 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Paper and Code

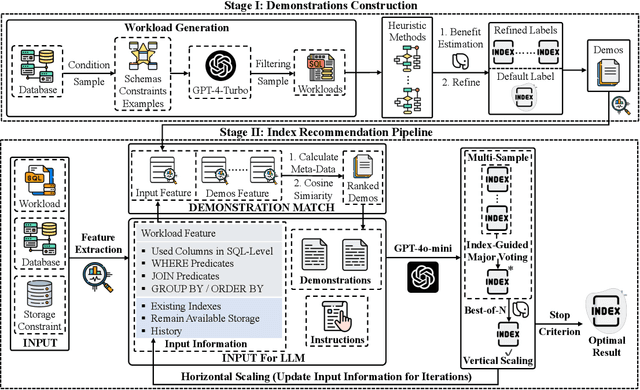


Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.