 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning
Feb 25, 2026Image captioning remains a fundamental task for vision language understanding, yet ground-truth supervision still relies predominantly on human-annotated references. Because human annotations reflect subjective preferences and expertise, ground-truth captions are often incomplete or even incorrect, which in turn limits caption models. We argue that caption quality should be assessed by two objective aspects: completeness (does the caption cover all salient visual facts?) and correctness (are the descriptions true with respect to the image?). To this end, we introduce CCCaption: a dual-reward reinforcement learning framework with a dedicated fine-tuning corpus that explicitly optimizes these properties to generate \textbf{C}omplete and \textbf{C}orrect \textbf{Captions}. For completeness, we use diverse LVLMs to disentangle the image into a set of visual queries, and reward captions that answer more of these queries, with a dynamic query sampling strategy to improve training efficiency. For correctness, we penalize captions that contain hallucinations by validating the authenticity of sub-caption queries, which are derived from the caption decomposition. Our symmetric dual-reward optimization jointly maximizes completeness and correctness, guiding models toward captions that better satisfy these objective criteria. Extensive experiments across standard captioning benchmarks show consistent improvements, offering a principled path to training caption models beyond human-annotation imitation.
Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training
Feb 12, 2026Supervised fine-tuning (SFT) is computationally efficient but often yields inferior generalization compared to reinforcement learning (RL). This gap is primarily driven by RL's use of on-policy data. We propose a framework to bridge this chasm by enabling On-Policy SFT. We first present \textbf{\textit{Distribution Discriminant Theory (DDT)}}, which explains and quantifies the alignment between data and the model-induced distribution. Leveraging DDT, we introduce two complementary techniques: (i) \textbf{\textit{In-Distribution Finetuning (IDFT)}}, a loss-level method to enhance generalization ability of SFT, and (ii) \textbf{\textit{Hinted Decoding}}, a data-level technique that can re-align the training corpus to the model's distribution. Extensive experiments demonstrate that our framework achieves generalization performance on par with prominent offline RL algorithms, including DPO and SimPO, while maintaining the efficiency of an SFT pipeline. The proposed framework thus offers a practical alternative in domains where RL is infeasible. We open-source the code here: https://github.com/zhangmiaosen2000/Towards-On-Policy-SFT
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
May 06, 2024Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
Class-relevant Patch Embedding Selection for Few-Shot Image Classification
May 06, 2024Effective image classification hinges on discerning relevant features from both foreground and background elements, with the foreground typically holding the critical information. While humans adeptly classify images with limited exposure, artificial neural networks often struggle with feature selection from rare samples. To address this challenge, we propose a novel method for selecting class-relevant patch embeddings. Our approach involves splitting support and query images into patches, encoding them using a pre-trained Vision Transformer (ViT) to obtain class embeddings and patch embeddings, respectively. Subsequently, we filter patch embeddings using class embeddings to retain only the class-relevant ones. For each image, we calculate the similarity between class embedding and each patch embedding, sort the similarity sequence in descending order, and only retain top-ranked patch embeddings. By prioritizing similarity between the class embedding and patch embeddings, we select top-ranked patch embeddings to be fused with class embedding to form a comprehensive image representation, enhancing pattern recognition across instances. Our strategy effectively mitigates the impact of class-irrelevant patch embeddings, yielding improved performance in pre-trained models. Extensive experiments on popular few-shot classification benchmarks demonstrate the simplicity, efficacy, and computational efficiency of our approach, outperforming state-of-the-art baselines under both 5-shot and 1-shot scenarios.
Learning Multiple Representations with Inconsistency-Guided Detail Regularization for Mask-Guided Matting
Mar 28, 2024Mask-guided matting networks have achieved significant improvements and have shown great potential in practical applications in recent years. However, simply learning matting representation from synthetic and lack-of-real-world-diversity matting data, these approaches tend to overfit low-level details in wrong regions, lack generalization to objects with complex structures and real-world scenes such as shadows, as well as suffer from interference of background lines or textures. To address these challenges, in this paper, we propose a novel auxiliary learning framework for mask-guided matting models, incorporating three auxiliary tasks: semantic segmentation, edge detection, and background line detection besides matting, to learn different and effective representations from different types of data and annotations. Our framework and model introduce the following key aspects: (1) to learn real-world adaptive semantic representation for objects with diverse and complex structures under real-world scenes, we introduce extra semantic segmentation and edge detection tasks on more diverse real-world data with segmentation annotations; (2) to avoid overfitting on low-level details, we propose a module to utilize the inconsistency between learned segmentation and matting representations to regularize detail refinement; (3) we propose a novel background line detection task into our auxiliary learning framework, to suppress interference of background lines or textures. In addition, we propose a high-quality matting benchmark, Plant-Mat, to evaluate matting methods on complex structures. Extensively quantitative and qualitative results show that our approach outperforms state-of-the-art mask-guided methods.
