 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Collaborative Gaussian Splatting with Integrated Rendering and Communication
Oct 26, 2025Gaussian splatting (GS) struggles with degraded rendering quality on low-cost devices. To address this issue, we present edge collaborative GS (ECO-GS), where each user can switch between a local small GS model to guarantee timeliness and a remote large GS model to guarantee fidelity. However, deciding how to engage the large GS model is nontrivial, due to the interdependency between rendering requirements and resource conditions. To this end, we propose integrated rendering and communication (IRAC), which jointly optimizes collaboration status (i.e., deciding whether to engage large GS) and edge power allocation (i.e., enabling remote rendering) under communication constraints across different users by minimizing a newly-derived GS switching function. Despite the nonconvexity of the problem, we propose an efficient penalty majorization minimization (PMM) algorithm to obtain the critical point solution. Furthermore, we develop an imitation learning optimization (ILO) algorithm, which reduces the computational time by over 100x compared to PMM. Experiments demonstrate the superiority of PMM and the real-time execution capability of ILO.
RSMA-Enhanced Data Collection in RIS-Assisted Intelligent Consumer Transportation Systems
Sep 11, 2025This paper investigates the data collection enhancement problem in a reconfigurable intelligent surface (RIS)-empowered intelligent consumer transportation system (ICTS). We propose a novel framework where a data center (DC) provides energy to pre-configured roadside unit (RSU) pairs during the downlink stage. While in the uplink stage, these RSU pairs utilize a hybrid rate-splitting multiple access (RSMA) and time-division multiple access (TDMA) protocol to transmit the processed data to the DC, while simultaneously performing local data processing using the harvested energy. Our objective is to maximize the minimal processed data volume of the RSU pairs by jointly optimizing the RIS downlink and uplink phase shifts, the transmit power of the DC and RSUs, the RSU computation resource allocation, and the time slot allocation. To address the formulated non-convex problem, we develop an efficient iterative algorithm integrating alternating optimization and sequential rank-one constraint relaxation methods. Extensive simulations demonstrate that the proposed algorithm significantly outperforms baseline schemes under diverse scenarios, validating its effectiveness in enhancing the data processing performance for intelligent transportation applications.
Communication Efficient Robotic Mixed Reality with Gaussian Splatting Cross-Layer Optimization
Aug 12, 2025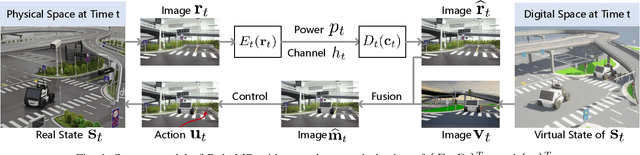
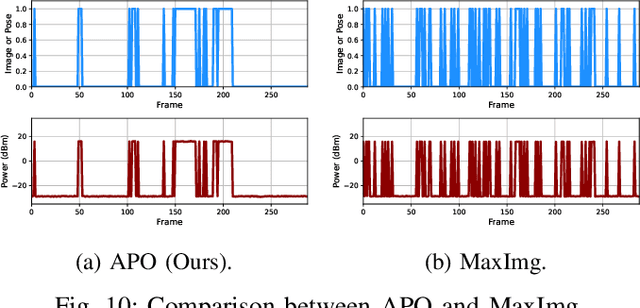
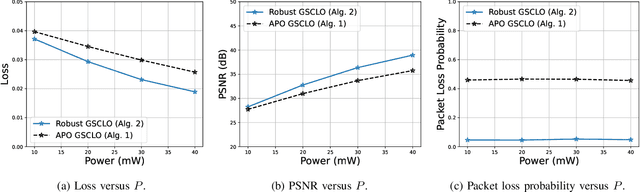
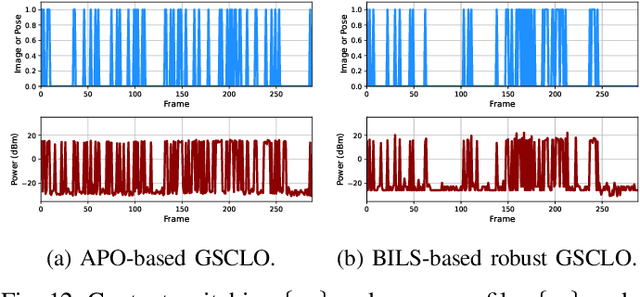
Realizing low-cost communication in robotic mixed reality (RoboMR) systems presents a challenge, due to the necessity of uploading high-resolution images through wireless channels. This paper proposes Gaussian splatting (GS) RoboMR (GSMR), which enables the simulator to opportunistically render a photo-realistic view from the robot's pose by calling ``memory'' from a GS model, thus reducing the need for excessive image uploads. However, the GS model may involve discrepancies compared to the actual environments. To this end, a GS cross-layer optimization (GSCLO) framework is further proposed, which jointly optimizes content switching (i.e., deciding whether to upload image or not) and power allocation (i.e., adjusting to content profiles) across different frames by minimizing a newly derived GSMR loss function. The GSCLO problem is addressed by an accelerated penalty optimization (APO) algorithm that reduces computational complexity by over $10$x compared to traditional branch-and-bound and search algorithms. Moreover, variants of GSCLO are presented to achieve robust, low-power, and multi-robot GSMR. Extensive experiments demonstrate that the proposed GSMR paradigm and GSCLO method achieve significant improvements over existing benchmarks on both wheeled and legged robots in terms of diverse metrics in various scenarios. For the first time, it is found that RoboMR can be achieved with ultra-low communication costs, and mixture of data is useful for enhancing GS performance in dynamic scenarios.
