 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
May 22, 2025The rapid advancement of native multi-modal models and omni-models, exemplified by GPT-4o, Gemini, and o3, with their capability to process and generate content across modalities such as text and images, marks a significant milestone in the evolution of intelligence. Systematic evaluation of their multi-modal output capabilities in visual thinking processes (also known as multi-modal chain of thought, M-CoT) becomes critically important. However, existing benchmarks for evaluating multi-modal models primarily focus on assessing multi-modal inputs and text-only reasoning while neglecting the importance of reasoning through multi-modal outputs. In this paper, we present a benchmark, dubbed RBench-V, designed to assess models' vision-indispensable reasoning abilities. To construct RBench-V, we carefully hand-pick 803 questions covering math, physics, counting, and games. Unlike previous benchmarks that typically specify certain input modalities, RBench-V presents problems centered on multi-modal outputs, which require image manipulation such as generating novel images and constructing auxiliary lines to support the reasoning process. We evaluate numerous open- and closed-source models on RBench-V, including o3, Gemini 2.5 Pro, Qwen2.5-VL, etc. Even the best-performing model, o3, achieves only 25.8% accuracy on RBench-V, far below the human score of 82.3%, highlighting that current models struggle to leverage multi-modal reasoning. Data and code are available at https://evalmodels.github.io/rbenchv
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
Jul 21, 2022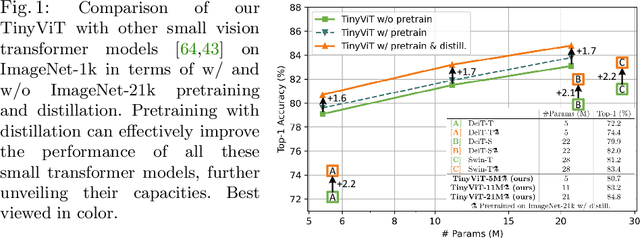
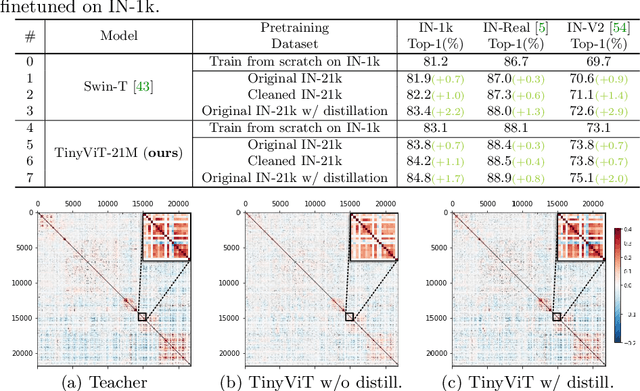
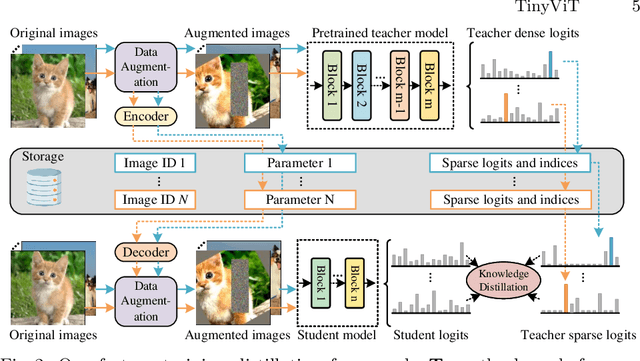

Vision transformer (ViT) recently has drawn great attention in computer vision due to its remarkable model capability. However, most prevailing ViT models suffer from huge number of parameters, restricting their applicability on devices with limited resources. To alleviate this issue, we propose TinyViT, a new family of tiny and efficient small vision transformers pretrained on large-scale datasets with our proposed fast distillation framework. The central idea is to transfer knowledge from large pretrained models to small ones, while enabling small models to get the dividends of massive pretraining data. More specifically, we apply distillation during pretraining for knowledge transfer. The logits of large teacher models are sparsified and stored in disk in advance to save the memory cost and computation overheads. The tiny student transformers are automatically scaled down from a large pretrained model with computation and parameter constraints. Comprehensive experiments demonstrate the efficacy of TinyViT. It achieves a top-1 accuracy of 84.8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4.2 times fewer parameters. Moreover, increasing image resolutions, TinyViT can reach 86.5% accuracy, being slightly better than Swin-L while using only 11% parameters. Last but not the least, we demonstrate a good transfer ability of TinyViT on various downstream tasks. Code and models are available at https://github.com/microsoft/Cream/tree/main/TinyViT.
