 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024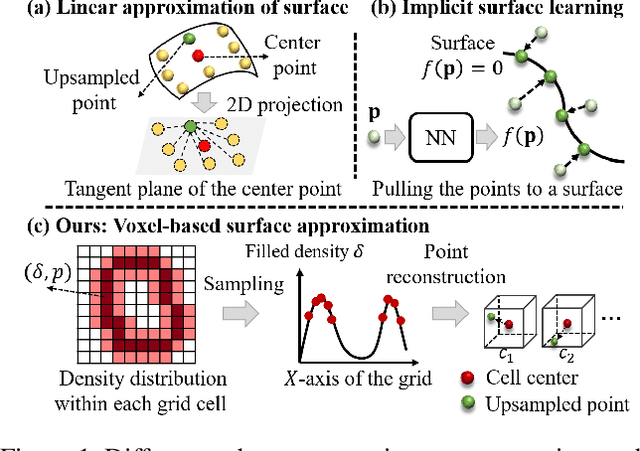
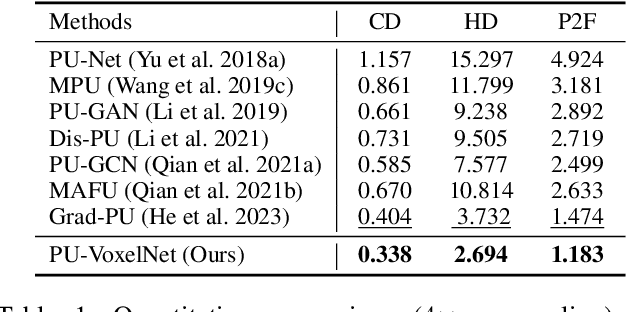
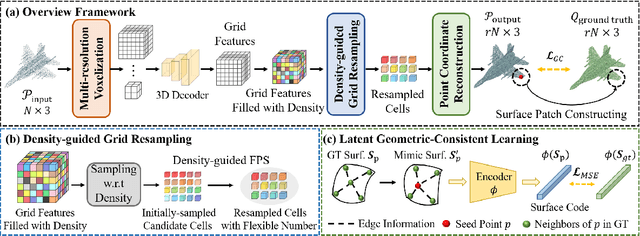
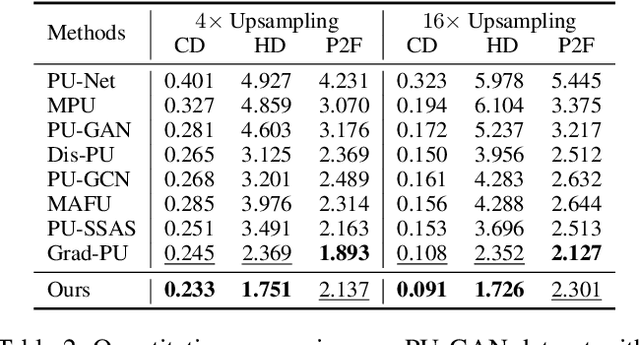
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
Learning Expressive And Generalizable Motion Features For Face Forgery Detection
Mar 08, 2024Previous face forgery detection methods mainly focus on appearance features, which may be easily attacked by sophisticated manipulation. Considering the majority of current face manipulation methods generate fake faces based on a single frame, which do not take frame consistency and coordination into consideration, artifacts on frame sequences are more effective for face forgery detection. However, current sequence-based face forgery detection methods use general video classification networks directly, which discard the special and discriminative motion information for face manipulation detection. To this end, we propose an effective sequence-based forgery detection framework based on an existing video classification method. To make the motion features more expressive for manipulation detection, we propose an alternative motion consistency block instead of the original motion features module. To make the learned features more generalizable, we propose an auxiliary anomaly detection block. With these two specially designed improvements, we make a general video classification network achieve promising results on three popular face forgery datasets.