Boosting Meta-Training with Base Class Information for Few-Shot Learning
Mar 06, 2024



Few-shot learning, a challenging task in machine learning, aims to learn a classifier adaptable to recognize new, unseen classes with limited labeled examples. Meta-learning has emerged as a prominent framework for few-shot learning. Its training framework is originally a task-level learning method, such as Model-Agnostic Meta-Learning (MAML) and Prototypical Networks. And a recently proposed training paradigm called Meta-Baseline, which consists of sequential pre-training and meta-training stages, gains state-of-the-art performance. However, as a non-end-to-end training method, indicating the meta-training stage can only begin after the completion of pre-training, Meta-Baseline suffers from higher training cost and suboptimal performance due to the inherent conflicts of the two training stages. To address these limitations, we propose an end-to-end training paradigm consisting of two alternative loops. In the outer loop, we calculate cross entropy loss on the entire training set while updating only the final linear layer. In the inner loop, we employ the original meta-learning training mode to calculate the loss and incorporate gradients from the outer loss to guide the parameter updates. This training paradigm not only converges quickly but also outperforms existing baselines, indicating that information from the overall training set and the meta-learning training paradigm could mutually reinforce one another. Moreover, being model-agnostic, our framework achieves significant performance gains, surpassing the baseline systems by approximate 1%.
PA-SAM: Prompt Adapter SAM for High-Quality Image Segmentation
Jan 23, 2024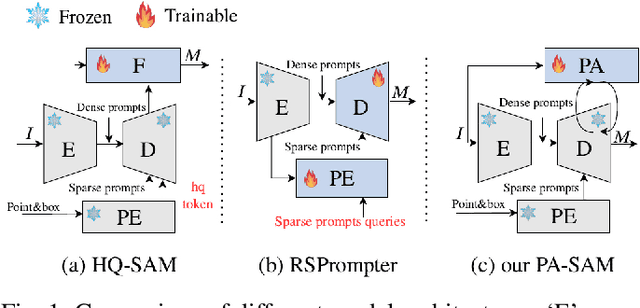
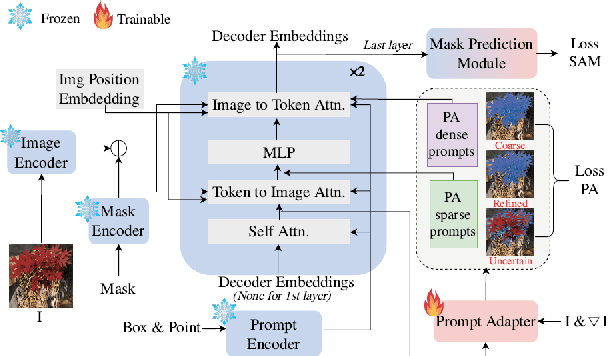
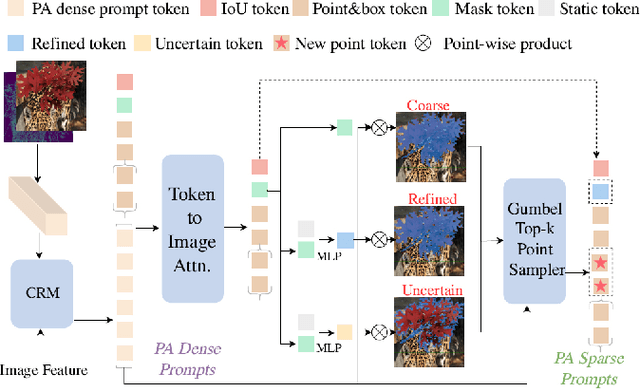

The Segment Anything Model (SAM) has exhibited outstanding performance in various image segmentation tasks. Despite being trained with over a billion masks, SAM faces challenges in mask prediction quality in numerous scenarios, especially in real-world contexts. In this paper, we introduce a novel prompt-driven adapter into SAM, namely Prompt Adapter Segment Anything Model (PA-SAM), aiming to enhance the segmentation mask quality of the original SAM. By exclusively training the prompt adapter, PA-SAM extracts detailed information from images and optimizes the mask decoder feature at both sparse and dense prompt levels, improving the segmentation performance of SAM to produce high-quality masks. Experimental results demonstrate that our PA-SAM outperforms other SAM-based methods in high-quality, zero-shot, and open-set segmentation. We're making the source code and models available at https://github.com/xzz2/pa-sam.
