 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Activation Steering: A Tuning-Free LLM Truthfulness Improvement Method for Diverse Hallucinations Categories
May 26, 2024Recent studies have indicated that Large Language Models (LLMs) harbor an inherent understanding of truthfulness, yet often fail to express fully and generate false statements. This gap between "knowing" and "telling" poses a challenge for ensuring the truthfulness of generated content. To address this, we introduce Adaptive Activation Steering (ACT), a tuning-free method that adaptively shift LLM's activations in "truthful" direction during inference. ACT addresses diverse categories of hallucinations by utilizing diverse steering vectors and adjusting the steering intensity adaptively. Applied as an add-on across various models, ACT significantly improves truthfulness in LLaMA ($\uparrow$ 142\%), LLaMA2 ($\uparrow$ 24\%), Alpaca ($\uparrow$ 36\%), Vicuna ($\uparrow$ 28\%), and LLaMA2-Chat ($\uparrow$ 19\%). Furthermore, we verify ACT's scalability across larger models (13B, 33B, 65B), underscoring the adaptability of ACT to large-scale language models.
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
Dec 29, 2023Despite the great success of large language models (LLMs) in various tasks, they suffer from generating hallucinations. We introduce Truth Forest, a method that enhances truthfulness in LLMs by uncovering hidden truth representations using multi-dimensional orthogonal probes. Specifically, it creates multiple orthogonal bases for modeling truth by incorporating orthogonal constraints into the probes. Moreover, we introduce Random Peek, a systematic technique considering an extended range of positions within the sequence, reducing the gap between discerning and generating truth features in LLMs. By employing this approach, we improved the truthfulness of Llama-2-7B from 40.8\% to 74.5\% on TruthfulQA. Likewise, significant improvements are observed in fine-tuned models. We conducted a thorough analysis of truth features using probes. Our visualization results show that orthogonal probes capture complementary truth-related features, forming well-defined clusters that reveal the inherent structure of the dataset. Code: \url{https://github.com/jongjyh/trfr}
Microstructure-Empowered Stock Factor Extraction and Utilization
Aug 16, 2023High-frequency quantitative investment is a crucial aspect of stock investment. Notably, order flow data plays a critical role as it provides the most detailed level of information among high-frequency trading data, including comprehensive data from the order book and transaction records at the tick level. The order flow data is extremely valuable for market analysis as it equips traders with essential insights for making informed decisions. However, extracting and effectively utilizing order flow data present challenges due to the large volume of data involved and the limitations of traditional factor mining techniques, which are primarily designed for coarser-level stock data. To address these challenges, we propose a novel framework that aims to effectively extract essential factors from order flow data for diverse downstream tasks across different granularities and scenarios. Our method consists of a Context Encoder and an Factor Extractor. The Context Encoder learns an embedding for the current order flow data segment's context by considering both the expected and actual market state. In addition, the Factor Extractor uses unsupervised learning methods to select such important signals that are most distinct from the majority within the given context. The extracted factors are then utilized for downstream tasks. In empirical studies, our proposed framework efficiently handles an entire year of stock order flow data across diverse scenarios, offering a broader range of applications compared to existing tick-level approaches that are limited to only a few days of stock data. We demonstrate that our method extracts superior factors from order flow data, enabling significant improvement for stock trend prediction and order execution tasks at the second and minute level.
