 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Layer's Trash is Another Layer's Treasure: Adaptive Layer-wise Visual Token Selection in LVLMs
Jun 12, 2026Large Vision-Language Models (LVLMs) have achieved remarkable success across diverse multimodal tasks, yet their practical deployment remains constrained by the computational burden arising from lengthy visual tokens. While visual token pruning has emerged as a promising solution, existing methods suffer from a fundamental limitation: once tokens are pruned at a specific layer, they become inaccessible to all subsequent layers, leading to premature information loss that can compromise model performance. Through empirical studies, we observe that different layers exhibit distinct visual region focus, indicating a varying optimal token subset across layers. Motivated by this insight, we propose Adaptive Layer-wise Visual Token Selection (ALVTS), a novel framework that breaks away from the conventional static token pruning paradigm. ALVTS incorporates a lightweight token selector to identify and route important tokens for further processing, while allowing less important tokens to skip the layer, thus minimizing computational redundancy. These two streams of tokens are seamlessly reintegrated before being fed into subsequent layers, facilitating adaptive compression across the entire model. Grounded in our importance consistency constrained low-rank approximation, the proposed token selection module closely emulates the full attention mechanism, effectively capturing its essential patterns without requiring model retraining. Extensive experiments on LLaVA-1.5, LLaVA-NeXT, and Qwen2.5-VL validate the effectiveness of our method. With an 89% token compression ratio, ALVTS retains 96.7% of the original model's accuracy, achieving a superior efficiency-accuracy trade-off for LVLM inference.
1+1>2: A Synergistic Sparse and Low-Rank Compression Method for Large Language Models
Oct 30, 2025


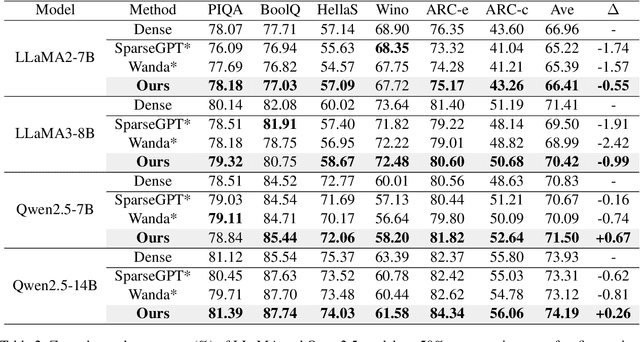
Large Language Models (LLMs) have demonstrated remarkable proficiency in language comprehension and generation; however, their widespread adoption is constrained by substantial bandwidth and computational demands. While pruning and low-rank approximation have each demonstrated promising performance individually, their synergy for LLMs remains underexplored. We introduce \underline{S}ynergistic \underline{S}parse and \underline{L}ow-Rank \underline{C}ompression (SSLC) methods for LLMs, which leverages the strengths of both techniques: low-rank approximation compresses the model by retaining its essential structure with minimal information loss, whereas sparse optimization eliminates non-essential weights, preserving those crucial for generalization. Based on theoretical analysis, we first formulate the low-rank approximation and sparse optimization as a unified problem and solve it by iterative optimization algorithm. Experiments on LLaMA and Qwen2.5 models (7B-70B) show that SSLC, without any additional training steps, consistently surpasses standalone methods, achieving state-of-the-arts results. Notably, SSLC compresses Qwen2.5 by 50\% with no performance drop and achieves at least 1.63$\times$ speedup, offering a practical solution for efficient LLM deployment.
Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.
