 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Object Detectors With Global Knowledge
Oct 17, 2022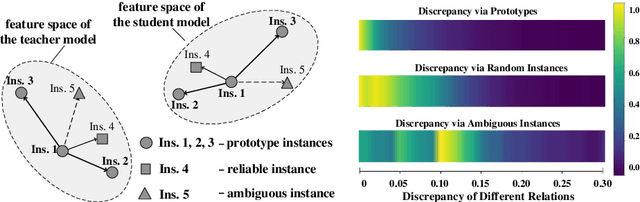
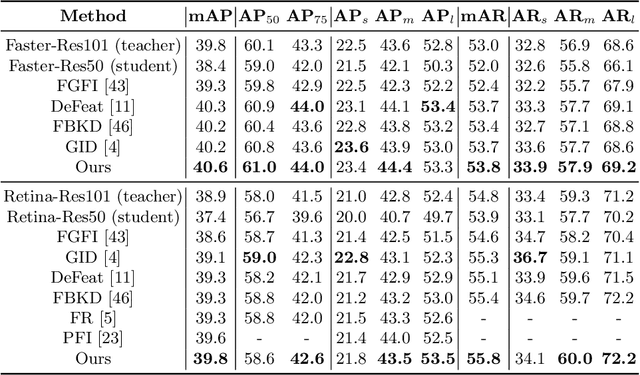
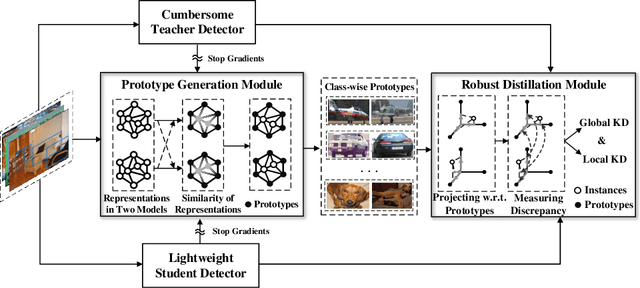
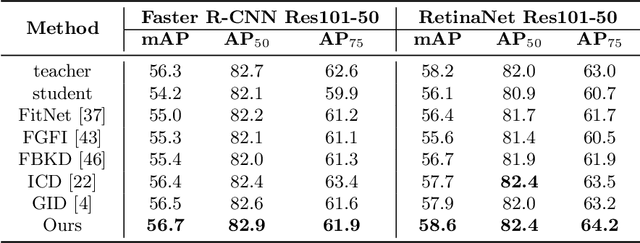
Knowledge distillation learns a lightweight student model that mimics a cumbersome teacher. Existing methods regard the knowledge as the feature of each instance or their relations, which is the instance-level knowledge only from the teacher model, i.e., the local knowledge. However, the empirical studies show that the local knowledge is much noisy in object detection tasks, especially on the blurred, occluded, or small instances. Thus, a more intrinsic approach is to measure the representations of instances w.r.t. a group of common basis vectors in the two feature spaces of the teacher and the student detectors, i.e., global knowledge. Then, the distilling algorithm can be applied as space alignment. To this end, a novel prototype generation module (PGM) is proposed to find the common basis vectors, dubbed prototypes, in the two feature spaces. Then, a robust distilling module (RDM) is applied to construct the global knowledge based on the prototypes and filtrate noisy global and local knowledge by measuring the discrepancy of the representations in two feature spaces. Experiments with Faster-RCNN and RetinaNet on PASCAL and COCO datasets show that our method achieves the best performance for distilling object detectors with various backbones, which even surpasses the performance of the teacher model. We also show that the existing methods can be easily combined with global knowledge and obtain further improvement. Code is available: https://github.com/hikvision-research/DAVAR-Lab-ML.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022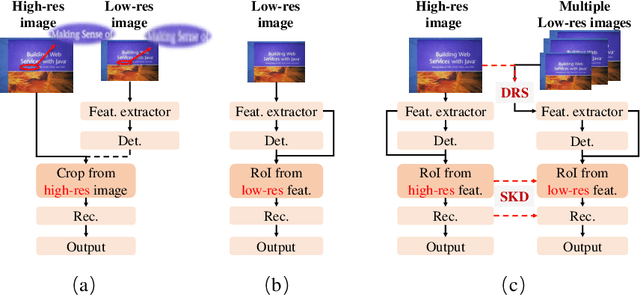