MiniViT: Compressing Vision Transformers with Weight Multiplexing
Apr 14, 2022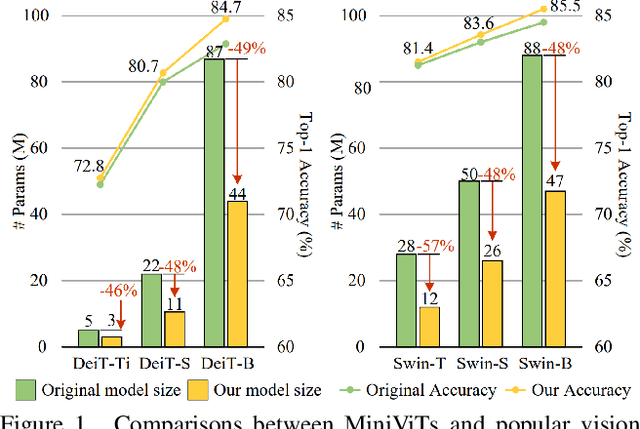
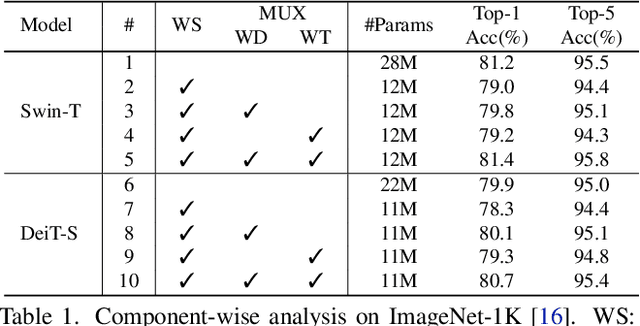
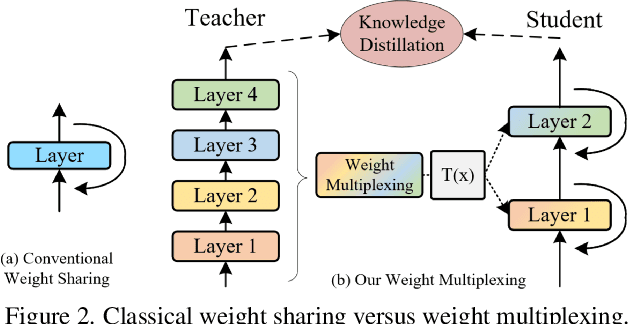
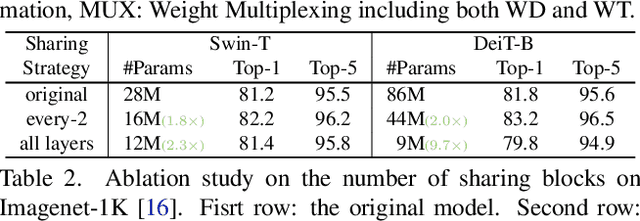
Vision Transformer (ViT) models have recently drawn much attention in computer vision due to their high model capability. However, ViT models suffer from huge number of parameters, restricting their applicability on devices with limited memory. To alleviate this problem, we propose MiniViT, a new compression framework, which achieves parameter reduction in vision transformers while retaining the same performance. The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks. More specifically, we make the weights shared across layers, while imposing a transformation on the weights to increase diversity. Weight distillation over self-attention is also applied to transfer knowledge from large-scale ViT models to weight-multiplexed compact models. Comprehensive experiments demonstrate the efficacy of MiniViT, showing that it can reduce the size of the pre-trained Swin-B transformer by 48\%, while achieving an increase of 1.0\% in Top-1 accuracy on ImageNet. Moreover, using a single-layer of parameters, MiniViT is able to compress DeiT-B by 9.7 times from 86M to 9M parameters, without seriously compromising the performance. Finally, we verify the transferability of MiniViT by reporting its performance on downstream benchmarks. Code and models are available at here.
