 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-SAM: Prompt Adapter SAM for High-Quality Image Segmentation
Jan 23, 2024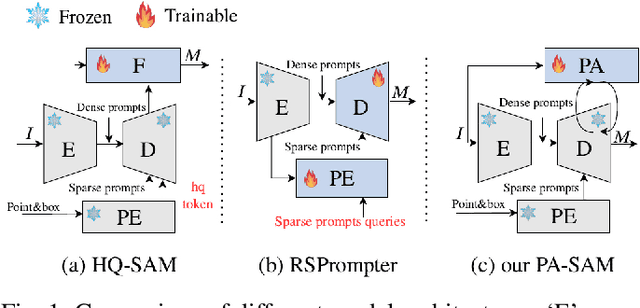
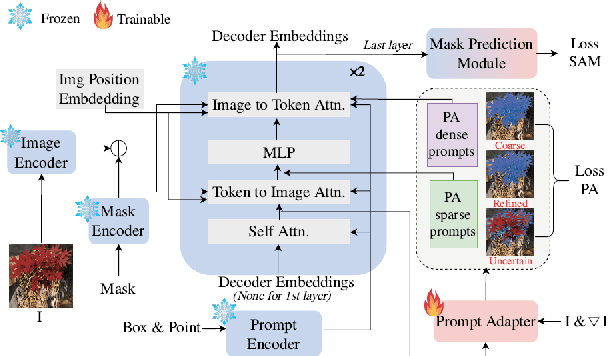
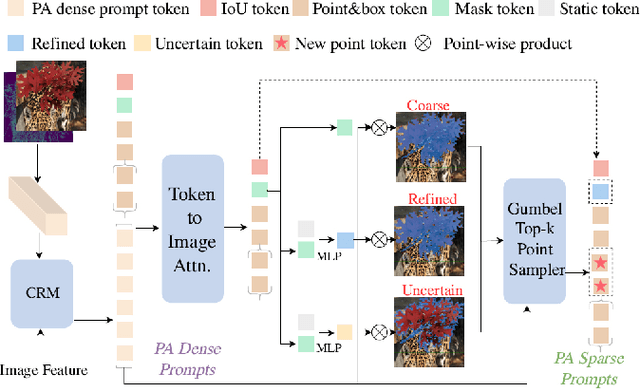

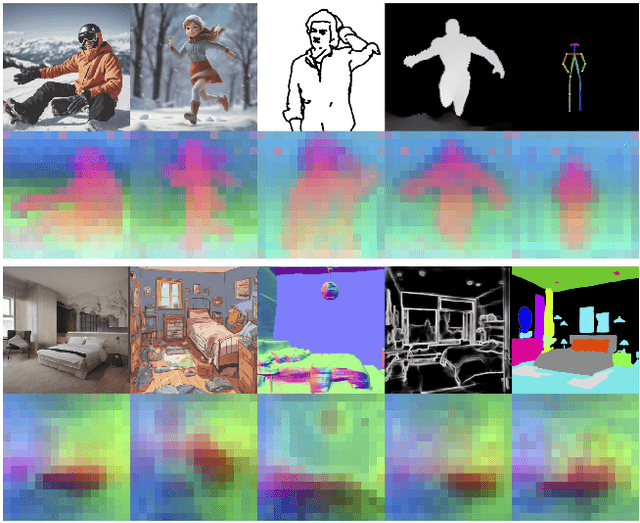
The Segment Anything Model (SAM) has exhibited outstanding performance in various image segmentation tasks. Despite being trained with over a billion masks, SAM faces challenges in mask prediction quality in numerous scenarios, especially in real-world contexts. In this paper, we introduce a novel prompt-driven adapter into SAM, namely Prompt Adapter Segment Anything Model (PA-SAM), aiming to enhance the segmentation mask quality of the original SAM. By exclusively training the prompt adapter, PA-SAM extracts detailed information from images and optimizes the mask decoder feature at both sparse and dense prompt levels, improving the segmentation performance of SAM to produce high-quality masks. Experimental results demonstrate that our PA-SAM outperforms other SAM-based methods in high-quality, zero-shot, and open-set segmentation. We're making the source code and models available at https://github.com/xzz2/pa-sam.