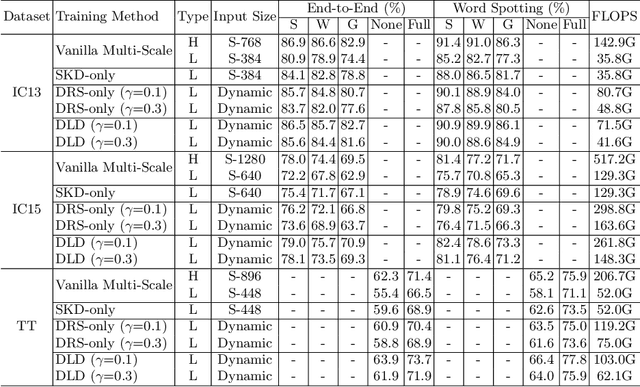
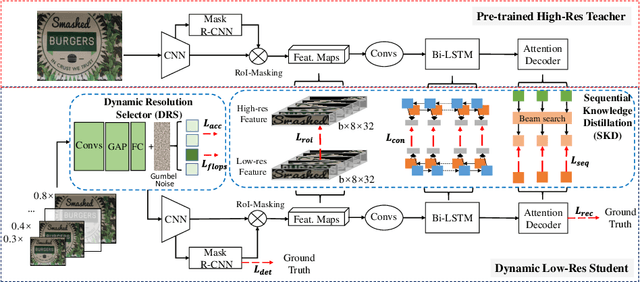
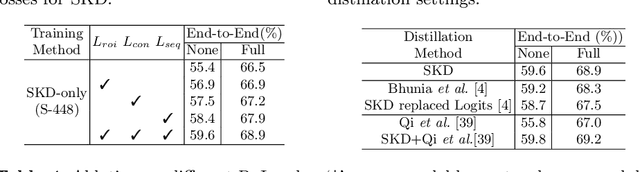
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.
E2-AEN: End-to-End Incremental Learning with Adaptively Expandable Network
Jul 14, 2022



Expandable networks have demonstrated their advantages in dealing with catastrophic forgetting problem in incremental learning. Considering that different tasks may need different structures, recent methods design dynamic structures adapted to different tasks via sophisticated skills. Their routine is to search expandable structures first and then train on the new tasks, which, however, breaks tasks into multiple training stages, leading to suboptimal or overmuch computational cost. In this paper, we propose an end-to-end trainable adaptively expandable network named E2-AEN, which dynamically generates lightweight structures for new tasks without any accuracy drop in previous tasks. Specifically, the network contains a serial of powerful feature adapters for augmenting the previously learned representations to new tasks, and avoiding task interference. These adapters are controlled via an adaptive gate-based pruning strategy which decides whether the expanded structures can be pruned, making the network structure dynamically changeable according to the complexity of the new tasks. Moreover, we introduce a novel sparsity-activation regularization to encourage the model to learn discriminative features with limited parameters. E2-AEN reduces cost and can be built upon any feed-forward architectures in an end-to-end manner. Extensive experiments on both classification (i.e., CIFAR and VDD) and detection (i.e., COCO, VOC and ICCV2021 SSLAD challenge) benchmarks demonstrate the effectiveness of the proposed method, which achieves the new remarkable results.