A General Method For Automatic Discovery of Powerful Interactions In Click-Through Rate Prediction
May 21, 2021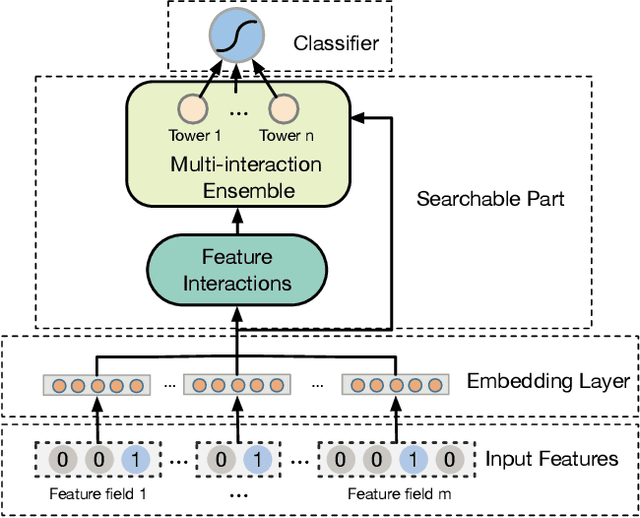
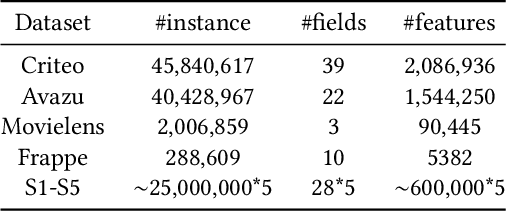
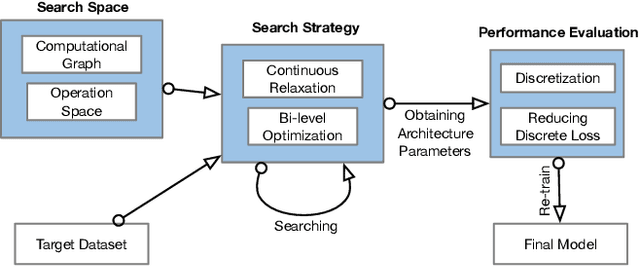
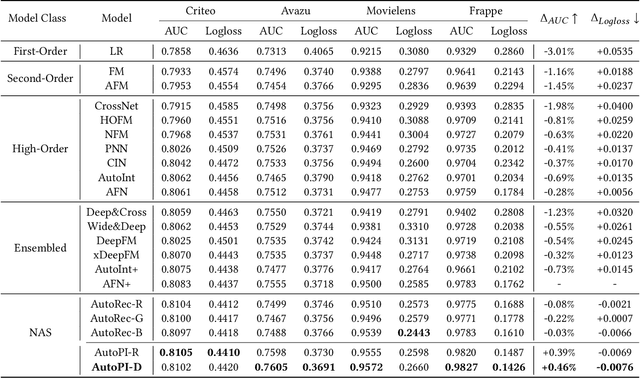
Modeling powerful interactions is a critical challenge in Click-through rate (CTR) prediction, which is one of the most typical machine learning tasks in personalized advertising and recommender systems. Although developing hand-crafted interactions is effective for a small number of datasets, it generally requires laborious and tedious architecture engineering for extensive scenarios. In recent years, several neural architecture search (NAS) methods have been proposed for designing interactions automatically. However, existing methods only explore limited types and connections of operators for interaction generation, leading to low generalization ability. To address these problems, we propose a more general automated method for building powerful interactions named AutoPI. The main contributions of this paper are as follows: AutoPI adopts a more general search space in which the computational graph is generalized from existing network connections, and the interactive operators in the edges of the graph are extracted from representative hand-crafted works. It allows searching for various powerful feature interactions to produce higher AUC and lower Logloss in a wide variety of applications. Besides, AutoPI utilizes a gradient-based search strategy for exploration with a significantly low computational cost. Experimentally, we evaluate AutoPI on a diverse suite of benchmark datasets, demonstrating the generalizability and efficiency of AutoPI over hand-crafted architectures and state-of-the-art NAS algorithms.
