 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHA2MLA-VLM: Enabling DeepSeek's Economical Multi-Head Latent Attention across Vision-Language Models
Jan 16, 2026As vision-language models (VLMs) tackle increasingly complex and multimodal tasks, the rapid growth of Key-Value (KV) cache imposes significant memory and computational bottlenecks during inference. While Multi-Head Latent Attention (MLA) offers an effective means to compress the KV cache and accelerate inference, adapting existing VLMs to the MLA architecture without costly pretraining remains largely unexplored. In this work, we present MHA2MLA-VLM, a parameter-efficient and multimodal-aware framework for converting off-the-shelf VLMs to MLA. Our approach features two core techniques: (1) a modality-adaptive partial-RoPE strategy that supports both traditional and multimodal settings by selectively masking nonessential dimensions, and (2) a modality-decoupled low-rank approximation method that independently compresses the visual and textual KV spaces. Furthermore, we introduce parameter-efficient fine-tuning to minimize adaptation cost and demonstrate that minimizing output activation error, rather than parameter distance, substantially reduces performance loss. Extensive experiments on three representative VLMs show that MHA2MLA-VLM restores original model performance with minimal supervised data, significantly reduces KV cache footprint, and integrates seamlessly with KV quantization.
Muse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control
Jan 08, 2026Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling
Oct 01, 2025Assessing the perceptual quality of synthetic speech is crucial for guiding the development and refinement of speech generation models. However, it has traditionally relied on human subjective ratings such as the Mean Opinion Score (MOS), which depend on manual annotations and often suffer from inconsistent rating standards and poor reproducibility. To address these limitations, we introduce MOS-RMBench, a unified benchmark that reformulates diverse MOS datasets into a preference-comparison setting, enabling rigorous evaluation across different datasets. Building on MOS-RMBench, we systematically construct and evaluate three paradigms for reward modeling: scalar reward models, semi-scalar reward models, and generative reward models (GRMs). Our experiments reveal three key findings: (1) scalar models achieve the strongest overall performance, consistently exceeding 74% accuracy; (2) most models perform considerably worse on synthetic speech than on human speech; and (3) all models struggle on pairs with very small MOS differences. To improve performance on these challenging pairs, we propose a MOS-aware GRM that incorporates an MOS-difference-based reward function, enabling the model to adaptively scale rewards according to the difficulty of each sample pair. Experimental results show that the MOS-aware GRM significantly improves fine-grained quality discrimination and narrows the gap with scalar models on the most challenging cases. We hope this work will establish both a benchmark and a methodological framework to foster more rigorous and scalable research in automatic speech quality assessment.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025
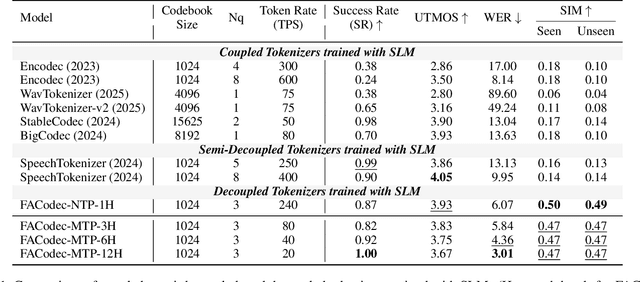
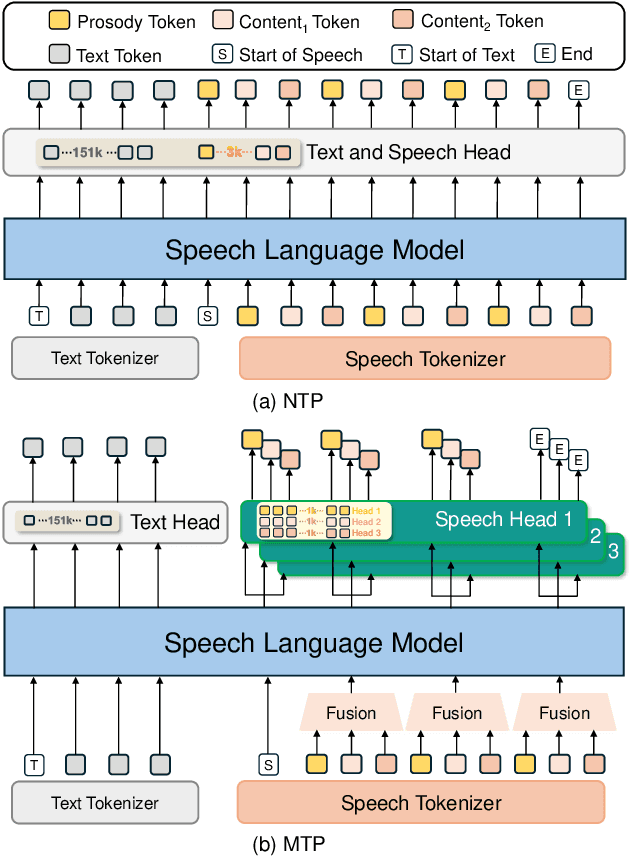
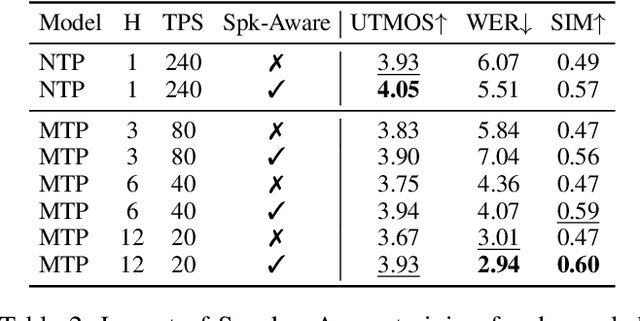
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Protein Design with Dynamic Protein Vocabulary
May 25, 2025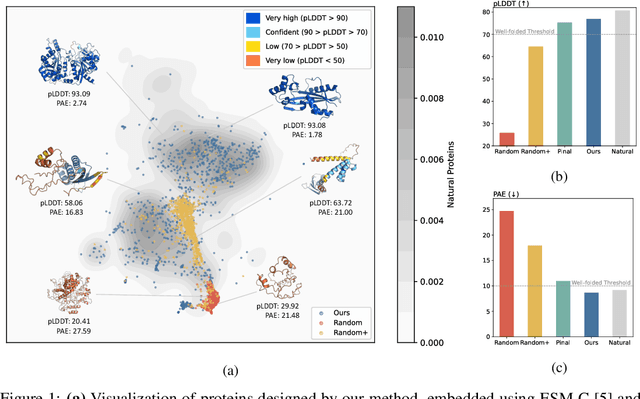
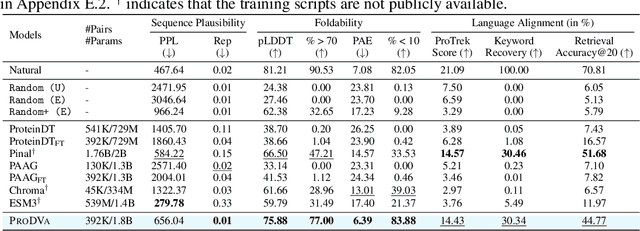
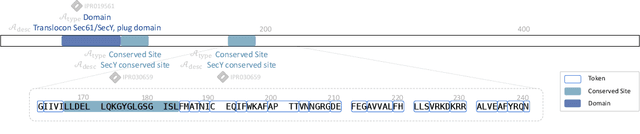