"Lossless" Compression of Deep Neural Networks: A High-dimensional Neural Tangent Kernel Approach
Mar 01, 2024Modern deep neural networks (DNNs) are extremely powerful; however, this comes at the price of increased depth and having more parameters per layer, making their training and inference more computationally challenging. In an attempt to address this key limitation, efforts have been devoted to the compression (e.g., sparsification and/or quantization) of these large-scale machine learning models, so that they can be deployed on low-power IoT devices. In this paper, building upon recent advances in neural tangent kernel (NTK) and random matrix theory (RMT), we provide a novel compression approach to wide and fully-connected \emph{deep} neural nets. Specifically, we demonstrate that in the high-dimensional regime where the number of data points $n$ and their dimension $p$ are both large, and under a Gaussian mixture model for the data, there exists \emph{asymptotic spectral equivalence} between the NTK matrices for a large family of DNN models. This theoretical result enables "lossless" compression of a given DNN to be performed, in the sense that the compressed network yields asymptotically the same NTK as the original (dense and unquantized) network, with its weights and activations taking values \emph{only} in $\{ 0, \pm 1 \}$ up to a scaling. Experiments on both synthetic and real-world data are conducted to support the advantages of the proposed compression scheme, with code available at \url{https://github.com/Model-Compression/Lossless_Compression}.
LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
Dec 18, 2023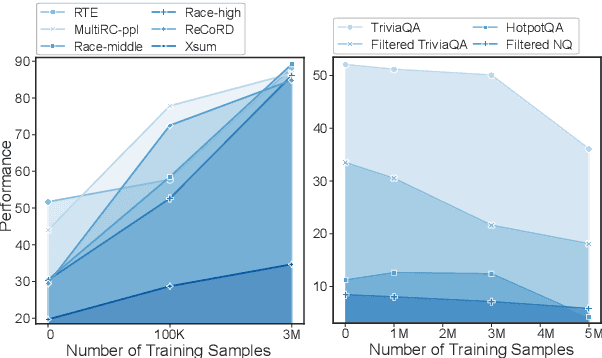
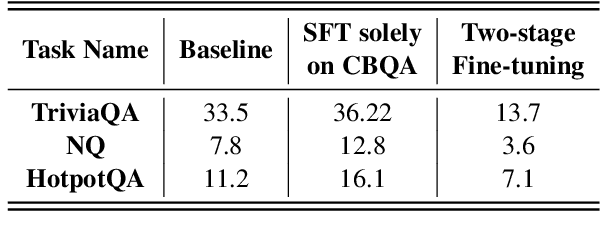
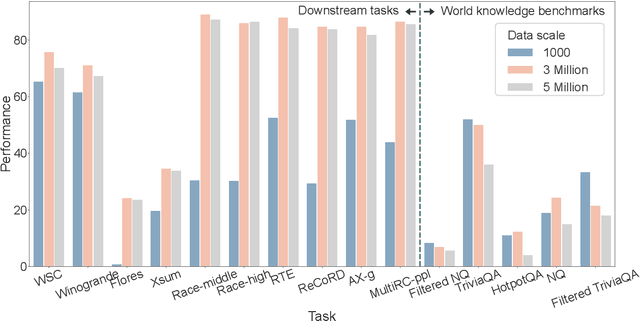
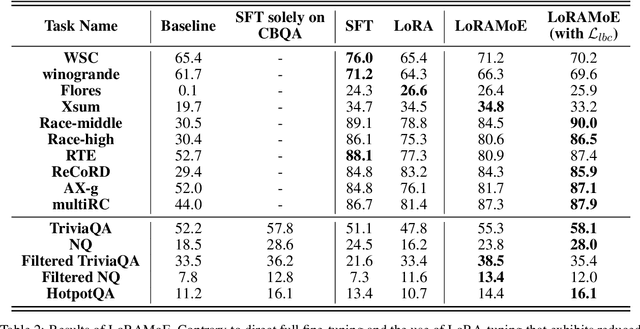
Supervised fine-tuning (SFT) is a crucial step for large language models (LLMs), enabling them to align with human instructions and enhance their capabilities in downstream tasks. When the models are required to align with a broader range of downstream tasks, or there is a desire to notably improve the performance on a specific task, a substantial increase in fine-tuning data often emerges as the solution. However, we find that large-scale increases in instruction data can disrupt the world knowledge previously stored in the LLMs, i.e., world knowledge forgetting. In this paper, we introduce LoRAMoE to address the above challenge. The LoRAMoE is a plugin version of Mixture of Experts (MoE). The plugin form ensures the integrity of world knowledge by freezing the backbone model during the training phase. We then propose the use of localized balancing constraints to coordinate parts of experts for task utilization, meanwhile enabling other experts to fully leverage the world knowledge stored in the models. Experimental results demonstrate that LoRAMoE can reasonably coordinate experts based on data type during inference, and even dramatically increasing instruction data does not result in knowledge forgetting. Moreover, LoRAMoE provides additional benefits for the performance of downstream tasks, indicating the potential of our approach for multi-task learning.
