 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper LiDAR Reflectance for Robotic Perception
Aug 14, 2025Conventionally, human intuition often defines vision as a modality of passive optical sensing, while active optical sensing is typically regarded as measuring rather than the default modality of vision. However, the situation now changes: sensor technologies and data-driven paradigms empower active optical sensing to redefine the boundaries of vision, ushering in a new era of active vision. Light Detection and Ranging (LiDAR) sensors capture reflectance from object surfaces, which remains invariant under varying illumination conditions, showcasing significant potential in robotic perception tasks such as detection, recognition, segmentation, and Simultaneous Localization and Mapping (SLAM). These applications often rely on dense sensing capabilities, typically achieved by high-resolution, expensive LiDAR sensors. A key challenge with low-cost LiDARs lies in the sparsity of scan data, which limits their broader application. To address this limitation, this work introduces an innovative framework for generating dense LiDAR reflectance images from sparse data, leveraging the unique attributes of non-repeating scanning LiDAR (NRS-LiDAR). We tackle critical challenges, including reflectance calibration and the transition from static to dynamic scene domains, facilitating the reconstruction of dense reflectance images in real-world settings. The key contributions of this work include a comprehensive dataset for LiDAR reflectance image densification, a densification network tailored for NRS-LiDAR, and diverse applications such as loop closure and traffic lane detection using the generated dense reflectance images.
OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving
Dec 23, 2024



To enhance autonomous driving safety in complex scenarios, various methods have been proposed to simulate LiDAR point cloud data. Nevertheless, these methods often face challenges in producing high-quality, diverse, and controllable foreground objects. To address the needs of object-aware tasks in 3D perception, we introduce OLiDM, a novel framework capable of generating high-fidelity LiDAR data at both the object and the scene levels. OLiDM consists of two pivotal components: the Object-Scene Progressive Generation (OPG) module and the Object Semantic Alignment (OSA) module. OPG adapts to user-specific prompts to generate desired foreground objects, which are subsequently employed as conditions in scene generation, ensuring controllable outputs at both the object and scene levels. This also facilitates the association of user-defined object-level annotations with the generated LiDAR scenes. Moreover, OSA aims to rectify the misalignment between foreground objects and background scenes, enhancing the overall quality of the generated objects. The broad effectiveness of OLiDM is demonstrated across various LiDAR generation tasks, as well as in 3D perception tasks. Specifically, on the KITTI-360 dataset, OLiDM surpasses prior state-of-the-art methods such as UltraLiDAR by 17.5 in FPD. Additionally, in sparse-to-dense LiDAR completion, OLiDM achieves a significant improvement over LiDARGen, with a 57.47\% increase in semantic IoU. Moreover, OLiDM enhances the performance of mainstream 3D detectors by 2.4\% in mAP and 1.9\% in NDS, underscoring its potential in advancing object-aware 3D tasks. Code is available at: https://yanty123.github.io/OLiDM.
UMAD: University of Macau Anomaly Detection Benchmark Dataset
Aug 22, 2024



Anomaly detection is critical in surveillance systems and patrol robots by identifying anomalous regions in images for early warning. Depending on whether reference data are utilized, anomaly detection can be categorized into anomaly detection with reference and anomaly detection without reference. Currently, anomaly detection without reference, which is closely related to out-of-distribution (OoD) object detection, struggles with learning anomalous patterns due to the difficulty of collecting sufficiently large and diverse anomaly datasets with the inherent rarity and novelty of anomalies. Alternatively, anomaly detection with reference employs the scheme of change detection to identify anomalies by comparing semantic changes between a reference image and a query one. However, there are very few ADr works due to the scarcity of public datasets in this domain. In this paper, we aim to address this gap by introducing the UMAD Benchmark Dataset. To our best knowledge, this is the first benchmark dataset designed specifically for anomaly detection with reference in robotic patrolling scenarios, e.g., where an autonomous robot is employed to detect anomalous objects by comparing a reference and a query video sequences. The reference sequences can be taken by the robot along a specified route when there are no anomalous objects in the scene. The query sequences are captured online by the robot when it is patrolling in the same scene following the same route. Our benchmark dataset is elaborated such that each query image can find a corresponding reference based on accurate robot localization along the same route in the prebuilt 3D map, with which the reference and query images can be geometrically aligned using adaptive warping. Besides the proposed benchmark dataset, we evaluate the baseline models of ADr on this dataset.
Active Loop Closure for OSM-guided Robotic Mapping in Large-Scale Urban Environments
Jul 24, 2024



The autonomous mapping of large-scale urban scenes presents significant challenges for autonomous robots. To mitigate the challenges, global planning, such as utilizing prior GPS trajectories from OpenStreetMap (OSM), is often used to guide the autonomous navigation of robots for mapping. However, due to factors like complex terrain, unexpected body movement, and sensor noise, the uncertainty of the robot's pose estimates inevitably increases over time, ultimately leading to the failure of robotic mapping. To address this issue, we propose a novel active loop closure procedure, enabling the robot to actively re-plan the previously planned GPS trajectory. The method can guide the robot to re-visit the previous places where the loop-closure detection can be performed to trigger the back-end optimization, effectively reducing errors and uncertainties in pose estimation. The proposed active loop closure mechanism is implemented and embedded into a real-time OSM-guided robot mapping framework. Empirical results on several large-scale outdoor scenarios demonstrate its effectiveness and promising performance.
Diverse and Fine-Grained Instruction-Following Ability Exploration with Synthetic Data
Jul 04, 2024



