 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStroke Lesion Segmentation using Multi-Stage Cross-Scale Attention
Jan 26, 2025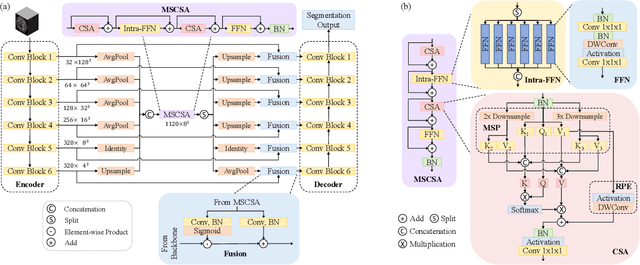
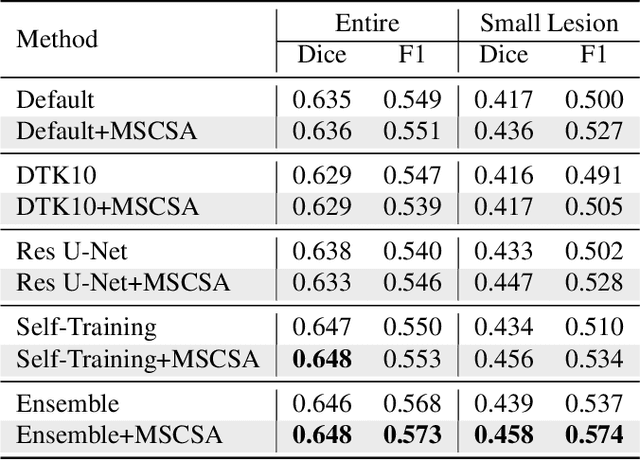
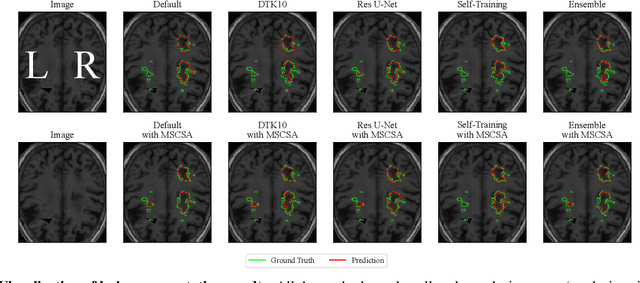
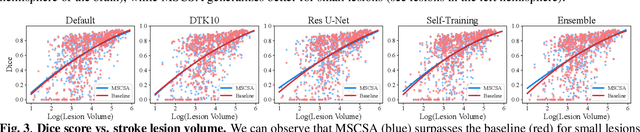
Precise characterization of stroke lesions from MRI data has immense value in prognosticating clinical and cognitive outcomes following a stroke. Manual stroke lesion segmentation is time-consuming and requires the expertise of neurologists and neuroradiologists. Often, lesions are grossly characterized for their location and overall extent using bounding boxes without specific delineation of their boundaries. While such characterization provides some clinical value, to develop a precise mechanistic understanding of the impact of lesions on post-stroke vascular contributions to cognitive impairments and dementia (VCID), the stroke lesions need to be fully segmented with accurate boundaries. This work introduces the Multi-Stage Cross-Scale Attention (MSCSA) mechanism, applied to the U-Net family, to improve the mapping between brain structural features and lesions of varying sizes. Using the Anatomical Tracings of Lesions After Stroke (ATLAS) v2.0 dataset, MSCSA outperforms all baseline methods in both Dice and F1 scores on a subset focusing on small lesions, while maintaining competitive performance across the entire dataset. Notably, the ensemble strategy incorporating MSCSA achieves the highest scores for Dice and F1 on both the full dataset and the small lesion subset. These results demonstrate the effectiveness of MSCSA in segmenting small lesions and highlight its robustness across different training schemes for large stroke lesions. Our code is available at: https://github.com/nadluru/StrokeLesSeg.
Segmenting Small Stroke Lesions with Novel Labeling Strategies
Aug 06, 2024