MProto: Multi-Prototype Network with Denoised Optimal Transport for Distantly Supervised Named Entity Recognition
Oct 12, 2023Distantly supervised named entity recognition (DS-NER) aims to locate entity mentions and classify their types with only knowledge bases or gazetteers and unlabeled corpus. However, distant annotations are noisy and degrade the performance of NER models. In this paper, we propose a noise-robust prototype network named MProto for the DS-NER task. Different from previous prototype-based NER methods, MProto represents each entity type with multiple prototypes to characterize the intra-class variance among entity representations. To optimize the classifier, each token should be assigned an appropriate ground-truth prototype and we consider such token-prototype assignment as an optimal transport (OT) problem. Furthermore, to mitigate the noise from incomplete labeling, we propose a novel denoised optimal transport (DOT) algorithm. Specifically, we utilize the assignment result between Other class tokens and all prototypes to distinguish unlabeled entity tokens from true negatives. Experiments on several DS-NER benchmarks demonstrate that our MProto achieves state-of-the-art performance. The source code is now available on Github.
Accelerating Dynamic Network Embedding with Billions of Parameter Updates to Milliseconds
Jun 15, 2023
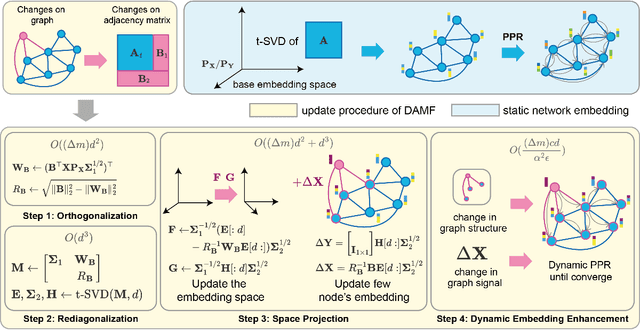
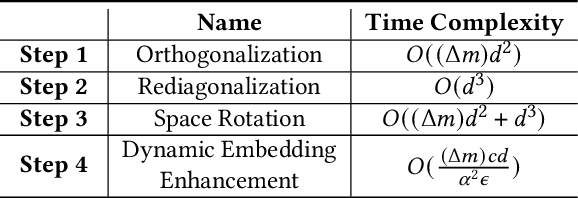
Network embedding, a graph representation learning method illustrating network topology by mapping nodes into lower-dimension vectors, is challenging to accommodate the ever-changing dynamic graphs in practice. Existing research is mainly based on node-by-node embedding modifications, which falls into the dilemma of efficient calculation and accuracy. Observing that the embedding dimensions are usually much smaller than the number of nodes, we break this dilemma with a novel dynamic network embedding paradigm that rotates and scales the axes of embedding space instead of a node-by-node update. Specifically, we propose the Dynamic Adjacency Matrix Factorization (DAMF) algorithm, which achieves an efficient and accurate dynamic network embedding by rotating and scaling the coordinate system where the network embedding resides with no more than the number of edge modifications changes of node embeddings. Moreover, a dynamic Personalized PageRank is applied to the obtained network embeddings to enhance node embeddings and capture higher-order neighbor information dynamically. Experiments of node classification, link prediction, and graph reconstruction on different-sized dynamic graphs suggest that DAMF advances dynamic network embedding. Further, we unprecedentedly expand dynamic network embedding experiments to billion-edge graphs, where DAMF updates billion-level parameters in less than 10ms.