Instruction-following is particularly crucial for large language models (LLMs) to support diverse user requests. While existing work has made progress in aligning LLMs with human preferences, evaluating their capabilities on instruction following remains a challenge due to complexity and diversity of real-world user instructions. While existing evaluation methods focus on general skills, they suffer from two main shortcomings, i.e., lack of fine-grained task-level evaluation and reliance on singular instruction expression. To address these problems, this paper introduces DINGO, a fine-grained and diverse instruction-following evaluation dataset that has two main advantages: (1) DINGO is based on a manual annotated, fine-grained and multi-level category tree with 130 nodes derived from real-world user requests; (2) DINGO includes diverse instructions, generated by both GPT-4 and human experts. Through extensive experiments, we demonstrate that DINGO can not only provide more challenging and comprehensive evaluation for LLMs, but also provide task-level fine-grained directions to further improve LLMs.
DME-Driver: Integrating Human Decision Logic and 3D Scene Perception in Autonomous Driving
Jan 08, 2024In the field of autonomous driving, two important features of autonomous driving car systems are the explainability of decision logic and the accuracy of environmental perception. This paper introduces DME-Driver, a new autonomous driving system that enhances the performance and reliability of autonomous driving system. DME-Driver utilizes a powerful vision language model as the decision-maker and a planning-oriented perception model as the control signal generator. To ensure explainable and reliable driving decisions, the logical decision-maker is constructed based on a large vision language model. This model follows the logic employed by experienced human drivers and makes decisions in a similar manner. On the other hand, the generation of accurate control signals relies on precise and detailed environmental perception, which is where 3D scene perception models excel. Therefore, a planning oriented perception model is employed as the signal generator. It translates the logical decisions made by the decision-maker into accurate control signals for the self-driving cars. To effectively train the proposed model, a new dataset for autonomous driving was created. This dataset encompasses a diverse range of human driver behaviors and their underlying motivations. By leveraging this dataset, our model achieves high-precision planning accuracy through a logical thinking process.
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
Dec 29, 2023Despite the great success of large language models (LLMs) in various tasks, they suffer from generating hallucinations. We introduce Truth Forest, a method that enhances truthfulness in LLMs by uncovering hidden truth representations using multi-dimensional orthogonal probes. Specifically, it creates multiple orthogonal bases for modeling truth by incorporating orthogonal constraints into the probes. Moreover, we introduce Random Peek, a systematic technique considering an extended range of positions within the sequence, reducing the gap between discerning and generating truth features in LLMs. By employing this approach, we improved the truthfulness of Llama-2-7B from 40.8\% to 74.5\% on TruthfulQA. Likewise, significant improvements are observed in fine-tuned models. We conducted a thorough analysis of truth features using probes. Our visualization results show that orthogonal probes capture complementary truth-related features, forming well-defined clusters that reveal the inherent structure of the dataset. Code: \url{https://github.com/jongjyh/trfr}
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Dec 25, 2023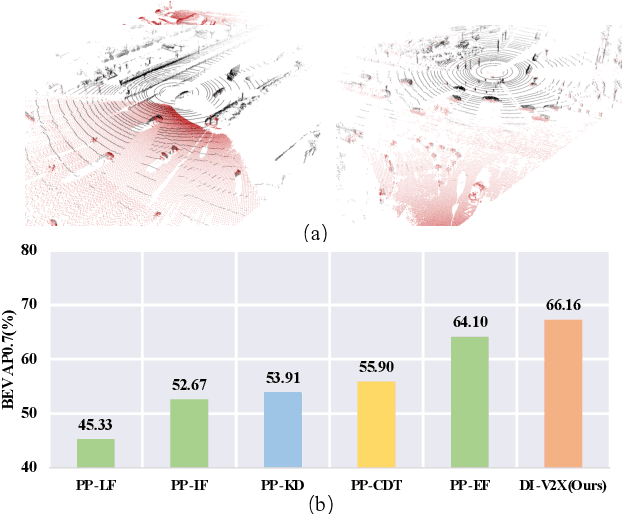
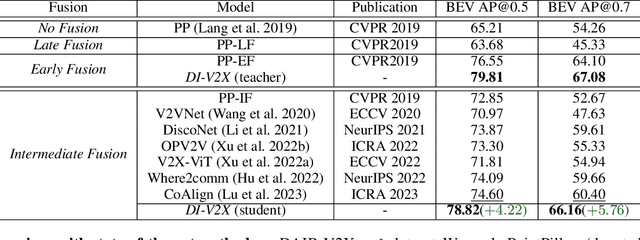
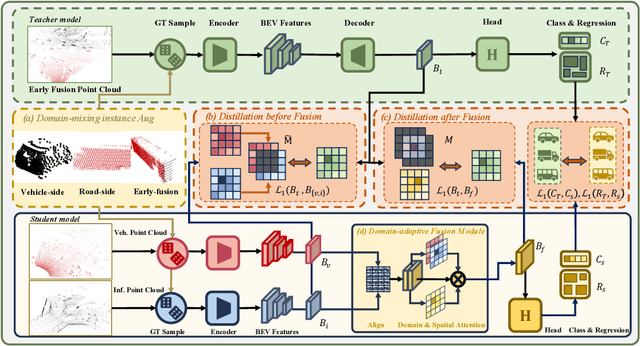
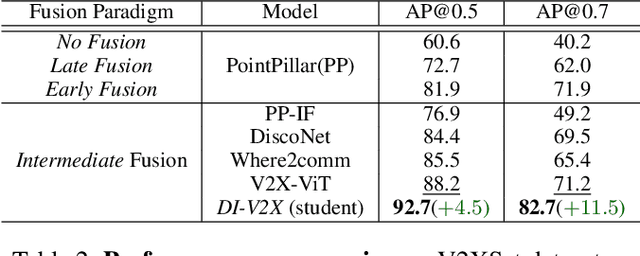
Vehicle-to-Everything (V2X) collaborative perception has recently gained significant attention due to its capability to enhance scene understanding by integrating information from various agents, e.g., vehicles, and infrastructure. However, current works often treat the information from each agent equally, ignoring the inherent domain gap caused by the utilization of different LiDAR sensors of each agent, thus leading to suboptimal performance. In this paper, we propose DI-V2X, that aims to learn Domain-Invariant representations through a new distillation framework to mitigate the domain discrepancy in the context of V2X 3D object detection. DI-V2X comprises three essential components: a domain-mixing instance augmentation (DMA) module, a progressive domain-invariant distillation (PDD) module, and a domain-adaptive fusion (DAF) module. Specifically, DMA builds a domain-mixing 3D instance bank for the teacher and student models during training, resulting in aligned data representation. Next, PDD encourages the student models from different domains to gradually learn a domain-invariant feature representation towards the teacher, where the overlapping regions between agents are employed as guidance to facilitate the distillation process. Furthermore, DAF closes the domain gap between the students by incorporating calibration-aware domain-adaptive attention. Extensive experiments on the challenging DAIR-V2X and V2XSet benchmark datasets demonstrate DI-V2X achieves remarkable performance, outperforming all the previous V2X models. Code is available at https://github.com/Serenos/DI-V2X
APBench: A Unified Benchmark for Availability Poisoning Attacks and Defenses
Aug 07, 2023