Unified Normalization for Accelerating and Stabilizing Transformers
Aug 02, 2022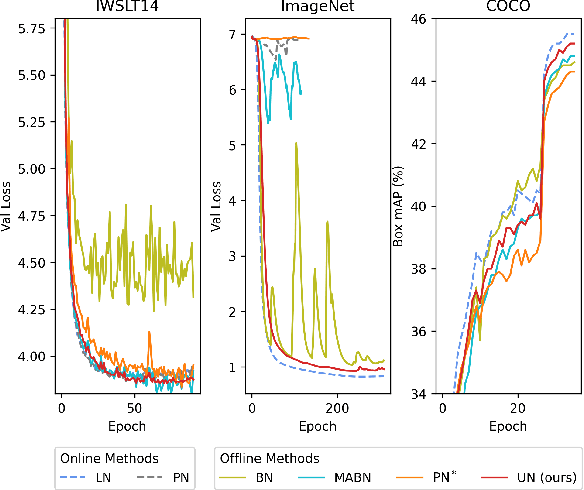
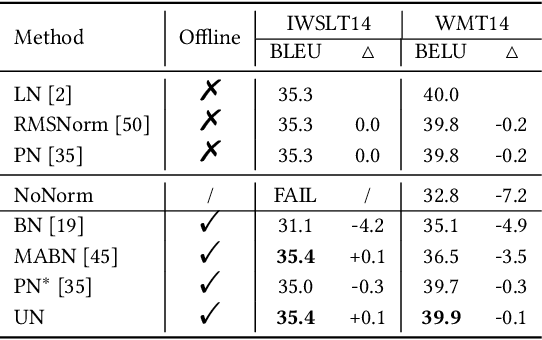
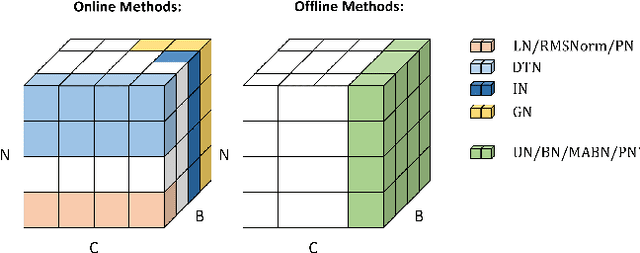
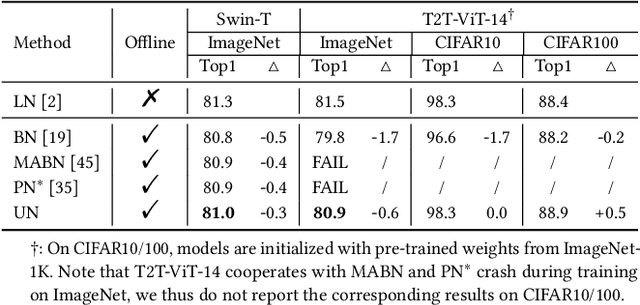
Solid results from Transformers have made them prevailing architectures in various natural language and vision tasks. As a default component in Transformers, Layer Normalization (LN) normalizes activations within each token to boost the robustness. However, LN requires on-the-fly statistics calculation in inference as well as division and square root operations, leading to inefficiency on hardware. What is more, replacing LN with other hardware-efficient normalization schemes (e.g., Batch Normalization) results in inferior performance, even collapse in training. We find that this dilemma is caused by abnormal behaviors of activation statistics, including large fluctuations over iterations and extreme outliers across layers. To tackle these issues, we propose Unified Normalization (UN), which can speed up the inference by being fused with other linear operations and achieve comparable performance on par with LN. UN strives to boost performance by calibrating the activation and gradient statistics with a tailored fluctuation smoothing strategy. Meanwhile, an adaptive outlier filtration strategy is applied to avoid collapse in training whose effectiveness is theoretically proved and experimentally verified in this paper. We demonstrate that UN can be an efficient drop-in alternative to LN by conducting extensive experiments on language and vision tasks. Besides, we evaluate the efficiency of our method on GPU. Transformers equipped with UN enjoy about 31% inference speedup and nearly 18% memory reduction. Code will be released at https://github.com/hikvision-research/Unified-Normalization.