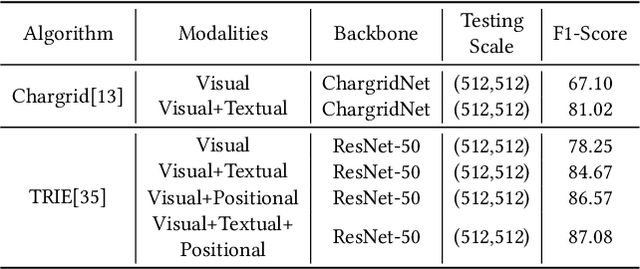
TRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
Jul 14, 2022
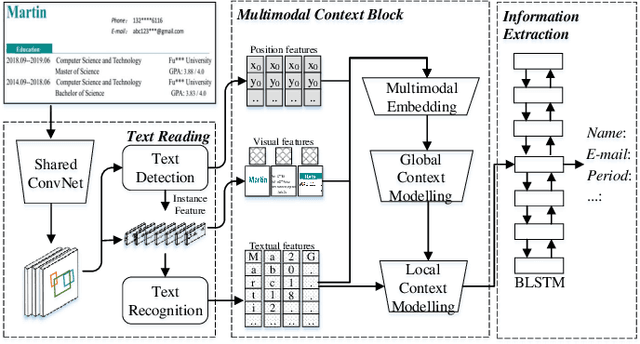
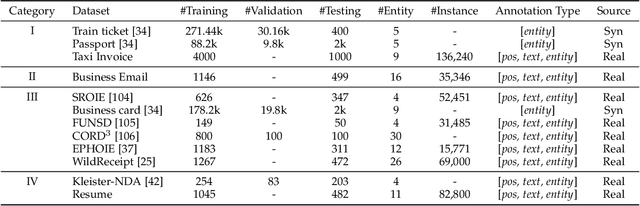
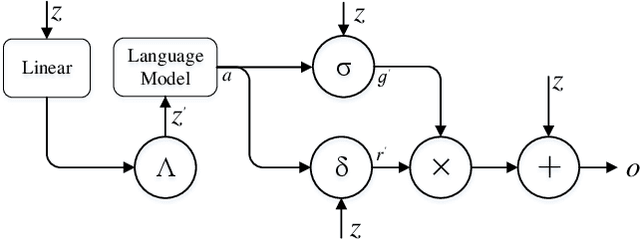
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.
DavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022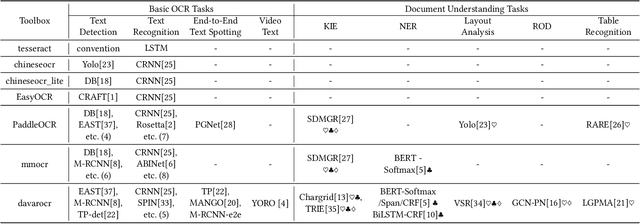


This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective
Apr 09, 2022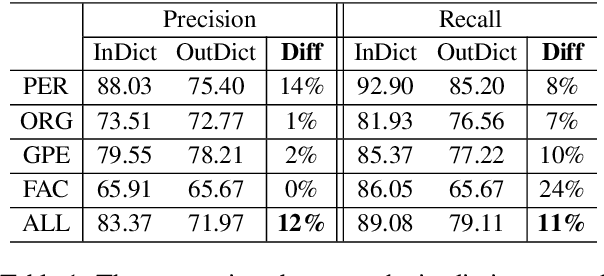
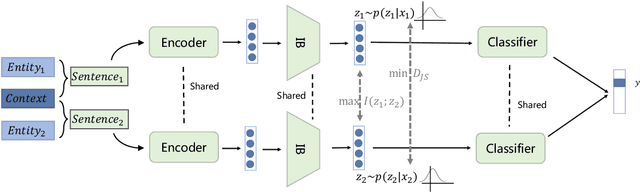
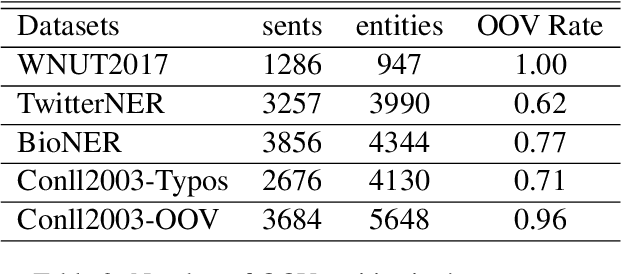
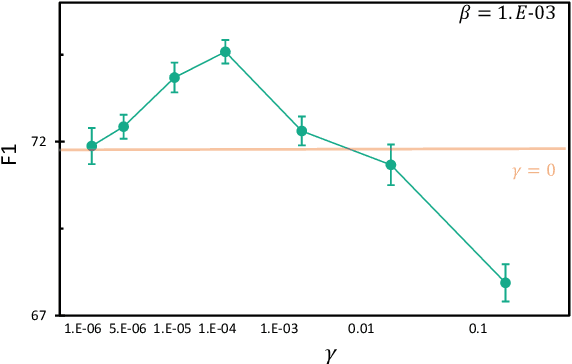
NER model has achieved promising performance on standard NER benchmarks. However, recent studies show that previous approaches may over-rely on entity mention information, resulting in poor performance on out-of-vocabulary (OOV) entity recognition. In this work, we propose MINER, a novel NER learning framework, to remedy this issue from an information-theoretic perspective. The proposed approach contains two mutual information-based training objectives: i) generalizing information maximization, which enhances representation via deep understanding of context and entity surface forms; ii) superfluous information minimization, which discourages representation from rote memorizing entity names or exploiting biased cues in data. Experiments on various settings and datasets demonstrate that it achieves better performance in predicting OOV entities.