The efficacy of availability poisoning, a method of poisoning data by injecting imperceptible perturbations to prevent its use in model training, has been a hot subject of investigation. Previous research suggested that it was difficult to effectively counteract such poisoning attacks. However, the introduction of various defense methods has challenged this notion. Due to the rapid progress in this field, the performance of different novel methods cannot be accurately validated due to variations in experimental setups. To further evaluate the attack and defense capabilities of these poisoning methods, we have developed a benchmark -- APBench for assessing the efficacy of adversarial poisoning. APBench consists of 9 state-of-the-art availability poisoning attacks, 8 defense algorithms, and 4 conventional data augmentation techniques. We also have set up experiments with varying different poisoning ratios, and evaluated the attacks on multiple datasets and their transferability across model architectures. We further conducted a comprehensive evaluation of 2 additional attacks specifically targeting unsupervised models. Our results reveal the glaring inadequacy of existing attacks in safeguarding individual privacy. APBench is open source and available to the deep learning community: https://github.com/lafeat/apbench.
GSB: Group Superposition Binarization for Vision Transformer with Limited Training Samples
May 19, 2023



Affected by the massive amount of parameters, ViT usually suffers from serious overfitting problems with a relatively limited number of training samples. In addition, ViT generally demands heavy computing resources, which limit its deployment on resource-constrained devices. As a type of model-compression method,model binarization is potentially a good choice to solve the above problems. Compared with the full-precision one, the model with the binarization method replaces complex tensor multiplication with simple bit-wise binary operations and represents full-precision model parameters and activations with only 1-bit ones, which potentially solves the problem of model size and computational complexity, respectively. In this paper, we find that the decline of the accuracy of the binary ViT model is mainly due to the information loss of the Attention module and the Value vector. Therefore, we propose a novel model binarization technique, called Group Superposition Binarization (GSB), to deal with these issues. Furthermore, in order to further improve the performance of the binarization model, we have investigated the gradient calculation procedure in the binarization process and derived more proper gradient calculation equations for GSB to reduce the influence of gradient mismatch. Then, the knowledge distillation technique is introduced to alleviate the performance degradation caused by model binarization. Experiments on three datasets with limited numbers of training samples demonstrate that the proposed GSB model achieves state-of-the-art performance among the binary quantization schemes and exceeds its full-precision counterpart on some indicators.