End-to-End Modeling via Information Tree for One-Shot Natural Language Spatial Video Grounding
Mar 15, 2022
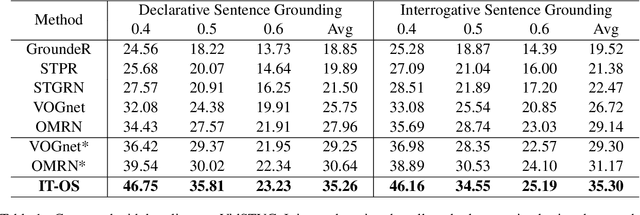
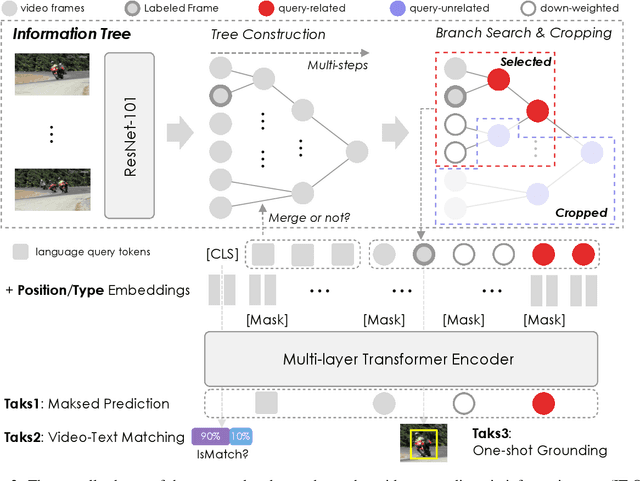
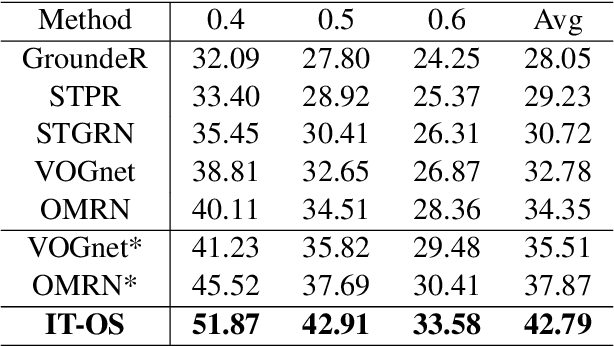
Natural language spatial video grounding aims to detect the relevant objects in video frames with descriptive sentences as the query. In spite of the great advances, most existing methods rely on dense video frame annotations, which require a tremendous amount of human effort. To achieve effective grounding under a limited annotation budget, we investigate one-shot video grounding, and learn to ground natural language in all video frames with solely one frame labeled, in an end-to-end manner. One major challenge of end-to-end one-shot video grounding is the existence of videos frames that are either irrelevant to the language query or the labeled frames. Another challenge relates to the limited supervision, which might result in ineffective representation learning. To address these challenges, we designed an end-to-end model via Information Tree for One-Shot video grounding (IT-OS). Its key module, the information tree, can eliminate the interference of irrelevant frames based on branch search and branch cropping techniques. In addition, several self-supervised tasks are proposed based on the information tree to improve the representation learning under insufficient labeling. Experiments on the benchmark dataset demonstrate the effectiveness of our model.