BucketServe: Bucket-Based Dynamic Batching for Smart and Efficient LLM Inference Serving
Jul 23, 2025Large language models (LLMs) have become increasingly popular in various areas, traditional business gradually shifting from rule-based systems to LLM-based solutions. However, the inference of LLMs is resource-intensive or latency-sensitive, posing significant challenges for serving systems. Existing LLM serving systems often use static or continuous batching strategies, which can lead to inefficient GPU memory utilization and increased latency, especially under heterogeneous workloads. These methods may also struggle to adapt to dynamic workload fluctuations, resulting in suboptimal throughput and potential service level objective (SLO) violations. In this paper, we introduce BucketServe, a bucket-based dynamic batching framework designed to optimize LLM inference performance. By grouping requests into size-homogeneous buckets based on sequence length, BucketServe minimizes padding overhead and optimizes GPU memory usage through real-time batch size adjustments preventing out-of-memory (OOM) errors. It introduces adaptive bucket splitting/merging and priority-aware scheduling to mitigate resource fragmentation and ensure SLO compliance. Experiment shows that BucketServe significantly outperforms UELLM in throughput, achieving up to 3.58x improvement. It can also handle 1.93x more request load under the SLO attainment of 80% compared with DistServe and demonstrates 1.975x higher system load capacity compared to the UELLM.
Mixture of Weight-shared Heterogeneous Group Attention Experts for Dynamic Token-wise KV Optimization
Jun 16, 2025
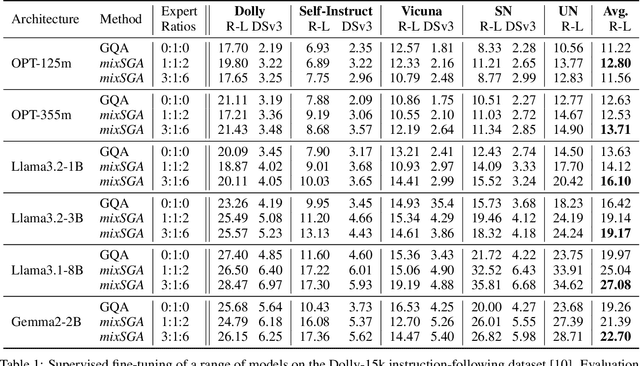
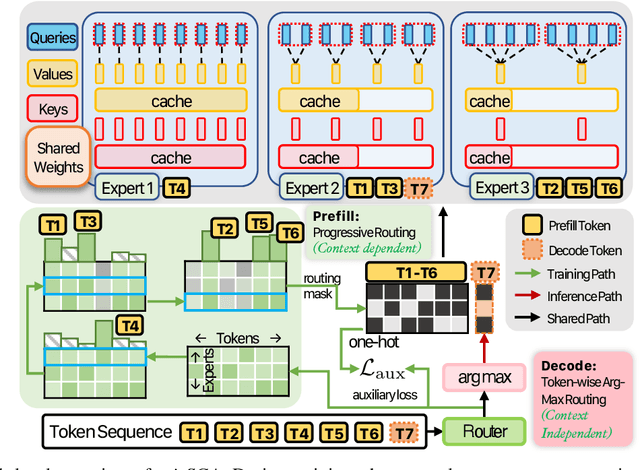

Transformer models face scalability challenges in causal language modeling (CLM) due to inefficient memory allocation for growing key-value (KV) caches, which strains compute and storage resources. Existing methods like Grouped Query Attention (GQA) and token-level KV optimization improve efficiency but rely on rigid resource allocation, often discarding "low-priority" tokens or statically grouping them, failing to address the dynamic spectrum of token importance. We propose mixSGA, a novel mixture-of-expert (MoE) approach that dynamically optimizes token-wise computation and memory allocation. Unlike prior approaches, mixSGA retains all tokens while adaptively routing them to specialized experts with varying KV group sizes, balancing granularity and efficiency. Our key novelties include: (1) a token-wise expert-choice routing mechanism guided by learned importance scores, enabling proportional resource allocation without token discard; (2) weight-sharing across grouped attention projections to minimize parameter overhead; and (3) an auxiliary loss to ensure one-hot routing decisions for training-inference consistency in CLMs. Extensive evaluations across Llama3, TinyLlama, OPT, and Gemma2 model families show mixSGA's superiority over static baselines. On instruction-following and continued pretraining tasks, mixSGA achieves higher ROUGE-L and lower perplexity under the same KV budgets.
