 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022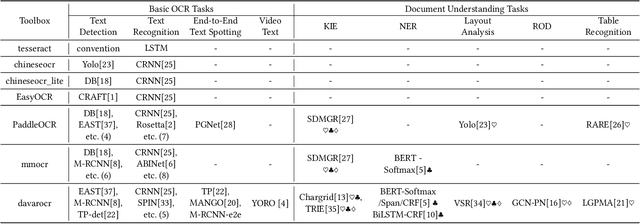


This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
ICDAR 2021 Competition on Scene Video Text Spotting
Jul 26, 2021
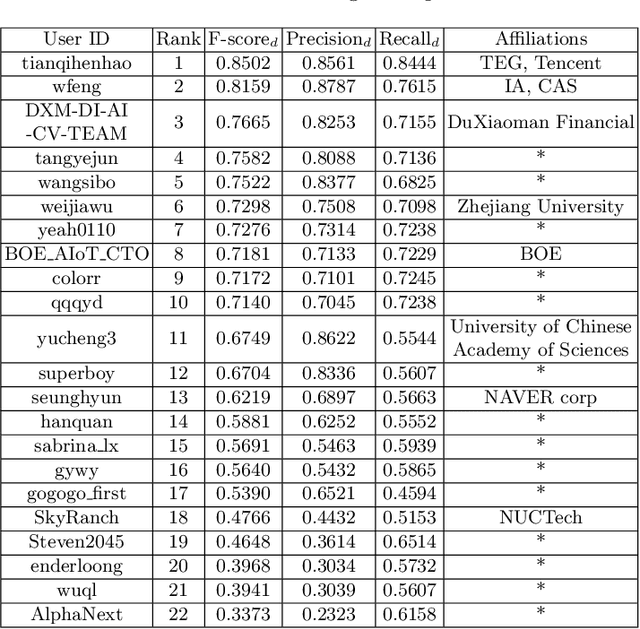

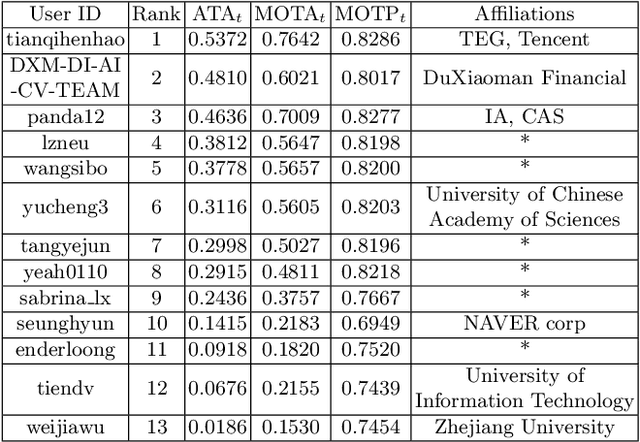
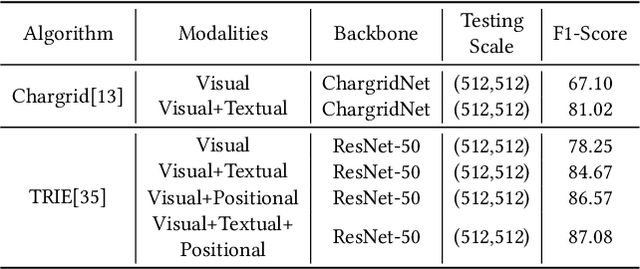
Scene video text spotting (SVTS) is a very important research topic because of many real-life applications. However, only a little effort has put to spotting scene video text, in contrast to massive studies of scene text spotting in static images. Due to various environmental interferences like motion blur, spotting scene video text becomes very challenging. To promote this research area, this competition introduces a new challenge dataset containing 129 video clips from 21 natural scenarios in full annotations. The competition containts three tasks, that is, video text detection (Task 1), video text tracking (Task 2) and end-to-end video text spotting (Task3). During the competition period (opened on 1st March, 2021 and closed on 11th April, 2021), a total of 24 teams participated in the three proposed tasks with 46 valid submissions, respectively. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2021 on SVTS competition. Thanks to the healthy number of teams as well as submissions, we consider that the SVTS competition has been successfully held, drawing much attention from the community and promoting the field research and its development.
Object-QA: Towards High Reliable Object Quality Assessment
May 27, 2020



In object recognition applications, object images usually appear with different quality levels. Practically, it is very important to indicate object image qualities for better application performance, e.g. filtering out low-quality object image frames to maintain robust video object recognition results and speed up inference. However, no previous works are explicitly proposed for addressing the problem. In this paper, we define the problem of object quality assessment for the first time and propose an effective approach named Object-QA to assess high-reliable quality scores for object images. Concretely, Object-QA first employs a well-designed relative quality assessing module that learns the intra-class-level quality scores by referring to the difference between object images and their estimated templates. Then an absolute quality assessing module is designed to generate the final quality scores by aligning the quality score distributions in inter-class. Besides, Object-QA can be implemented with only object-level annotations, and is also easily deployed to a variety of object recognition tasks. To our best knowledge this is the first work to put forward the definition of this problem and conduct quantitative evaluations. Validations on 5 different datasets show that Object-QA can not only assess high-reliable quality scores according with human cognition, but also improve application performance.