UWC: Unit-wise Calibration Towards Rapid Network Compression
Jan 17, 2022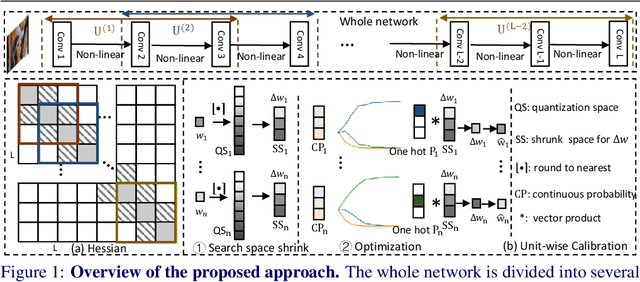
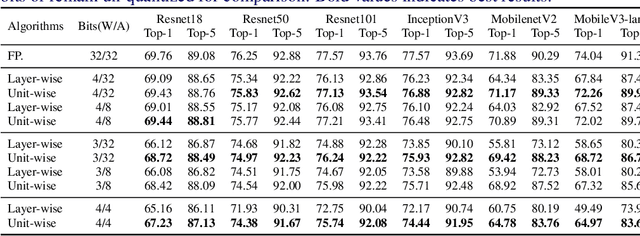
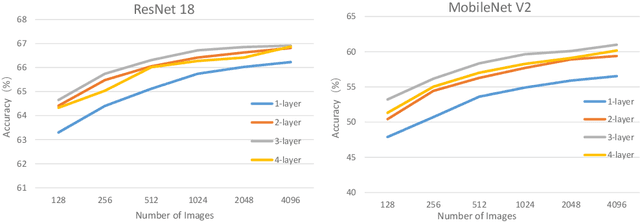
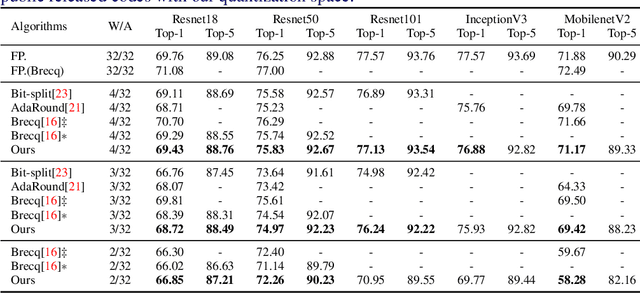
This paper introduces a post-training quantization~(PTQ) method achieving highly efficient Convolutional Neural Network~ (CNN) quantization with high performance. Previous PTQ methods usually reduce compression error via performing layer-by-layer parameters calibration. However, with lower representational ability of extremely compressed parameters (e.g., the bit-width goes less than 4), it is hard to eliminate all the layer-wise errors. This work addresses this issue via proposing a unit-wise feature reconstruction algorithm based on an observation of second order Taylor series expansion of the unit-wise error. It indicates that leveraging the interaction between adjacent layers' parameters could compensate layer-wise errors better. In this paper, we define several adjacent layers as a Basic-Unit, and present a unit-wise post-training algorithm which can minimize quantization error. This method achieves near-original accuracy on ImageNet and COCO when quantizing FP32 models to INT4 and INT3.
Scene-Adaptive Attention Network for Crowd Counting
Dec 31, 2021
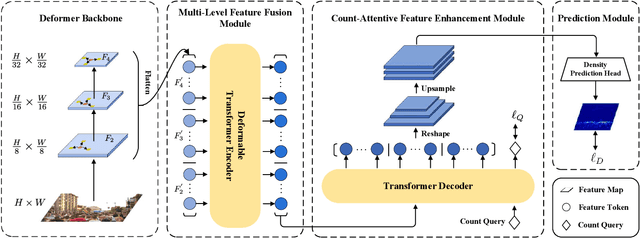
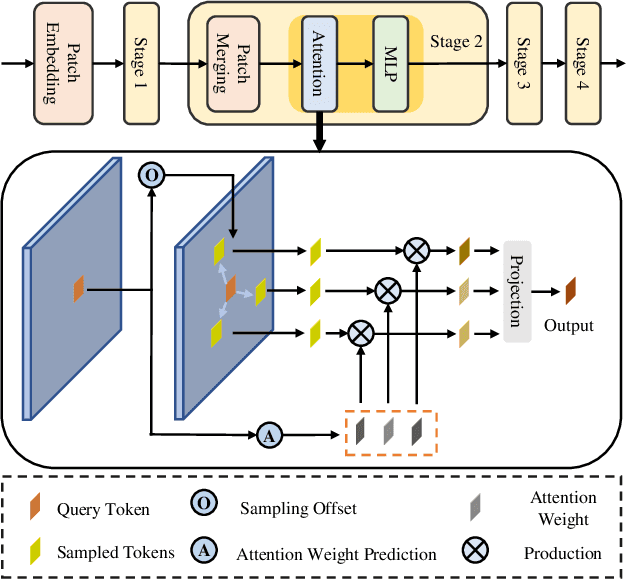
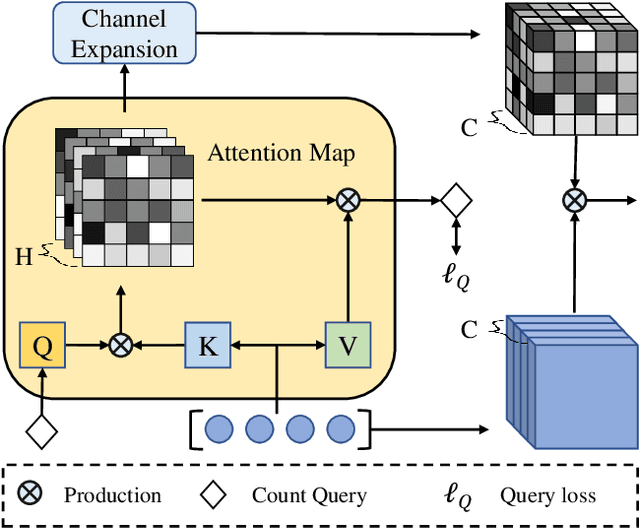
