 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Sampling via Exploiting Local Transition Coherence
Mar 12, 2025Text-based diffusion models have made significant breakthroughs in generating high-quality images and videos from textual descriptions. However, the lengthy sampling time of the denoising process remains a significant bottleneck in practical applications. Previous methods either ignore the statistical relationships between adjacent steps or rely on attention or feature similarity between them, which often only works with specific network structures. To address this issue, we discover a new statistical relationship in the transition operator between adjacent steps, focusing on the relationship of the outputs from the network. This relationship does not impose any requirements on the network structure. Based on this observation, we propose a novel training-free acceleration method called LTC-Accel, which uses the identified relationship to estimate the current transition operator based on adjacent steps. Due to no specific assumptions regarding the network structure, LTC-Accel is applicable to almost all diffusion-based methods and orthogonal to almost all existing acceleration techniques, making it easy to combine with them. Experimental results demonstrate that LTC-Accel significantly speeds up sampling in text-to-image and text-to-video synthesis while maintaining competitive sample quality. Specifically, LTC-Accel achieves a speedup of 1.67-fold in Stable Diffusion v2 and a speedup of 1.55-fold in video generation models. When combined with distillation models, LTC-Accel achieves a remarkable 10-fold speedup in video generation, allowing real-time generation of more than 16FPS.
Is Large Language Model Good at Database Knob Tuning? A Comprehensive Experimental Evaluation
Aug 05, 2024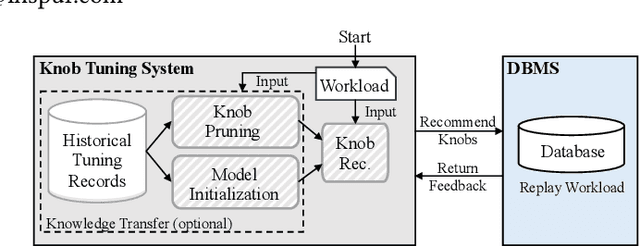


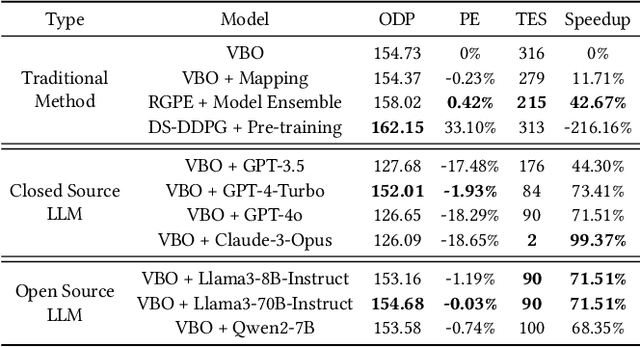
Knob tuning plays a crucial role in optimizing databases by adjusting knobs to enhance database performance. However, traditional tuning methods often follow a Try-Collect-Adjust approach, proving inefficient and database-specific. Moreover, these methods are often opaque, making it challenging for DBAs to grasp the underlying decision-making process. The emergence of large language models (LLMs) like GPT-4 and Claude-3 has excelled in complex natural language tasks, yet their potential in database knob tuning remains largely unexplored. This study harnesses LLMs as experienced DBAs for knob-tuning tasks with carefully designed prompts. We identify three key subtasks in the tuning system: knob pruning, model initialization, and knob recommendation, proposing LLM-driven solutions to replace conventional methods for each subtask. We conduct extensive experiments to compare LLM-driven approaches against traditional methods across the subtasks to evaluate LLMs' efficacy in the knob tuning domain. Furthermore, we explore the adaptability of LLM-based solutions in diverse evaluation settings, encompassing new benchmarks, database engines, and hardware environments. Our findings reveal that LLMs not only match or surpass traditional methods but also exhibit notable interpretability by generating responses in a coherent ``chain-of-thought'' manner. We further observe that LLMs exhibit remarkable generalizability through simple adjustments in prompts, eliminating the necessity for additional training or extensive code modifications. Drawing insights from our experimental findings, we identify several opportunities for future research aimed at advancing the utilization of LLMs in the realm of database management.