 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKRONE: Hierarchical and Modular Log Anomaly Detection
Feb 07, 2026Log anomaly detection is crucial for uncovering system failures and security risks. Although logs originate from nested component executions with clear boundaries, this structure is lost when they are stored as flat sequences. As a result, state-of-the-art methods risk missing true dependencies within executions while learning spurious ones across unrelated events. We propose KRONE, the first hierarchical anomaly detection framework that automatically derives execution hierarchies from flat logs for modular multi-level anomaly detection. At its core, the KRONE Log Abstraction Model captures application-specific semantic hierarchies from log data. This hierarchy is then leveraged to recursively decompose log sequences into multiple levels of coherent execution chunks, referred to as KRONE Seqs, transforming sequence-level anomaly detection into a set of modular KRONE Seq-level detection tasks. For each test KRONE Seq, KRONE employs a hybrid modular detection mechanism that dynamically routes between an efficient level-independent Local-Context detector, which rapidly filters normal sequences, and a Nested-Aware detector that incorporates cross-level semantic dependencies and supports LLM-based anomaly detection and explanation. KRONE further optimizes hierarchical detection through cached result reuse and early-exit strategies. Experiments on three public benchmarks and one industrial dataset from ByteDance Cloud demonstrate that KRONE achieves consistent improvements in detection accuracy, F1-score, data efficiency, resource efficiency, and interpretability. KRONE improves the F1-score by more than 10 percentage points over prior methods while reducing LLM usage to only a small fraction of the test data.
ZeroCard: Cardinality Estimation with Zero Dependence on Target Databases -- No Data, No Query, No Retraining
Oct 09, 2025



Cardinality estimation is a fundamental task in database systems and plays a critical role in query optimization. Despite significant advances in learning-based cardinality estimation methods, most existing approaches remain difficult to generalize to new datasets due to their strong dependence on raw data or queries, thus limiting their practicality in real scenarios. To overcome these challenges, we argue that semantics in the schema may benefit cardinality estimation, and leveraging such semantics may alleviate these dependencies. To this end, we introduce ZeroCard, the first semantics-driven cardinality estimation method that can be applied without any dependence on raw data access, query logs, or retraining on the target database. Specifically, we propose to predict data distributions using schema semantics, thereby avoiding raw data dependence. Then, we introduce a query template-agnostic representation method to alleviate query dependence. Finally, we construct a large-scale query dataset derived from real-world tables and pretrain ZeroCard on it, enabling it to learn cardinality from schema semantics and predicate representations. After pretraining, ZeroCard's parameters can be frozen and applied in an off-the-shelf manner. We conduct extensive experiments to demonstrate the distinct advantages of ZeroCard and show its practical applications in query optimization. Its zero-dependence property significantly facilitates deployment in real-world scenarios.
SIEVE: Effective Filtered Vector Search with Collection of Indexes
Jul 16, 2025Many real-world tasks such as recommending videos with the kids tag can be reduced to finding most similar vectors associated with hard predicates. This task, filtered vector search, is challenging as prior state-of-the-art graph-based (unfiltered) similarity search techniques quickly degenerate when hard constraints are considered. That is, effective graph-based filtered similarity search relies on sufficient connectivity for reaching the most similar items within just a few hops. To consider predicates, recent works propose modifying graph traversal to visit only the items that may satisfy predicates. However, they fail to offer the just-a-few-hops property for a wide range of predicates: they must restrict predicates significantly or lose efficiency if only a small fraction of items satisfy predicates. We propose an opposite approach: instead of constraining traversal, we build many indexes each serving different predicate forms. For effective construction, we devise a three-dimensional analytical model capturing relationships among index size, search time, and recall, with which we follow a workload-aware approach to pack as many useful indexes as possible into a collection. At query time, the analytical model is employed yet again to discern the one that offers the fastest search at a given recall. We show superior performance and support on datasets with varying selectivities and forms: our approach achieves up to 8.06x speedup while having as low as 1% build time versus other indexes, with less than 2.15x memory of a standard HNSW graph and modest knowledge of past workloads.