Mortality Prediction with Adaptive Feature Importance Recalibration for Peritoneal Dialysis Patients: a deep-learning-based study on a real-world longitudinal follow-up dataset
Jan 17, 2023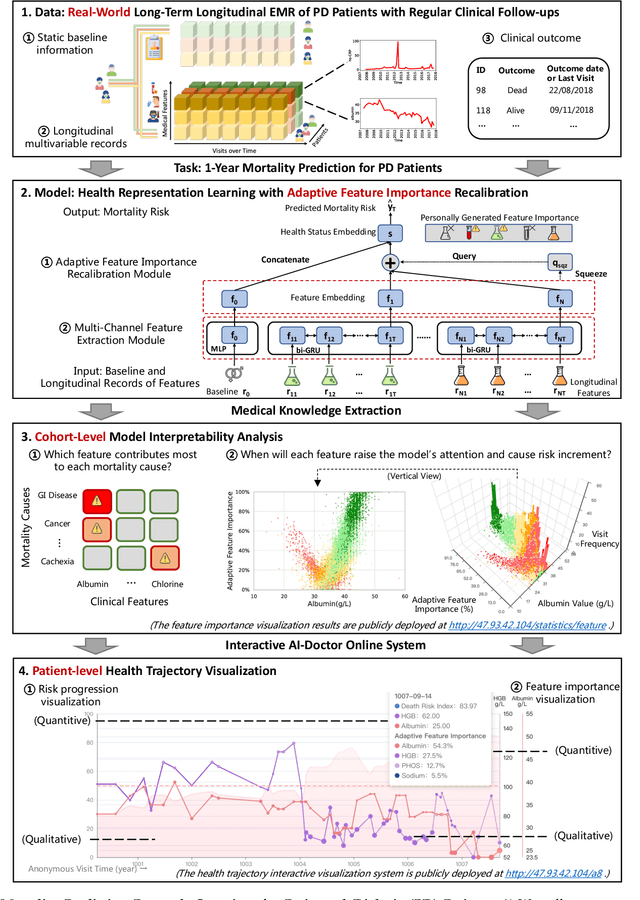
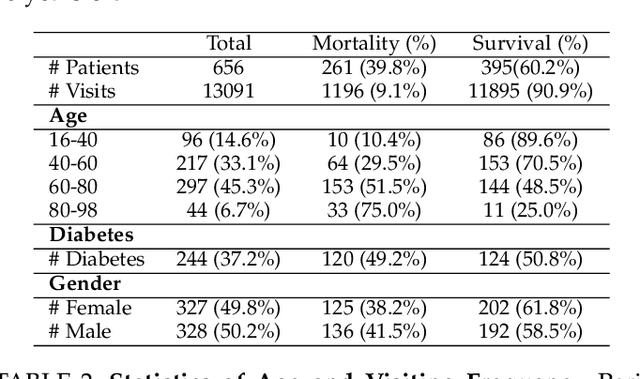
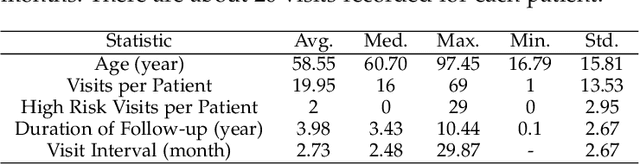
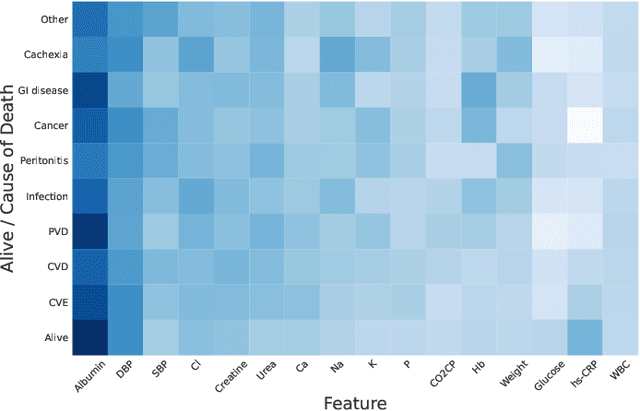
Objective: Peritoneal Dialysis (PD) is one of the most widely used life-supporting therapies for patients with End-Stage Renal Disease (ESRD). Predicting mortality risk and identifying modifiable risk factors based on the Electronic Medical Records (EMR) collected along with the follow-up visits are of great importance for personalized medicine and early intervention. Here, our objective is to develop a deep learning model for a real-time, individualized, and interpretable mortality prediction model - AICare. Method and Materials: Our proposed model consists of a multi-channel feature extraction module and an adaptive feature importance recalibration module. AICare explicitly identifies the key features that strongly indicate the outcome prediction for each patient to build the health status embedding individually. This study has collected 13,091 clinical follow-up visits and demographic data of 656 PD patients. To verify the application universality, this study has also collected 4,789 visits of 1,363 hemodialysis dialysis (HD) as an additional experiment dataset to test the prediction performance, which will be discussed in the Appendix. Results: 1) Experiment results show that AICare achieves 81.6%/74.3% AUROC and 47.2%/32.5% AUPRC for the 1-year mortality prediction task on PD/HD dataset respectively, which outperforms the state-of-the-art comparative deep learning models. 2) This study first provides a comprehensive elucidation of the relationship between the causes of mortality in patients with PD and clinical features based on an end-to-end deep learning model. 3) This study first reveals the pattern of variation in the importance of each feature in the mortality prediction based on built-in interpretability. 4) We develop a practical AI-Doctor interaction system to visualize the trajectory of patients' health status and risk indicators.