Accelerating Dynamic Network Embedding with Billions of Parameter Updates to Milliseconds
Jun 15, 2023
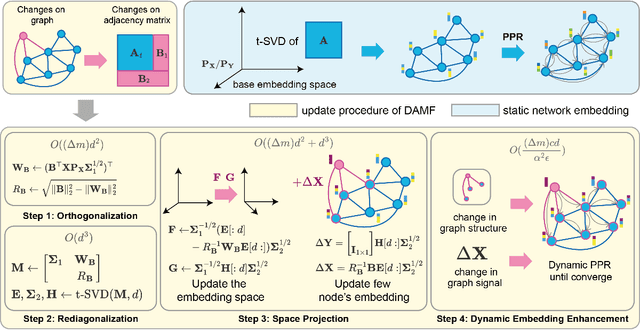
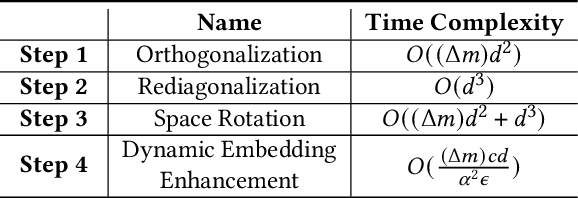
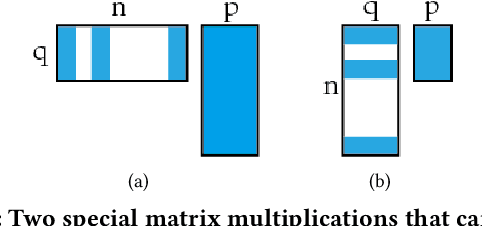
Network embedding, a graph representation learning method illustrating network topology by mapping nodes into lower-dimension vectors, is challenging to accommodate the ever-changing dynamic graphs in practice. Existing research is mainly based on node-by-node embedding modifications, which falls into the dilemma of efficient calculation and accuracy. Observing that the embedding dimensions are usually much smaller than the number of nodes, we break this dilemma with a novel dynamic network embedding paradigm that rotates and scales the axes of embedding space instead of a node-by-node update. Specifically, we propose the Dynamic Adjacency Matrix Factorization (DAMF) algorithm, which achieves an efficient and accurate dynamic network embedding by rotating and scaling the coordinate system where the network embedding resides with no more than the number of edge modifications changes of node embeddings. Moreover, a dynamic Personalized PageRank is applied to the obtained network embeddings to enhance node embeddings and capture higher-order neighbor information dynamically. Experiments of node classification, link prediction, and graph reconstruction on different-sized dynamic graphs suggest that DAMF advances dynamic network embedding. Further, we unprecedentedly expand dynamic network embedding experiments to billion-edge graphs, where DAMF updates billion-level parameters in less than 10ms.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