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
Dec 12, 2023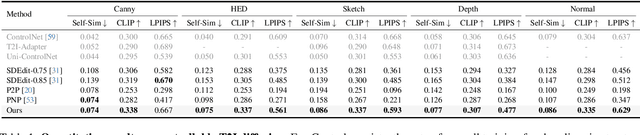
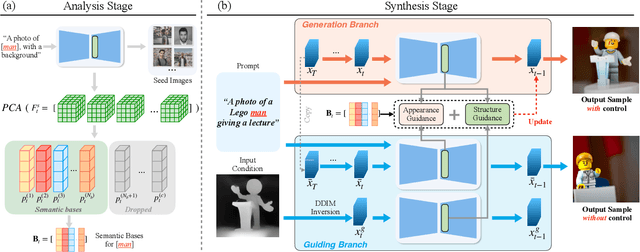

Recent approaches such as ControlNet offer users fine-grained spatial control over text-to-image (T2I) diffusion models. However, auxiliary modules have to be trained for each type of spatial condition, model architecture, and checkpoint, putting them at odds with the diverse intents and preferences a human designer would like to convey to the AI models during the content creation process. In this work, we present FreeControl, a training-free approach for controllable T2I generation that supports multiple conditions, architectures, and checkpoints simultaneously. FreeControl designs structure guidance to facilitate the structure alignment with a guidance image, and appearance guidance to enable the appearance sharing between images generated using the same seed. Extensive qualitative and quantitative experiments demonstrate the superior performance of FreeControl across a variety of pre-trained T2I models. In particular, FreeControl facilitates convenient training-free control over many different architectures and checkpoints, allows the challenging input conditions on which most of the existing training-free methods fail, and achieves competitive synthesis quality with training-based approaches.
Vision Backbone Enhancement via Multi-Stage Cross-Scale Attention
Aug 14, 2023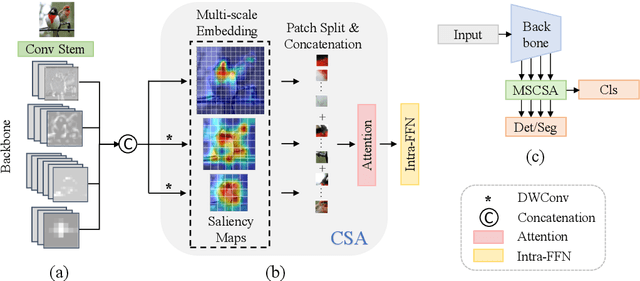



Convolutional neural networks (CNNs) and vision transformers (ViTs) have achieved remarkable success in various vision tasks. However, many architectures do not consider interactions between feature maps from different stages and scales, which may limit their performance. In this work, we propose a simple add-on attention module to overcome these limitations via multi-stage and cross-scale interactions. Specifically, the proposed Multi-Stage Cross-Scale Attention (MSCSA) module takes feature maps from different stages to enable multi-stage interactions and achieves cross-scale interactions by computing self-attention at different scales based on the multi-stage feature maps. Our experiments on several downstream tasks show that MSCSA provides a significant performance boost with modest additional FLOPs and runtime.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
SMOF: Squeezing More Out of Filters Yields Hardware-Friendly CNN Pruning
Oct 21, 2021
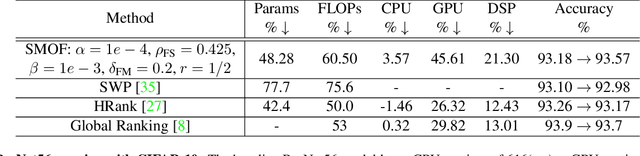
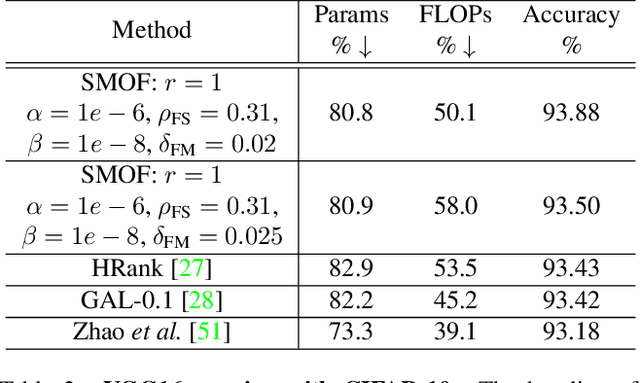
