 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemEmo: Evaluating Emotion in Memory Systems of Agents
Feb 27, 2026Memory systems address the challenge of context loss in Large Language Model during prolonged interactions. However, compared to human cognition, the efficacy of these systems in processing emotion-related information remains inconclusive. To address this gap, we propose an emotion-enhanced memory evaluation benchmark to assess the performance of mainstream and state-of-the-art memory systems in handling affective information. We developed the \textbf{H}uman-\textbf{L}ike \textbf{M}emory \textbf{E}motion (\textbf{HLME}) dataset, which evaluates memory systems across three dimensions: emotional information extraction, emotional memory updating, and emotional memory question answering. Experimental results indicate that none of the evaluated systems achieve robust performance across all three tasks. Our findings provide an objective perspective on the current deficiencies of memory systems in processing emotional memories and suggest a new trajectory for future research and system optimization.
TableCache: Primary Foreign Key Guided KV Cache Precomputation for Low Latency Text-to-SQL
Jan 13, 2026In Text-to-SQL tasks, existing LLM-based methods often include extensive database schemas in prompts, leading to long context lengths and increased prefilling latency. While user queries typically focus on recurrent table sets-offering an opportunity for KV cache sharing across queries-current inference engines, such as SGLang and vLLM, generate redundant prefix cache copies when processing user queries with varying table orders. To address this inefficiency, we propose precomputing table representations as KV caches offline and querying the required ones online. A key aspect of our approach is the computation of table caches while preserving primary foreign key relationships between tables. Additionally, we construct a Table Trie structure to facilitate efficient KV cache lookups during inference. To enhance cache performance, we introduce a cache management system with a query reranking strategy to improve cache hit rates and a computation loading pipeline for parallelizing model inference and cache loading. Experimental results show that our proposed TableCache achieves up to a 3.62x speedup in Time to First Token (TTFT) with negligible performance degradation.
Unsupervised Learning for Class Distribution Mismatch
May 11, 2025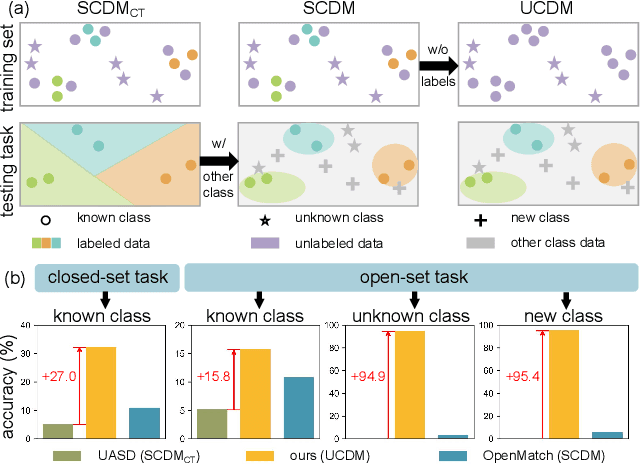

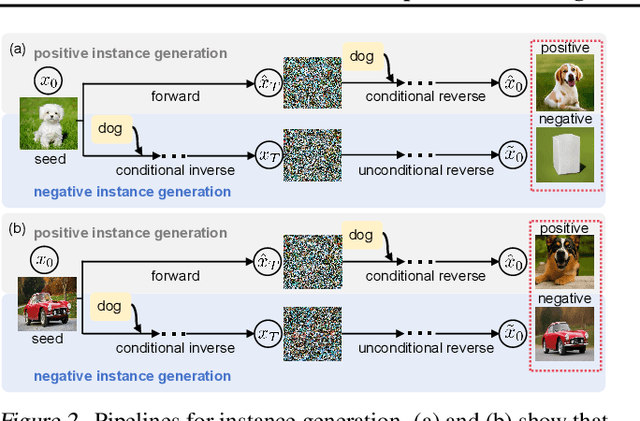

Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
QUAD: Quantization and Parameter-Efficient Tuning of LLM with Activation Decomposition
Mar 25, 2025Large Language Models (LLMs) excel in diverse applications but suffer inefficiency due to massive scale. While quantization reduces computational costs, existing methods degrade accuracy in medium-sized LLMs (e.g., Llama-3-8B) due to activation outliers. To address this, we propose QUAD (Quantization with Activation Decomposition), a framework leveraging Singular Value Decomposition (SVD) to suppress activation outliers for effective 4-bit quantization. QUAD estimates activation singular vectors offline using calibration data to construct an orthogonal transformation matrix P, shifting outliers to additional dimensions in full precision while quantizing rest components to 4-bit. Additionally, QUAD enables parameter-efficient fine-tuning via adaptable full-precision outlier weights, narrowing the accuracy gap between quantized and full-precision models. Experiments demonstrate that QUAD achieves 94% ~ 96% accuracy under W4A4 quantization and 98% accuracy with W4A4/A8 and parameter-efficient fine-tuning for Llama-3 and Qwen-2.5 models. Our code is available at \href{https://github.com/hyx1999/Quad}{repository}.