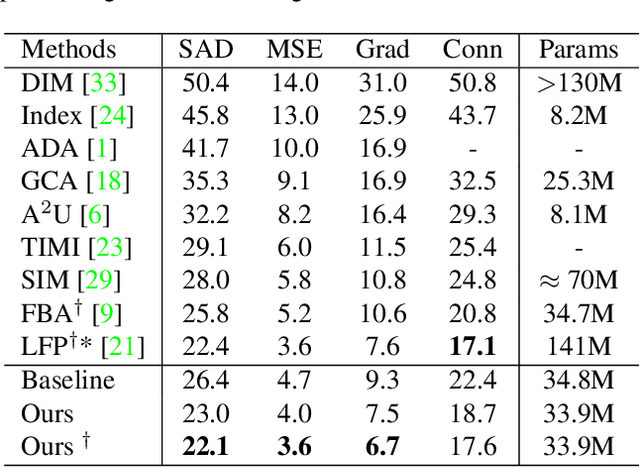
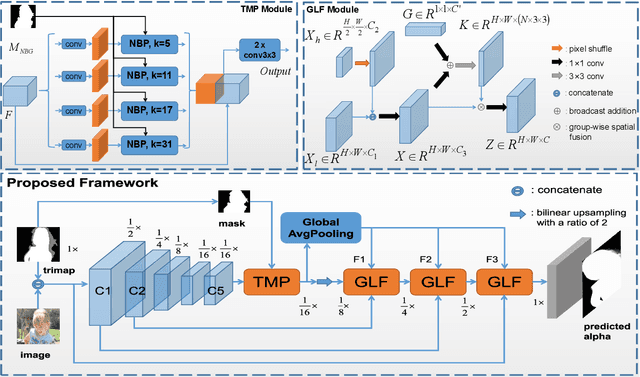
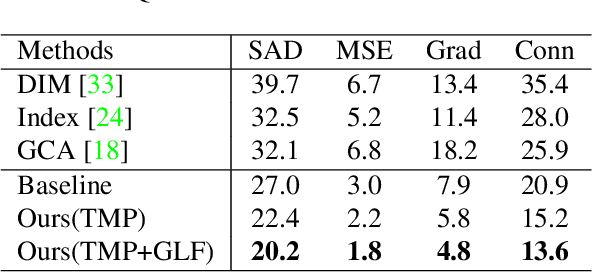
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
LRNNet: A Light-Weighted Network with Efficient Reduced Non-Local Operation for Real-Time Semantic Segmentation
Jun 04, 2020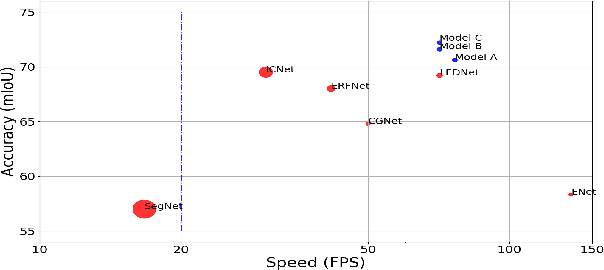
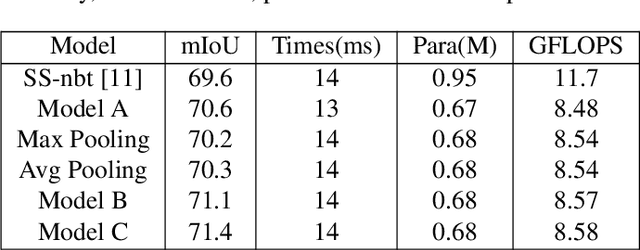
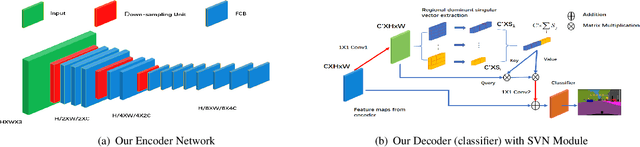
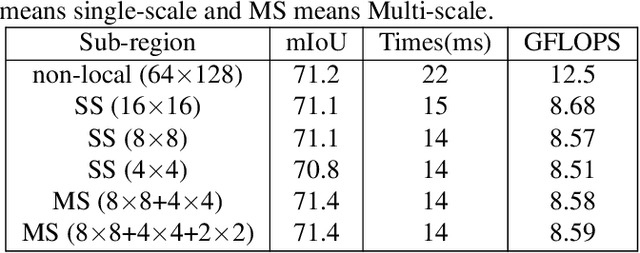
The recent development of light-weighted neural networks has promoted the applications of deep learning under resource constraints and mobile applications. Many of these applications need to perform a real-time and efficient prediction for semantic segmentation with a light-weighted network. This paper introduces a light-weighted network with an efficient reduced non-local module (LRNNet) for efficient and realtime semantic segmentation. We proposed a factorized convolutional block in ResNet-Style encoder to achieve more lightweighted, efficient and powerful feature extraction. Meanwhile, our proposed reduced non-local module utilizes spatial regional dominant singular vectors to achieve reduced and more representative non-local feature integration with much lower computation and memory cost. Experiments demonstrate our superior trade-off among light-weight, speed, computation and accuracy. Without additional processing and pretraining, LRNNet achieves 72.2% mIoU on Cityscapes test dataset only using the fine annotation data for training with only 0.68M parameters and with 71 FPS on a GTX 1080Ti card.