For many years, the family of convolutional neural networks (CNNs) has been a workhorse in deep learning. Recently, many novel CNN structures have been designed to address increasingly challenging tasks. To make them work efficiently on edge devices, researchers have proposed various structured network pruning strategies to reduce their memory and computational cost. However, most of them only focus on reducing the number of filter channels per layer without considering the redundancy within individual filter channels. In this work, we explore pruning from another dimension, the kernel size. We develop a CNN pruning framework called SMOF, which Squeezes More Out of Filters by reducing both kernel size and the number of filter channels. Notably, SMOF is friendly to standard hardware devices without any customized low-level implementations, and the pruning effort by kernel size reduction does not suffer from the fixed-size width constraint in SIMD units of general-purpose processors. The pruned networks can be deployed effortlessly with significant running time reduction. We also support these claims via extensive experiments on various CNN structures and general-purpose processors for mobile devices.
SpecNet: Spectral Domain Convolutional Neural Network
May 28, 2019
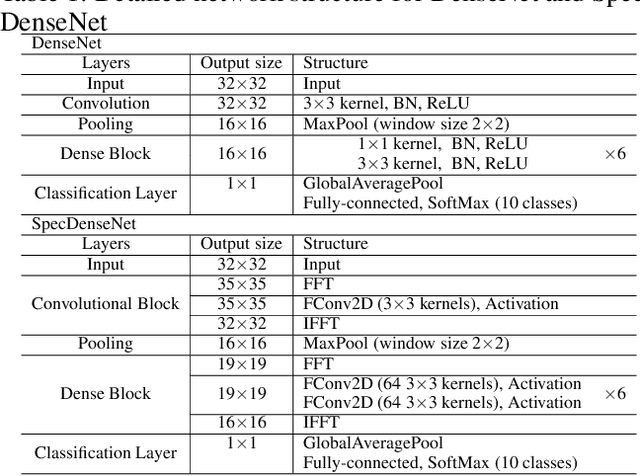

The memory consumption of most Convolutional Neural Network (CNN) architectures grows rapidly with increasing depth of the network, which is a major constraint for efficient network training and inference on modern GPUs with yet limited memory. Several studies show that the feature maps (as generated after the convolutional layers) are the big bottleneck in this memory problem. Often, these feature maps mimic natural photographs in the sense that their energy is concentrated in the spectral domain. This paper proposes a Spectral Domain Convolutional Neural Network (SpecNet) that performs both the convolution and the activation operations in the spectral domain to achieve memory reduction. SpecNet exploits a configurable threshold to force small values in the feature maps to zero, allowing the feature maps to be stored sparsely. Since convolution in the spatial domain is equivalent to a dot product in the spectral domain, the multiplications only need to be performed on the non-zero entries of the (sparse) spectral domain feature maps. SpecNet also employs a special activation function that preserves the sparsity of the feature maps while effectively encouraging the convergence of the network. The performance of SpecNet is evaluated on three competitive object recognition benchmark tasks (MNIST, CIFAR-10, and SVHN), and compared with four state-of-the-art implementations (LeNet, AlexNet, VGG, and DenseNet). Overall, SpecNet is able to reduce memory consumption by about 60% without significant loss of performance for all tested network architectures.