CovidCare: Transferring Knowledge from Existing EMR to Emerging Epidemic for Interpretable Prognosis
Jul 17, 2020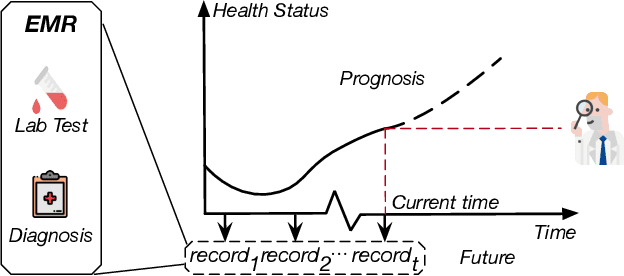

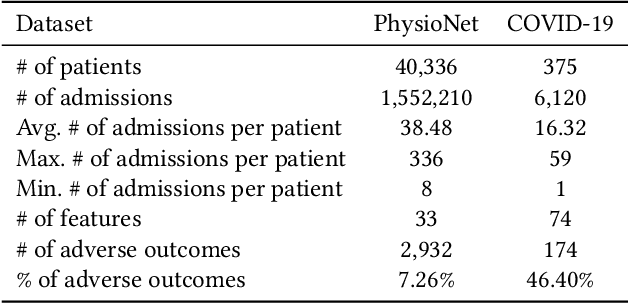
Due to the characteristics of COVID-19, the epidemic develops rapidly and overwhelms health service systems worldwide. Many patients suffer from systemic life-threatening problems and need to be carefully monitored in ICUs. Thus the intelligent prognosis is in an urgent need to assist physicians to take an early intervention, prevent the adverse outcome, and optimize the medical resource allocation. However, in the early stage of the epidemic outbreak, the data available for analysis is limited due to the lack of effective diagnostic mechanisms, rarity of the cases, and privacy concerns. In this paper, we propose a deep-learning-based approach, CovidCare, which leverages the existing electronic medical records to enhance the prognosis for inpatients with emerging infectious diseases. It learns to embed the COVID-19-related medical features based on massive existing EMR data via transfer learning. The transferred parameters are further trained to imitate the teacher model's representation behavior based on knowledge distillation, which embeds the health status more comprehensively in the source dataset. We conduct the length of stay prediction experiments for patients on a real-world COVID-19 dataset. The experiment results indicate that our proposed model consistently outperforms the comparative baseline methods. CovidCare also reveals that, 1) hs-cTnI, hs-CRP and Platelet Counts are the most fatal biomarkers, whose abnormal values usually indicate emergency adverse outcome. 2) Normal values of gamma-GT, AP and eGFR indicate the overall improvement of health. The medical findings extracted by CovidCare are empirically confirmed by human experts and medical literatures.