In recent years, significant progress has been made on the research of crowd counting. However, as the challenging scale variations and complex scenes existed in crowds, neither traditional convolution networks nor recent Transformer architectures with fixed-size attention could handle the task well. To address this problem, this paper proposes a scene-adaptive attention network, termed SAANet. First of all, we design a deformable attention in-built Transformer backbone, which learns adaptive feature representations with deformable sampling locations and dynamic attention weights. Then we propose the multi-level feature fusion and count-attentive feature enhancement modules further, to strengthen feature representation under the global image context. The learned representations could attend to the foreground and are adaptive to different scales of crowds. We conduct extensive experiments on four challenging crowd counting benchmarks, demonstrating that our method achieves state-of-the-art performance. Especially, our method currently ranks No.1 on the public leaderboard of the NWPU-Crowd benchmark. We hope our method could be a strong baseline to support future research in crowd counting. The source code will be released to the community.
SOIT: Segmenting Objects with Instance-Aware Transformers
Dec 23, 2021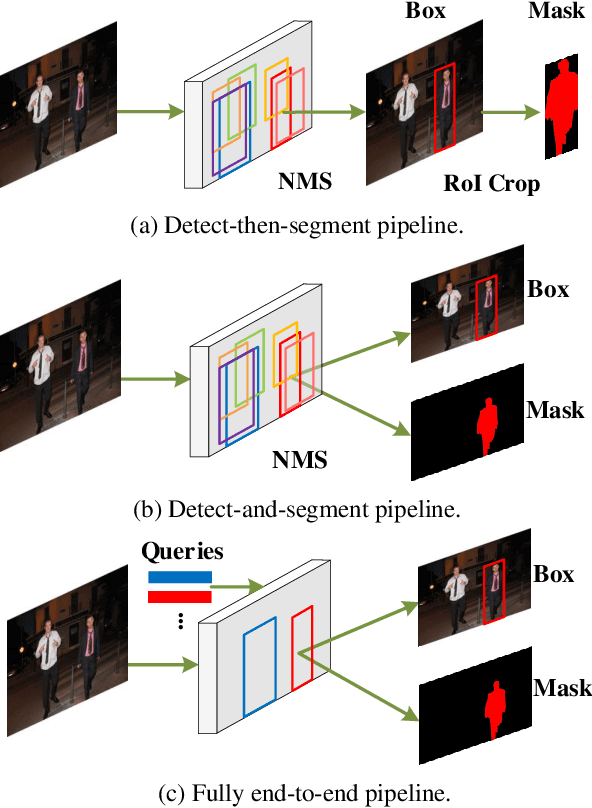
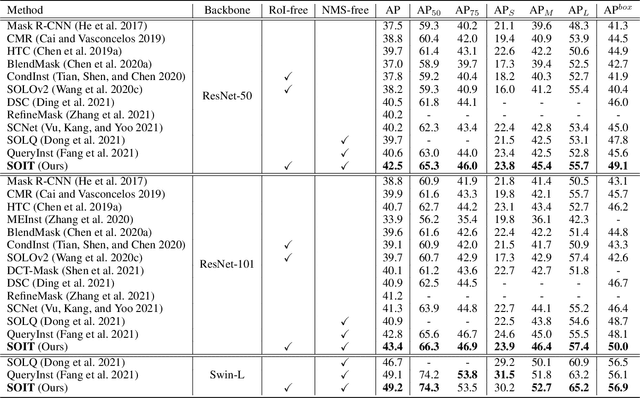
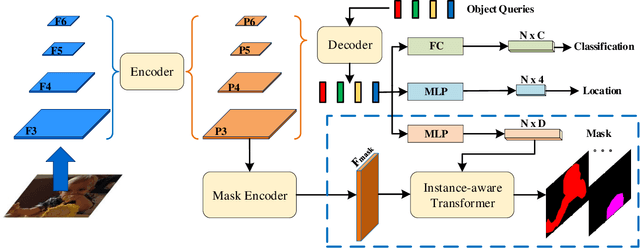
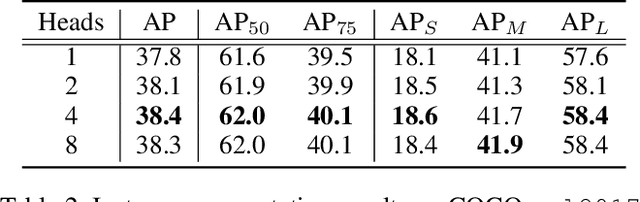