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Mar 10, 2025
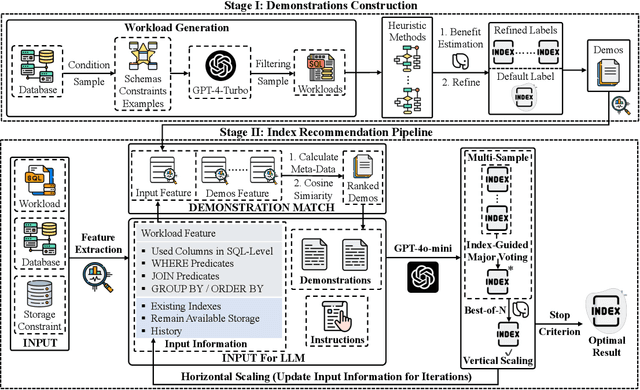


Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
LoRS: Efficient Low-Rank Adaptation for Sparse Large Language Model
Jan 15, 2025Existing low-rank adaptation (LoRA) methods face challenges on sparse large language models (LLMs) due to the inability to maintain sparsity. Recent works introduced methods that maintain sparsity by augmenting LoRA techniques with additional masking mechanisms. Despite these successes, such approaches suffer from an increased memory and computation overhead, which affects efficiency of LoRA methods. In response to this limitation, we introduce LoRS, an innovative method designed to achieve both memory and computation efficiency when fine-tuning sparse LLMs. To mitigate the substantial memory and computation demands associated with preserving sparsity, our approach incorporates strategies of weight recompute and computational graph rearrangement. In addition, we also improve the effectiveness of LoRS through better adapter initialization. These innovations lead to a notable reduction in memory and computation consumption during the fine-tuning phase, all while achieving performance levels that outperform existing LoRA approaches.
Personalized Clustering via Targeted Representation Learning
Dec 18, 2024



Clustering traditionally aims to reveal a natural grouping structure model from unlabeled data. However, this model may not always align with users' preference. In this paper, we propose a personalized clustering method that explicitly performs targeted representation learning by interacting with users via modicum task information (e.g., $\textit{must-link}$ or $\textit{cannot-link}$ pairs) to guide the clustering direction. We query users with the most informative pairs, i.e., those pairs most hard to cluster and those most easy to miscluster, to facilitate the representation learning in terms of the clustering preference. Moreover, by exploiting attention mechanism, the targeted representation is learned and augmented. By leveraging the targeted representation and constrained constrastive loss as well, personalized clustering is obtained. Theoretically, we verify that the risk of personalized clustering is tightly bounded, guaranteeing that active queries to users do mitigate the clustering risk. Experimentally, extensive results show that our method performs well across different clustering tasks and datasets, even with a limited number of queries.
