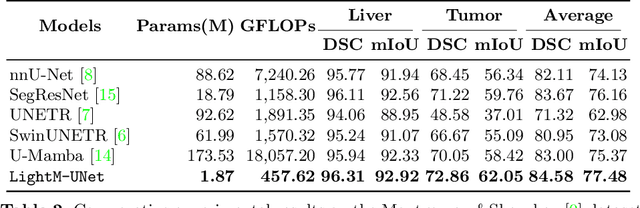
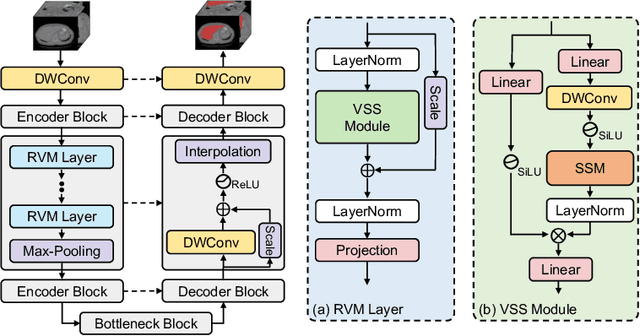
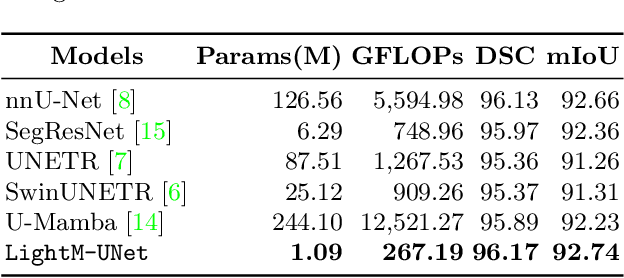
UNet and its variants have been widely used in medical image segmentation. However, these models, especially those based on Transformer architectures, pose challenges due to their large number of parameters and computational loads, making them unsuitable for mobile health applications. Recently, State Space Models (SSMs), exemplified by Mamba, have emerged as competitive alternatives to CNN and Transformer architectures. Building upon this, we employ Mamba as a lightweight substitute for CNN and Transformer within UNet, aiming at tackling challenges stemming from computational resource limitations in real medical settings. To this end, we introduce the Lightweight Mamba UNet (LightM-UNet) that integrates Mamba and UNet in a lightweight framework. Specifically, LightM-UNet leverages the Residual Vision Mamba Layer in a pure Mamba fashion to extract deep semantic features and model long-range spatial dependencies, with linear computational complexity. Extensive experiments conducted on two real-world 2D/3D datasets demonstrate that LightM-UNet surpasses existing state-of-the-art literature. Notably, when compared to the renowned nnU-Net, LightM-UNet achieves superior segmentation performance while drastically reducing parameter and computation costs by 116x and 21x, respectively. This highlights the potential of Mamba in facilitating model lightweighting. Our code implementation is publicly available at https://github.com/MrBlankness/LightM-UNet.