This paper presents an end-to-end instance segmentation framework, termed SOIT, that Segments Objects with Instance-aware Transformers. Inspired by DETR \cite{carion2020end}, our method views instance segmentation as a direct set prediction problem and effectively removes the need for many hand-crafted components like RoI cropping, one-to-many label assignment, and non-maximum suppression (NMS). In SOIT, multiple queries are learned to directly reason a set of object embeddings of semantic category, bounding-box location, and pixel-wise mask in parallel under the global image context. The class and bounding-box can be easily embedded by a fixed-length vector. The pixel-wise mask, especially, is embedded by a group of parameters to construct a lightweight instance-aware transformer. Afterward, a full-resolution mask is produced by the instance-aware transformer without involving any RoI-based operation. Overall, SOIT introduces a simple single-stage instance segmentation framework that is both RoI- and NMS-free. Experimental results on the MS COCO dataset demonstrate that SOIT outperforms state-of-the-art instance segmentation approaches significantly. Moreover, the joint learning of multiple tasks in a unified query embedding can also substantially improve the detection performance. Code is available at \url{https://github.com/yuxiaodongHRI/SOIT}.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021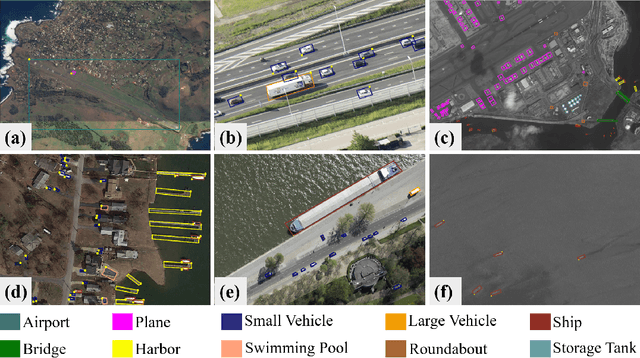

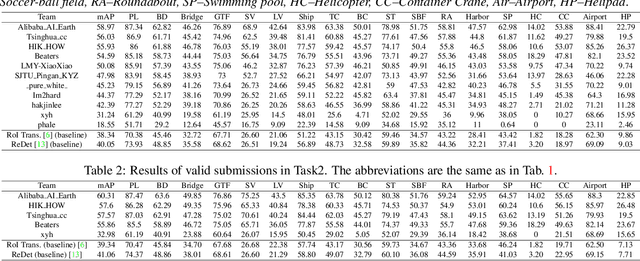
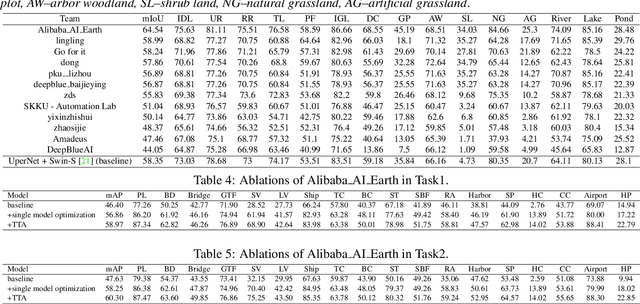
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.