Deep neural networks have demonstrated exceptional efficacy in stroke lesion segmentation. However, the delineation of small lesions, critical for stroke diagnosis, remains a challenge. In this study, we propose two straightforward yet powerful approaches that can be seamlessly integrated into a variety of networks: Multi-Size Labeling (MSL) and Distance-Based Labeling (DBL), with the aim of enhancing the segmentation accuracy of small lesions. MSL divides lesion masks into various categories based on lesion volume while DBL emphasizes the lesion boundaries. Experimental evaluations on the Anatomical Tracings of Lesions After Stroke (ATLAS) v2.0 dataset showcase that an ensemble of MSL and DBL achieves consistently better or equal performance on recall (3.6% and 3.7%), F1 (2.4% and 1.5%), and Dice scores (1.3% and 0.0%) compared to the top-1 winner of the 2022 MICCAI ATLAS Challenge on both the subset only containing small lesions and the entire dataset, respectively. Notably, on the mini-lesion subset, a single MSL model surpasses the previous best ensemble strategy, with enhancements of 1.0% and 0.3% on F1 and Dice scores, respectively. Our code is available at: https://github.com/nadluru/StrokeLesSeg.
Learning Label Hierarchy with Supervised Contrastive Learning
Jan 31, 2024



Supervised contrastive learning (SCL) frameworks treat each class as independent and thus consider all classes to be equally important. This neglects the common scenario in which label hierarchy exists, where fine-grained classes under the same category show more similarity than very different ones. This paper introduces a family of Label-Aware SCL methods (LASCL) that incorporates hierarchical information to SCL by leveraging similarities between classes, resulting in creating a more well-structured and discriminative feature space. This is achieved by first adjusting the distance between instances based on measures of the proximity of their classes with the scaled instance-instance-wise contrastive. An additional instance-center-wise contrastive is introduced to move within-class examples closer to their centers, which are represented by a set of learnable label parameters. The learned label parameters can be directly used as a nearest neighbor classifier without further finetuning. In this way, a better feature representation is generated with improvements of intra-cluster compactness and inter-cluster separation. Experiments on three datasets show that the proposed LASCL works well on text classification of distinguishing a single label among multi-labels, outperforming the baseline supervised approaches. Our code is publicly available.
Vision Backbone Enhancement via Multi-Stage Cross-Scale Attention
Aug 14, 2023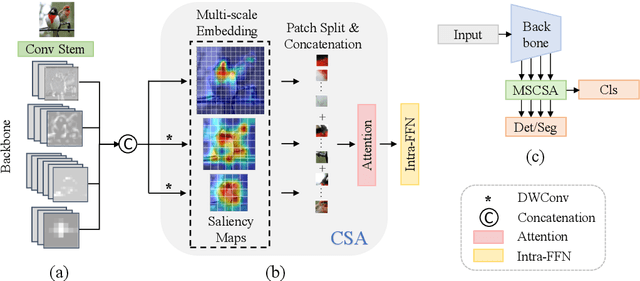



Convolutional neural networks (CNNs) and vision transformers (ViTs) have achieved remarkable success in various vision tasks. However, many architectures do not consider interactions between feature maps from different stages and scales, which may limit their performance. In this work, we propose a simple add-on attention module to overcome these limitations via multi-stage and cross-scale interactions. Specifically, the proposed Multi-Stage Cross-Scale Attention (MSCSA) module takes feature maps from different stages to enable multi-stage interactions and achieves cross-scale interactions by computing self-attention at different scales based on the multi-stage feature maps. Our experiments on several downstream tasks show that MSCSA provides a significant performance boost with modest additional FLOPs and runtime.
SpecNet: Spectral Domain Convolutional Neural Network
May 28, 2019