Green Robotic Mixed Reality with Gaussian Splatting
Apr 18, 2025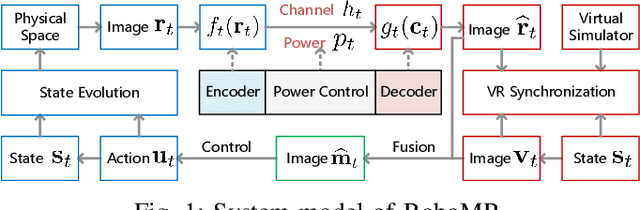

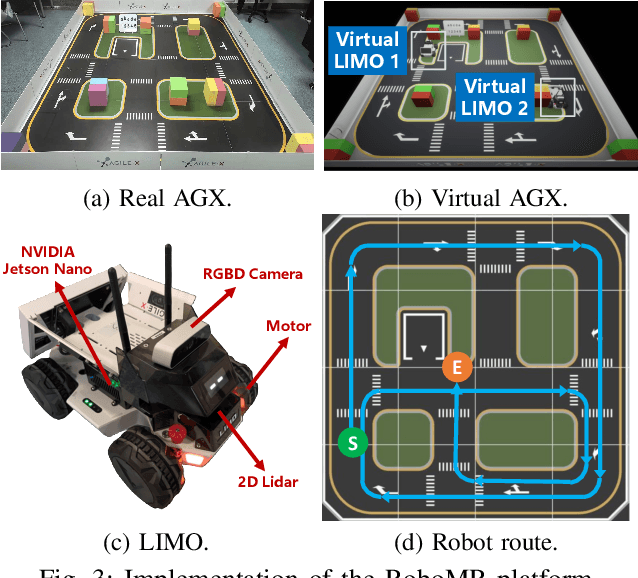
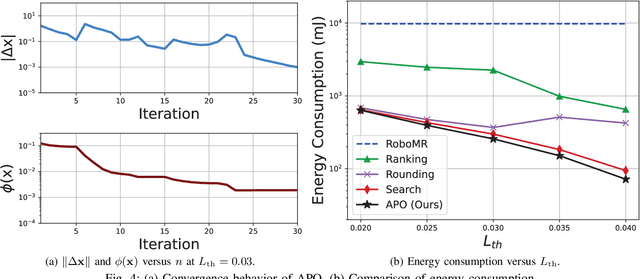
Realizing green communication in robotic mixed reality (RoboMR) systems presents a challenge, due to the necessity of uploading high-resolution images at high frequencies through wireless channels. This paper proposes Gaussian splatting (GS) RoboMR (GSRMR), which achieves a lower energy consumption and makes a concrete step towards green RoboMR. The crux to GSRMR is to build a GS model which enables the simulator to opportunistically render a photo-realistic view from the robot's pose, thereby reducing the need for excessive image uploads. Since the GS model may involve discrepancies compared to the actual environments, a GS cross-layer optimization (GSCLO) framework is further proposed, which jointly optimizes content switching (i.e., deciding whether to upload image or not) and power allocation across different frames. The GSCLO problem is solved by an accelerated penalty optimization (APO) algorithm. Experiments demonstrate that the proposed GSRMR reduces the communication energy by over 10x compared with RoboMR. Furthermore, the proposed GSRMR with APO outperforms extensive baseline schemes, in terms of peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM).