InsPose: Instance-Aware Networks for Single-Stage Multi-Person Pose Estimation
Jul 20, 2021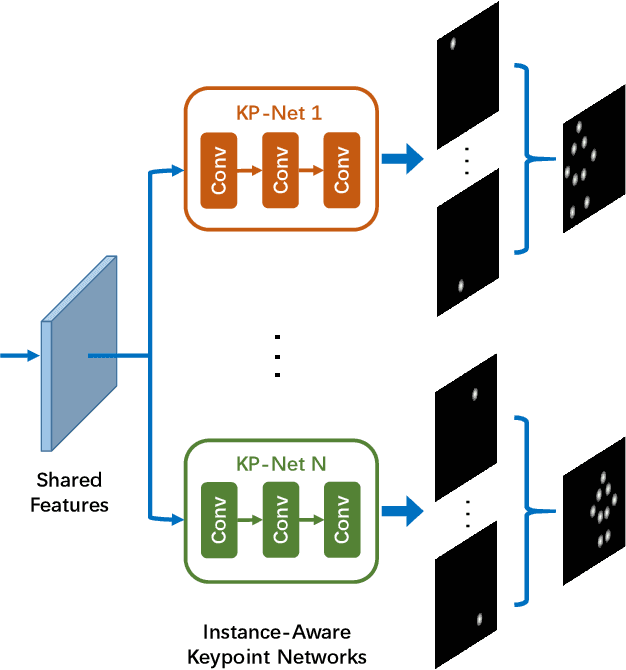


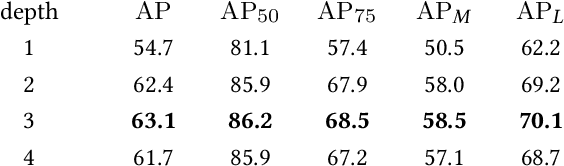
Multi-person pose estimation is an attractive and challenging task. Existing methods are mostly based on two-stage frameworks, which include top-down and bottom-up methods. Two-stage methods either suffer from high computational redundancy for additional person detectors or they need to group keypoints heuristically after predicting all the instance-agnostic keypoints. The single-stage paradigm aims to simplify the multi-person pose estimation pipeline and receives a lot of attention. However, recent single-stage methods have the limitation of low performance due to the difficulty of regressing various full-body poses from a single feature vector. Different from previous solutions that involve complex heuristic designs, we present a simple yet effective solution by employing instance-aware dynamic networks. Specifically, we propose an instance-aware module to adaptively adjust (part of) the network parameters for each instance. Our solution can significantly increase the capacity and adaptive-ability of the network for recognizing various poses, while maintaining a compact end-to-end trainable pipeline. Extensive experiments on the MS-COCO dataset demonstrate that our method achieves significant improvement over existing single-stage methods, and makes a better balance of accuracy and efficiency compared to the state-of-the-art two-stage approaches.
* arXiv admin note: text overlap with arXiv:1911.07451, arXiv:2003.05664, arXiv:2102.03026 by other authors