The memory consumption of most Convolutional Neural Network (CNN) architectures grows rapidly with increasing depth of the network, which is a major constraint for efficient network training and inference on modern GPUs with yet limited memory. Several studies show that the feature maps (as generated after the convolutional layers) are the big bottleneck in this memory problem. Often, these feature maps mimic natural photographs in the sense that their energy is concentrated in the spectral domain. This paper proposes a Spectral Domain Convolutional Neural Network (SpecNet) that performs both the convolution and the activation operations in the spectral domain to achieve memory reduction. SpecNet exploits a configurable threshold to force small values in the feature maps to zero, allowing the feature maps to be stored sparsely. Since convolution in the spatial domain is equivalent to a dot product in the spectral domain, the multiplications only need to be performed on the non-zero entries of the (sparse) spectral domain feature maps. SpecNet also employs a special activation function that preserves the sparsity of the feature maps while effectively encouraging the convergence of the network. The performance of SpecNet is evaluated on three competitive object recognition benchmark tasks (MNIST, CIFAR-10, and SVHN), and compared with four state-of-the-art implementations (LeNet, AlexNet, VGG, and DenseNet). Overall, SpecNet is able to reduce memory consumption by about 60% without significant loss of performance for all tested network architectures.
Model-Driven Applications of Fractional Derivatives and Integrals
Mar 21, 2014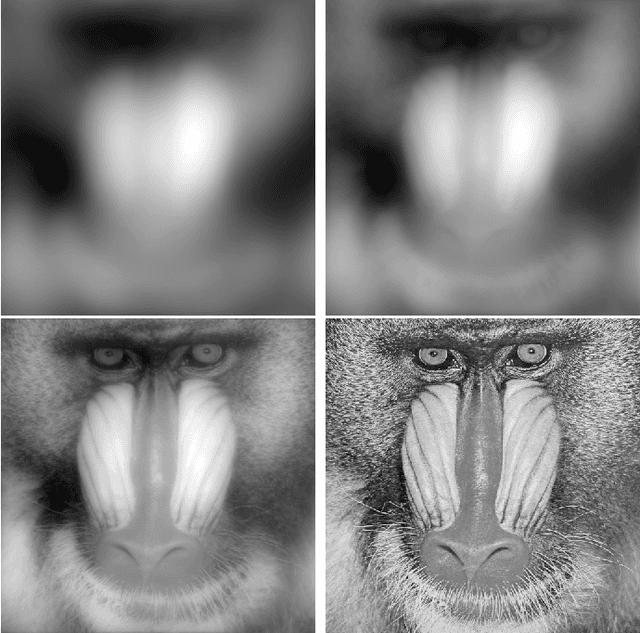

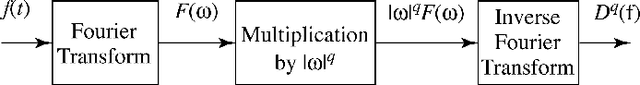
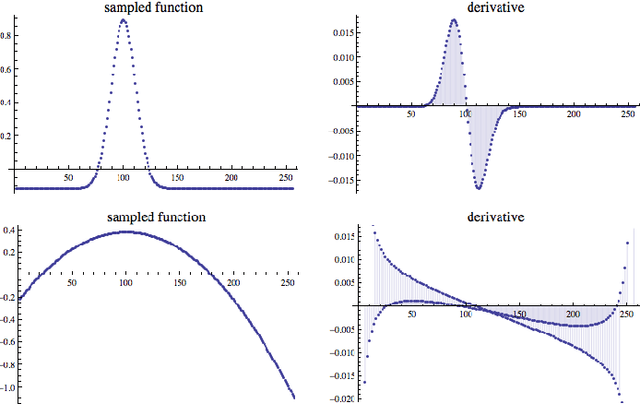
Fractional order derivatives and integrals (differintegrals) are viewed from a frequency-domain perspective using the formalism of Riesz, providing a computational tool as well as a way to interpret the operations in the frequency domain. Differintegrals provide a logical extension of current techniques, generalizing the notion of integral and differential operators and acting as kind of frequency-domain filtering that has many of the advantages of a nonlocal linear operator. Several important properties of differintegrals are presented, and sample applications are given to one- and two-dimensional signals. Computer code to carry out the computations is made available on the author's website.