Single Domain Dynamic Generalization for Iris Presentation Attack Detection
May 22, 2023Iris presentation attack detection (PAD) has achieved great success under intra-domain settings but easily degrades on unseen domains. Conventional domain generalization methods mitigate the gap by learning domain-invariant features. However, they ignore the discriminative information in the domain-specific features. Moreover, we usually face a more realistic scenario with only one single domain available for training. To tackle the above issues, we propose a Single Domain Dynamic Generalization (SDDG) framework, which simultaneously exploits domain-invariant and domain-specific features on a per-sample basis and learns to generalize to various unseen domains with numerous natural images. Specifically, a dynamic block is designed to adaptively adjust the network with a dynamic adaptor. And an information maximization loss is further combined to increase diversity. The whole network is integrated into the meta-learning paradigm. We generate amplitude perturbed images and cover diverse domains with natural images. Therefore, the network can learn to generalize to the perturbed domains in the meta-test phase. Extensive experiments show the proposed method is effective and outperforms the state-of-the-art on LivDet-Iris 2017 dataset.
Taxonomy Completion with Probabilistic Scorer via Box Embedding
May 19, 2023

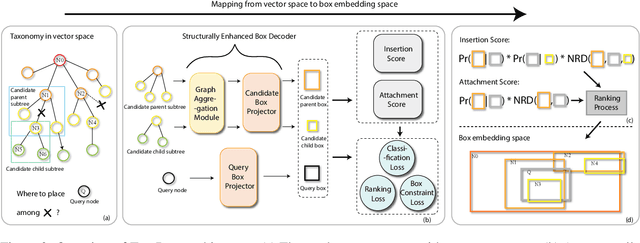
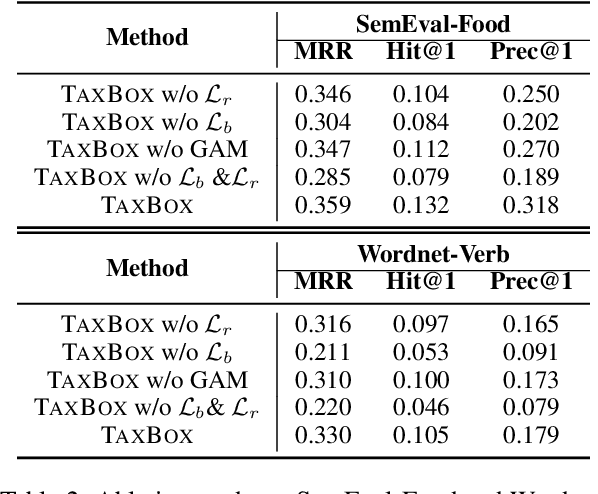
Taxonomy completion, a task aimed at automatically enriching an existing taxonomy with new concepts, has gained significant interest in recent years. Previous works have introduced complex modules, external information, and pseudo-leaves to enrich the representation and unify the matching process of attachment and insertion. While they have achieved good performance, these introductions may have brought noise and unfairness during training and scoring. In this paper, we present TaxBox, a novel framework for taxonomy completion that maps taxonomy concepts to box embeddings and employs two probabilistic scorers for concept attachment and insertion, avoiding the need for pseudo-leaves. Specifically, TaxBox consists of three components: (1) a graph aggregation module to leverage the structural information of the taxonomy and two lightweight decoders that map features to box embedding and capture complex relationships between concepts; (2) two probabilistic scorers that correspond to attachment and insertion operations and ensure the avoidance of pseudo-leaves; and (3) three learning objectives that assist the model in mapping concepts more granularly onto the box embedding space. Experimental results on four real-world datasets suggest that TaxBox outperforms baseline methods by a considerable margin and surpasses previous state-of-art methods to a certain extent.