Towards VM Rescheduling Optimization Through Deep Reinforcement Learning
May 23, 2025Modern industry-scale data centers need to manage a large number of virtual machines (VMs). Due to the continual creation and release of VMs, many small resource fragments are scattered across physical machines (PMs). To handle these fragments, data centers periodically reschedule some VMs to alternative PMs, a practice commonly referred to as VM rescheduling. Despite the increasing importance of VM rescheduling as data centers grow in size, the problem remains understudied. We first show that, unlike most combinatorial optimization tasks, the inference time of VM rescheduling algorithms significantly influences their performance, due to dynamic VM state changes during this period. This causes existing methods to scale poorly. Therefore, we develop a reinforcement learning system for VM rescheduling, VM2RL, which incorporates a set of customized techniques, such as a two-stage framework that accommodates diverse constraints and workload conditions, a feature extraction module that captures relational information specific to rescheduling, as well as a risk-seeking evaluation enabling users to optimize the trade-off between latency and accuracy. We conduct extensive experiments with data from an industry-scale data center. Our results show that VM2RL can achieve a performance comparable to the optimal solution but with a running time of seconds. Code and datasets are open-sourced: https://github.com/zhykoties/VMR2L_eurosys, https://drive.google.com/drive/folders/1PfRo1cVwuhH30XhsE2Np3xqJn2GpX5qy.
Coop-WD: Cooperative Perception with Weighting and Denoising for Robust V2V Communication
May 06, 2025Cooperative perception, leveraging shared information from multiple vehicles via vehicle-to-vehicle (V2V) communication, plays a vital role in autonomous driving to alleviate the limitation of single-vehicle perception. Existing works have explored the effects of V2V communication impairments on perception precision, but they lack generalization to different levels of impairments. In this work, we propose a joint weighting and denoising framework, Coop-WD, to enhance cooperative perception subject to V2V channel impairments. In this framework, the self-supervised contrastive model and the conditional diffusion probabilistic model are adopted hierarchically for vehicle-level and pixel-level feature enhancement. An efficient variant model, Coop-WD-eco, is proposed to selectively deactivate denoising to reduce processing overhead. Rician fading, non-stationarity, and time-varying distortion are considered. Simulation results demonstrate that the proposed Coop-WD outperforms conventional benchmarks in all types of channels. Qualitative analysis with visual examples further proves the superiority of our proposed method. The proposed Coop-WD-eco achieves up to 50% reduction in computational cost under severe distortion while maintaining comparable accuracy as channel conditions improve.
PLM4NDV: Minimizing Data Access for Number of Distinct Values Estimation with Pre-trained Language Models
Apr 01, 2025



Number of Distinct Values (NDV) estimation of a multiset/column is a basis for many data management tasks, especially within databases. Despite decades of research, most existing methods require either a significant amount of samples through uniform random sampling or access to the entire column to produce estimates, leading to substantial data access costs and potentially ineffective estimations in scenarios with limited data access. In this paper, we propose leveraging semantic information, i.e., schema, to address these challenges. The schema contains rich semantic information that can benefit the NDV estimation. To this end, we propose PLM4NDV, a learned method incorporating Pre-trained Language Models (PLMs) to extract semantic schema information for NDV estimation. Specifically, PLM4NDV leverages the semantics of the target column and the corresponding table to gain a comprehensive understanding of the column's meaning. By using the semantics, PLM4NDV reduces data access costs, provides accurate NDV estimation, and can even operate effectively without any data access. Extensive experiments on a large-scale real-world dataset demonstrate the superiority of PLM4NDV over baseline methods. Our code is available at https://github.com/bytedance/plm4ndv.