Clutter Resilient Occlusion Avoidance for Tightly-Coupled Motion-Assisted Detection
Dec 24, 2024



Occlusion is a key factor leading to detection failures. This paper proposes a motion-assisted detection (MAD) method that actively plans an executable path, for the robot to observe the target at a new viewpoint with potentially reduced occlusion. In contrast to existing MAD approaches that may fail in cluttered environments, the proposed framework is robust in such scenarios, therefore termed clutter resilient occlusion avoidance (CROA). The crux to CROA is to minimize the occlusion probability under polyhedron-based collision avoidance constraints via the convex-concave procedure and duality-based bilevel optimization. The system implementation supports lidar-based MAD with intertwined execution of learning-based detection and optimization-based planning. Experiments show that CROA outperforms various MAD schemes under a sparse convolutional neural network detector, in terms of point density, occlusion ratio, and detection error, in a multi-lane urban driving scenario.
MPCOM: Robotic Data Gathering with Radio Mapping and Model Predictive Communication
Apr 16, 2024Robotic data gathering (RDG) is an emerging paradigm that navigates a robot to harvest data from remote sensors. However, motion planning in this paradigm needs to maximize the RDG efficiency instead of the navigation efficiency, for which the existing motion planning methods become inefficient, as they plan robot trajectories merely according to motion factors. This paper proposes radio map guided model predictive communication (MPCOM), which navigates the robot with both grid and radio maps for shape-aware collision avoidance and communication-aware trajectory generation in a dynamic environment. The proposed MPCOM is able to trade off the time spent on reaching goal, avoiding collision, and improving communication. MPCOM captures high-order signal propagation characteristics using radio maps and incorporates the map-guided communication regularizer to the motion planning block. Experiments in IRSIM and CARLA simulators show that the proposed MPCOM outperforms other benchmarks in both LOS and NLOS cases. Real-world testing based on car-like robots is also provided to demonstrate the effectiveness of MPCOM in indoor environments.
APBench: A Unified Benchmark for Availability Poisoning Attacks and Defenses
Aug 07, 2023



The efficacy of availability poisoning, a method of poisoning data by injecting imperceptible perturbations to prevent its use in model training, has been a hot subject of investigation. Previous research suggested that it was difficult to effectively counteract such poisoning attacks. However, the introduction of various defense methods has challenged this notion. Due to the rapid progress in this field, the performance of different novel methods cannot be accurately validated due to variations in experimental setups. To further evaluate the attack and defense capabilities of these poisoning methods, we have developed a benchmark -- APBench for assessing the efficacy of adversarial poisoning. APBench consists of 9 state-of-the-art availability poisoning attacks, 8 defense algorithms, and 4 conventional data augmentation techniques. We also have set up experiments with varying different poisoning ratios, and evaluated the attacks on multiple datasets and their transferability across model architectures. We further conducted a comprehensive evaluation of 2 additional attacks specifically targeting unsupervised models. Our results reveal the glaring inadequacy of existing attacks in safeguarding individual privacy. APBench is open source and available to the deep learning community: https://github.com/lafeat/apbench.
Learning the Unlearnable: Adversarial Augmentations Suppress Unlearnable Example Attacks
Mar 27, 2023



Unlearnable example attacks are data poisoning techniques that can be used to safeguard public data against unauthorized use for training deep learning models. These methods add stealthy perturbations to the original image, thereby making it difficult for deep learning models to learn from these training data effectively. Current research suggests that adversarial training can, to a certain degree, mitigate the impact of unlearnable example attacks, while common data augmentation methods are not effective against such poisons. Adversarial training, however, demands considerable computational resources and can result in non-trivial accuracy loss. In this paper, we introduce the UEraser method, which outperforms current defenses against different types of state-of-the-art unlearnable example attacks through a combination of effective data augmentation policies and loss-maximizing adversarial augmentations. In stark contrast to the current SOTA adversarial training methods, UEraser uses adversarial augmentations, which extends beyond the confines of $ \ell_p $ perturbation budget assumed by current unlearning attacks and defenses. It also helps to improve the model's generalization ability, thus protecting against accuracy loss. UEraser wipes out the unlearning effect with error-maximizing data augmentations, thus restoring trained model accuracies. Interestingly, UEraser-Lite, a fast variant without adversarial augmentations, is also highly effective in preserving clean accuracies. On challenging unlearnable CIFAR-10, CIFAR-100, SVHN, and ImageNet-subset datasets produced with various attacks, it achieves results that are comparable to those obtained during clean training. We also demonstrate its efficacy against possible adaptive attacks. Our code is open source and available to the deep learning community: https://github.com/lafeat/ueraser.