PMAL: Open Set Recognition via Robust Prototype Mining
Mar 16, 2022

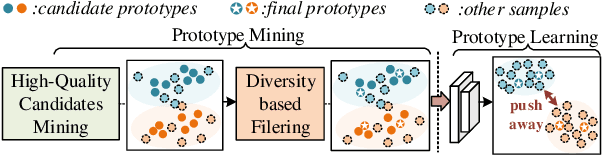

Open Set Recognition (OSR) has been an emerging topic. Besides recognizing predefined classes, the system needs to reject the unknowns. Prototype learning is a potential manner to handle the problem, as its ability to improve intra-class compactness of representations is much needed in discrimination between the known and the unknowns. In this work, we propose a novel Prototype Mining And Learning (PMAL) framework. It has a prototype mining mechanism before the phase of optimizing embedding space, explicitly considering two crucial properties, namely high-quality and diversity of the prototype set. Concretely, a set of high-quality candidates are firstly extracted from training samples based on data uncertainty learning, avoiding the interference from unexpected noise. Considering the multifarious appearance of objects even in a single category, a diversity-based strategy for prototype set filtering is proposed. Accordingly, the embedding space can be better optimized to discriminate therein the predefined classes and between known and unknowns. Extensive experiments verify the two good characteristics (i.e., high-quality and diversity) embraced in prototype mining, and show the remarkable performance of the proposed framework compared to state-of-the-arts.
Technical Report for ICCV 2021 Challenge SSLAD-Track3B: Transformers Are Better Continual Learners
Jan 13, 2022

In the SSLAD-Track 3B challenge on continual learning, we propose the method of COntinual Learning with Transformer (COLT). We find that transformers suffer less from catastrophic forgetting compared to convolutional neural network. The major principle of our method is to equip the transformer based feature extractor with old knowledge distillation and head expanding strategies to compete catastrophic forgetting. In this report, we first introduce the overall framework of continual learning for object detection. Then, we analyse the key elements' effect on withstanding catastrophic forgetting in our solution. Our method achieves 70.78 mAP on the SSLAD-Track 3B challenge test set.
A Strong Baseline for Semi-Supervised Incremental Few-Shot Learning
Nov 04, 2021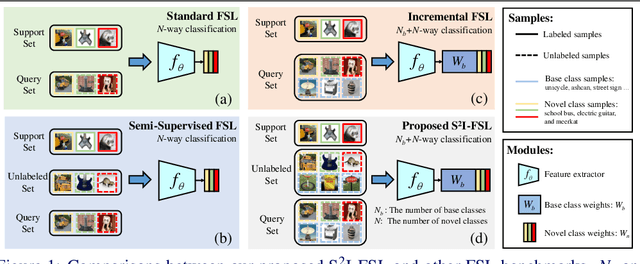
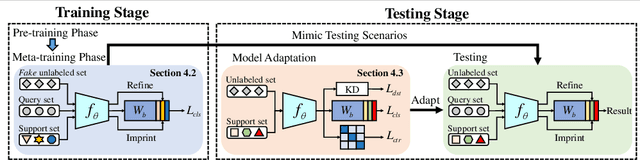
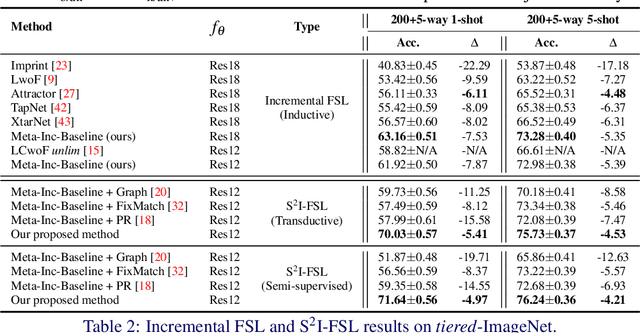
Few-shot learning (FSL) aims to learn models that generalize to novel classes with limited training samples. Recent works advance FSL towards a scenario where unlabeled examples are also available and propose semi-supervised FSL methods. Another line of methods also cares about the performance of base classes in addition to the novel ones and thus establishes the incremental FSL scenario. In this paper, we generalize the above two under a more realistic yet complex setting, named by Semi-Supervised Incremental Few-Shot Learning (S2 I-FSL). To tackle the task, we propose a novel paradigm containing two parts: (1) a well-designed meta-training algorithm for mitigating ambiguity between base and novel classes caused by unreliable pseudo labels and (2) a model adaptation mechanism to learn discriminative features for novel classes while preserving base knowledge using few labeled and all the unlabeled data. Extensive experiments on standard FSL, semi-supervised FSL, incremental FSL, and the firstly built S2 I-FSL benchmarks demonstrate the effectiveness of our proposed method.