Multi-view Adversarial Discriminator: Mine the Non-causal Factors for Object Detection in Unseen Domains
Apr 06, 2023Domain shift degrades the performance of object detection models in practical applications. To alleviate the influence of domain shift, plenty of previous work try to decouple and learn the domain-invariant (common) features from source domains via domain adversarial learning (DAL). However, inspired by causal mechanisms, we find that previous methods ignore the implicit insignificant non-causal factors hidden in the common features. This is mainly due to the single-view nature of DAL. In this work, we present an idea to remove non-causal factors from common features by multi-view adversarial training on source domains, because we observe that such insignificant non-causal factors may still be significant in other latent spaces (views) due to the multi-mode structure of data. To summarize, we propose a Multi-view Adversarial Discriminator (MAD) based domain generalization model, consisting of a Spurious Correlations Generator (SCG) that increases the diversity of source domain by random augmentation and a Multi-View Domain Classifier (MVDC) that maps features to multiple latent spaces, such that the non-causal factors are removed and the domain-invariant features are purified. Extensive experiments on six benchmarks show our MAD obtains state-of-the-art performance.
Rethinking the Approximation Error in 3D Surface Fitting for Point Cloud Normal Estimation
Mar 30, 2023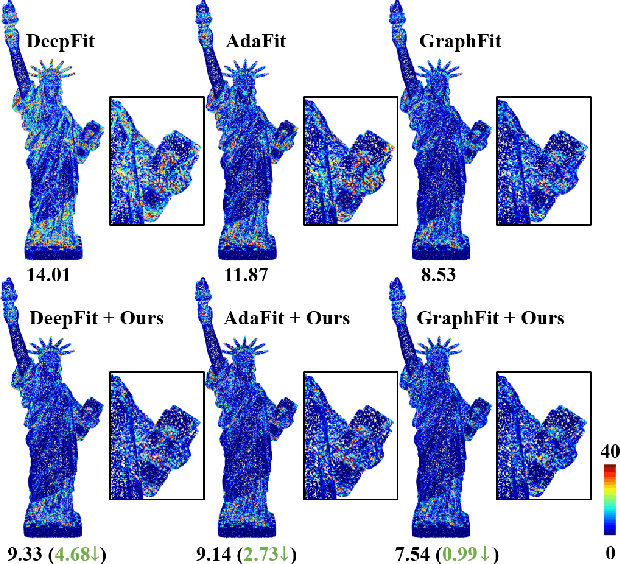
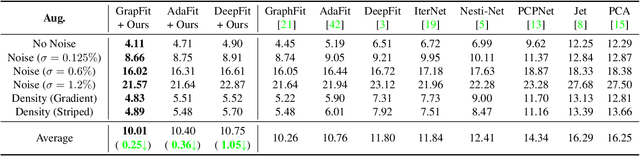
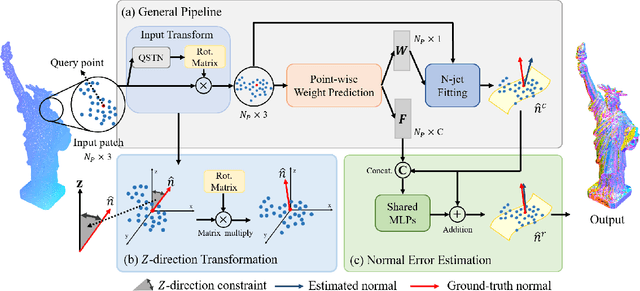
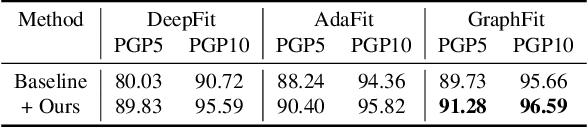
Most existing approaches for point cloud normal estimation aim to locally fit a geometric surface and calculate the normal from the fitted surface. Recently, learning-based methods have adopted a routine of predicting point-wise weights to solve the weighted least-squares surface fitting problem. Despite achieving remarkable progress, these methods overlook the approximation error of the fitting problem, resulting in a less accurate fitted surface. In this paper, we first carry out in-depth analysis of the approximation error in the surface fitting problem. Then, in order to bridge the gap between estimated and precise surface normals, we present two basic design principles: 1) applies the $Z$-direction Transform to rotate local patches for a better surface fitting with a lower approximation error; 2) models the error of the normal estimation as a learnable term. We implement these two principles using deep neural networks, and integrate them with the state-of-the-art (SOTA) normal estimation methods in a plug-and-play manner. Extensive experiments verify our approaches bring benefits to point cloud normal estimation and push the frontier of state-of-the-art performance on both synthetic and real-world datasets.