SAM Decoding: Speculative Decoding via Suffix Automaton
Nov 16, 2024Large Language Models (LLMs) have revolutionized natural language processing by unifying tasks into text generation, yet their large parameter sizes and autoregressive nature limit inference speed. SAM-Decoding addresses this by introducing a novel retrieval-based speculative decoding method that uses a suffix automaton for efficient and accurate draft generation. Unlike n-gram matching used by the existing method, SAM-Decoding finds the longest suffix match in generating text and text corpuss, achieving an average time complexity of $O(1)$ per generation step. SAM-Decoding constructs static and dynamic suffix automatons for the text corpus and input prompts, respectively, enabling fast and precise draft generation. Meanwhile, it is designed as an approach that can be combined with existing methods, allowing SAM-Decoding to adaptively select a draft generation strategy based on the matching length, thus increasing the inference speed of the LLM. When combined with Token Recycling, evaluations show SAM-Decoding outperforms existing model-free methods, achieving a speedup of $2.27\times$ over autoregressive decoding on Spec-Bench. When combined with EAGLE2, it reaches a speedup of $2.49\times$, surpassing all current approaches. Our code is available at https://github.com/hyx1999/SAM-Decoding.
Scaling Law for Post-training after Model Pruning
Nov 15, 2024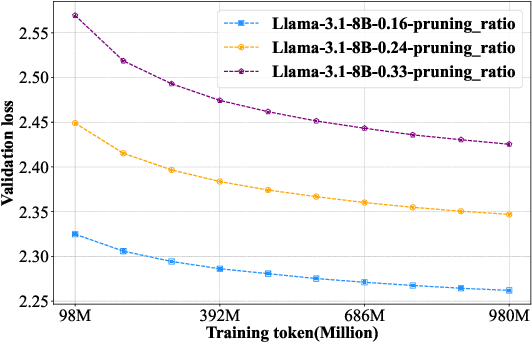
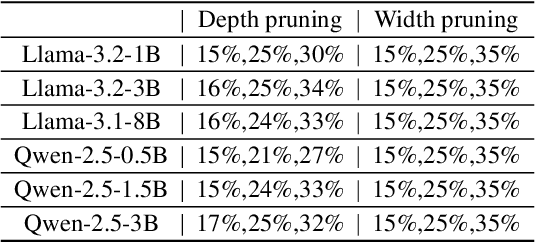
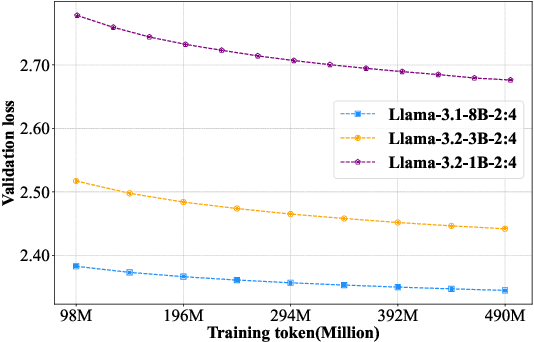
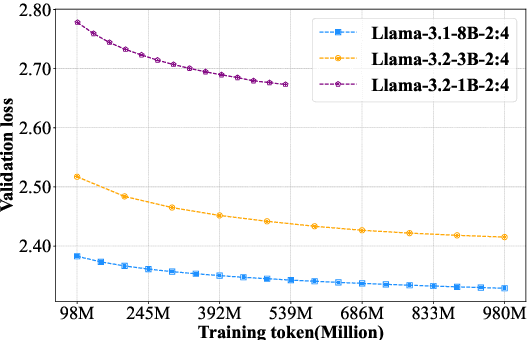
Large language models (LLMs) based on the Transformer architecture are widely employed across various domains and tasks. However, their increasing size imposes significant hardware demands, limiting practical deployment. To mitigate this, model pruning techniques have been developed to create more efficient models while maintaining high performance. Despite this, post-training after pruning is crucial for performance recovery and can be resource-intensive. This paper investigates the post-training requirements of pruned LLMs and introduces a scaling law to determine the optimal amount of post-training data. Post-training experiments with the Llama-3 and Qwen-2.5 series models, pruned using depth pruning, width pruning, and 2:4 semi-structured pruning, show that higher pruning ratios necessitate more post-training data for performance recovery, whereas larger LLMs require less. The proposed scaling law predicts a model's loss based on its parameter counts before and after pruning, as well as the post-training token counts. Furthermore, we find that the scaling law established from smaller LLMs can be reliably extrapolated to larger LLMs. This work provides valuable insights into the post-training of pruned LLMs and offers a practical scaling law for optimizing post-training data usage.