ICDAR 2021 Competition on Scene Video Text Spotting
Jul 26, 2021
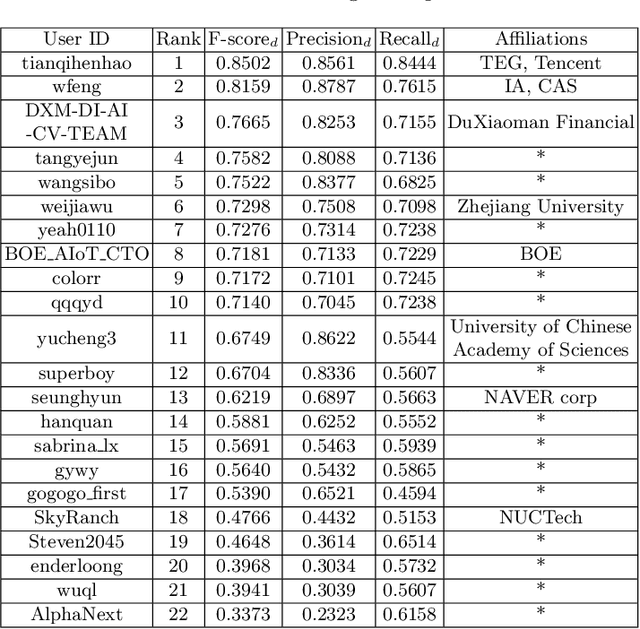

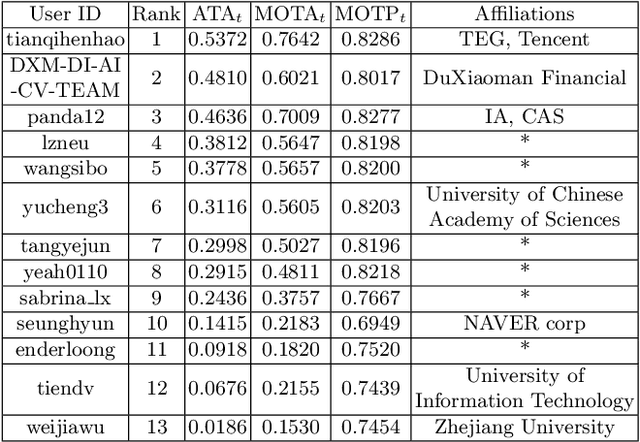
Scene video text spotting (SVTS) is a very important research topic because of many real-life applications. However, only a little effort has put to spotting scene video text, in contrast to massive studies of scene text spotting in static images. Due to various environmental interferences like motion blur, spotting scene video text becomes very challenging. To promote this research area, this competition introduces a new challenge dataset containing 129 video clips from 21 natural scenarios in full annotations. The competition containts three tasks, that is, video text detection (Task 1), video text tracking (Task 2) and end-to-end video text spotting (Task3). During the competition period (opened on 1st March, 2021 and closed on 11th April, 2021), a total of 24 teams participated in the three proposed tasks with 46 valid submissions, respectively. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2021 on SVTS competition. Thanks to the healthy number of teams as well as submissions, we consider that the SVTS competition has been successfully held, drawing much attention from the community and promoting the field research and its development.