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Mar 10, 2025
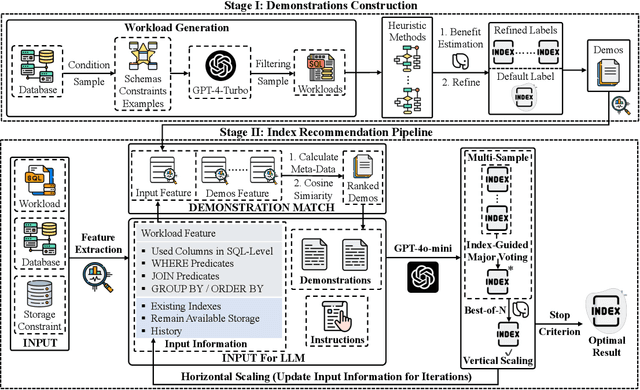


Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
Language-based Audio Retrieval with Co-Attention Networks
Dec 30, 2024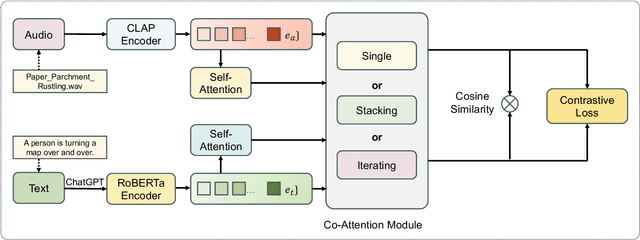
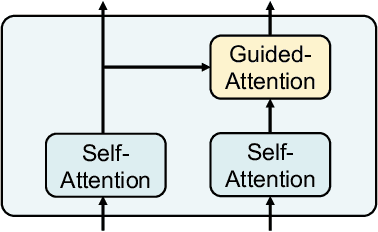
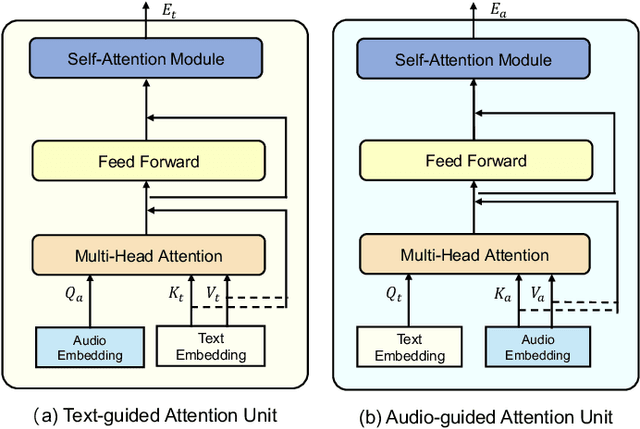
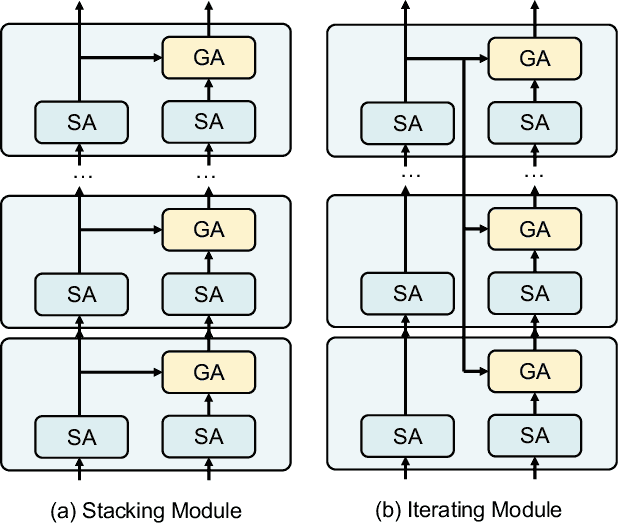
In recent years, user-generated audio content has proliferated across various media platforms, creating a growing need for efficient retrieval methods that allow users to search for audio clips using natural language queries. This task, known as language-based audio retrieval, presents significant challenges due to the complexity of learning semantic representations from heterogeneous data across both text and audio modalities. In this work, we introduce a novel framework for the language-based audio retrieval task that leverages co-attention mechanismto jointly learn meaningful representations from both modalities. To enhance the model's ability to capture fine-grained cross-modal interactions, we propose a cascaded co-attention architecture, where co-attention modules are stacked or iterated to progressively refine the semantic alignment between text and audio. Experiments conducted on two public datasets show that the proposed method can achieve better performance than the state-of-the-art method. Specifically, our best performed co-attention model achieves a 16.6% improvement in mean Average Precision on Clotho dataset, and a 15.1% improvement on AudioCaps.
Clutter Resilient Occlusion Avoidance for Tightly-Coupled Motion-Assisted Detection
Dec 24, 2024



Occlusion is a key factor leading to detection failures. This paper proposes a motion-assisted detection (MAD) method that actively plans an executable path, for the robot to observe the target at a new viewpoint with potentially reduced occlusion. In contrast to existing MAD approaches that may fail in cluttered environments, the proposed framework is robust in such scenarios, therefore termed clutter resilient occlusion avoidance (CROA). The crux to CROA is to minimize the occlusion probability under polyhedron-based collision avoidance constraints via the convex-concave procedure and duality-based bilevel optimization. The system implementation supports lidar-based MAD with intertwined execution of learning-based detection and optimization-based planning. Experiments show that CROA outperforms various MAD schemes under a sparse convolutional neural network detector, in terms of point density, occlusion ratio, and detection error, in a multi-lane urban driving scenario.