Protein design is a fundamental challenge in biotechnology, aiming to design novel sequences with specific functions within the vast space of possible proteins. Recent advances in deep generative models have enabled function-based protein design from textual descriptions, yet struggle with structural plausibility. Inspired by classical protein design methods that leverage natural protein structures, we explore whether incorporating fragments from natural proteins can enhance foldability in generative models. Our empirical results show that even random incorporation of fragments improves foldability. Building on this insight, we introduce ProDVa, a novel protein design approach that integrates a text encoder for functional descriptions, a protein language model for designing proteins, and a fragment encoder to dynamically retrieve protein fragments based on textual functional descriptions. Experimental results demonstrate that our approach effectively designs protein sequences that are both functionally aligned and structurally plausible. Compared to state-of-the-art models, ProDVa achieves comparable function alignment using less than 0.04% of the training data, while designing significantly more well-folded proteins, with the proportion of proteins having pLDDT above 70 increasing by 7.38% and those with PAE below 10 increasing by 9.6%.
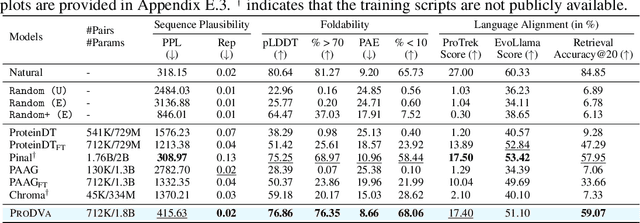
PDFBench: A Benchmark for De novo Protein Design from Function
May 25, 2025In recent years, while natural language processing and multimodal learning have seen rapid advancements, the field of de novo protein design has also experienced significant growth. However, most current methods rely on proprietary datasets and evaluation rubrics, making fair comparisons between different approaches challenging. Moreover, these methods often employ evaluation metrics that capture only a subset of the desired properties of designed proteins, lacking a comprehensive assessment framework. To address these, we introduce PDFBench, the first comprehensive benchmark for evaluating de novo protein design from function. PDFBench supports two tasks: description-guided design and keyword-guided design. To ensure fair and multifaceted evaluation, we compile 22 metrics covering sequence plausibility, structural fidelity, and language-protein alignment, along with measures of novelty and diversity. We evaluate five state-of-the-art baselines, revealing their respective strengths and weaknesses across tasks. Finally, we analyze inter-metric correlations, exploring the relationships between four categories of metrics, and offering guidelines for metric selection. PDFBench establishes a unified framework to drive future advances in function-driven de novo protein design.
Effective Length Extrapolation via Dimension-Wise Positional Embeddings Manipulation
Apr 26, 2025Large Language Models (LLMs) often struggle to process and generate coherent context when the number of input tokens exceeds the pre-trained length. Recent advancements in long-context extension have significantly expanded the context window of LLMs but require expensive overhead to train the large-scale models with longer context. In this work, we propose Dimension-Wise Positional Embeddings Manipulation (DPE), a training-free framework to extrapolate the context window of LLMs by diving into RoPE's different hidden dimensions. Instead of manipulating all dimensions equally, DPE detects the effective length for every dimension and finds the key dimensions for context extension. We reuse the original position indices with their embeddings from the pre-trained model and manipulate the key dimensions' position indices to their most effective lengths. In this way, DPE adjusts the pre-trained models with minimal modifications while ensuring that each dimension reaches its optimal state for extrapolation. DPE significantly surpasses well-known baselines such as YaRN and Self-Extend. DPE enables Llama3-8k 8B to support context windows of 128k tokens without continual training and integrates seamlessly with Flash Attention 2. In addition to its impressive extrapolation capability, DPE also dramatically improves the models' performance within training length, such as Llama3.1 70B, by over 18 points on popular long-context benchmarks RULER. When compared with commercial models, Llama 3.1 70B with DPE even achieves better performance than GPT-4-128K.
Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.