Target Image Video Search Based on Local Features
Aug 11, 2018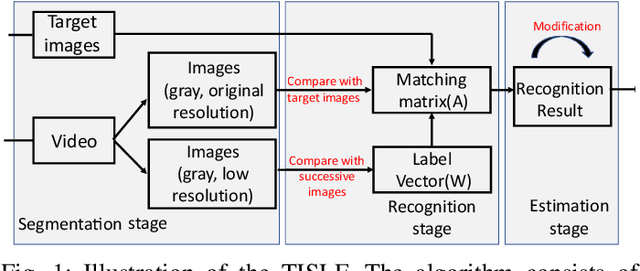

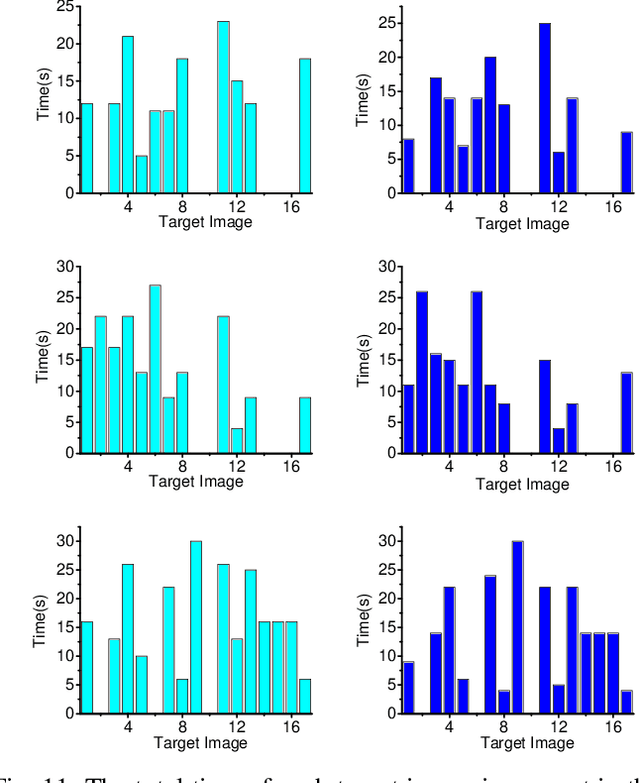
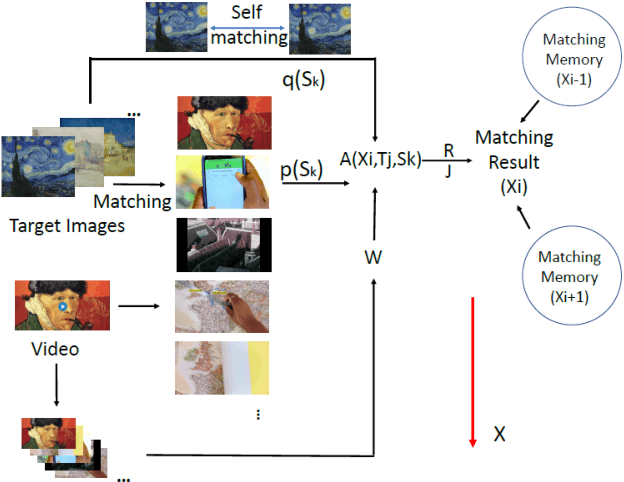
This paper presents a new search algorithm called Target Image Search based on Local Features (TISLF) which compares target images and video source images using local features. TISLF can be used to locate frames where target images occur in a video, and by computing and comparing the matching probability matrix, estimates the time of appearance, the duration, and the time of disappearance of the target image from the video stream. The algorithm is applicable to a variety of applications such as tracking the appearance and duration of advertisements in the broadcast of a sports event, searching and labelling painting in documentaries, and searching landmarks of different cities in videos. The algorithm is compared to a deep learning method and shows competitive performance in experiments.