Robustifying deep networks for image segmentation
Aug 01, 2019Purpose: The purpose of this study is to investigate the robustness of a commonly-used convolutional neural network for image segmentation with respect to visually-subtle adversarial perturbations, and suggest new methods to make these networks more robust to such perturbations. Materials and Methods: In this retrospective study, the accuracy of brain tumor segmentation was studied in subjects with low- and high-grade gliomas. A three-dimensional UNet model was implemented to segment four different MR series (T1-weighted, post-contrast T1-weighted, T2- weighted, and T2-weighted FLAIR) into four pixelwise labels (Gd-enhancing tumor, peritumoral edema, necrotic and non-enhancing tumor, and background). We developed attack strategies based on the Fast Gradient Sign Method (FGSM), iterative FGSM (i-FGSM), and targeted iterative FGSM (ti-FGSM) to produce effective attacks. Additionally, we explored the effectiveness of distillation and adversarial training via data augmentation to counteract adversarial attacks. Robustness was measured by comparing the Dice coefficient for each attack method using Wilcoxon signed-rank tests. Results: Attacks based on FGSM, i-FGSM, and ti-FGSM were effective in significantly reducing the quality of image segmentation with reductions in Dice coefficient by up to 65%. For attack defenses, distillation performed significantly better than adversarial training approaches. However, all defense approaches performed worse compared to unperturbed test images. Conclusion: Segmentation networks can be adversely affected by targeted attacks that introduce visually minor (and potentially undetectable) modifications to existing images. With an increasing interest in applying deep learning techniques to medical imaging data, it is important to quantify the ramifications of adversarial inputs (either intentional or unintentional).
SpecNet: Spectral Domain Convolutional Neural Network
May 28, 2019
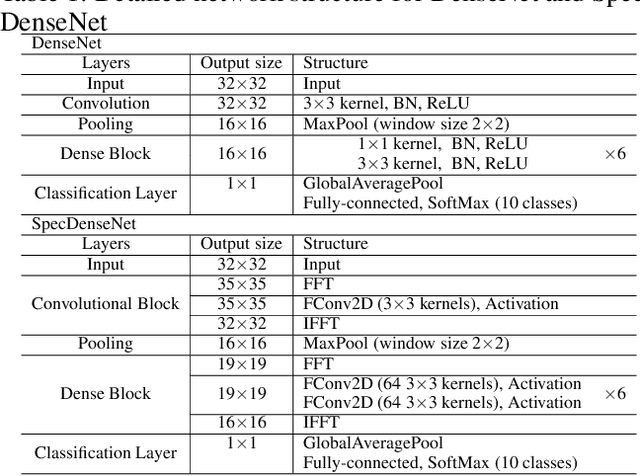

The memory consumption of most Convolutional Neural Network (CNN) architectures grows rapidly with increasing depth of the network, which is a major constraint for efficient network training and inference on modern GPUs with yet limited memory. Several studies show that the feature maps (as generated after the convolutional layers) are the big bottleneck in this memory problem. Often, these feature maps mimic natural photographs in the sense that their energy is concentrated in the spectral domain. This paper proposes a Spectral Domain Convolutional Neural Network (SpecNet) that performs both the convolution and the activation operations in the spectral domain to achieve memory reduction. SpecNet exploits a configurable threshold to force small values in the feature maps to zero, allowing the feature maps to be stored sparsely. Since convolution in the spatial domain is equivalent to a dot product in the spectral domain, the multiplications only need to be performed on the non-zero entries of the (sparse) spectral domain feature maps. SpecNet also employs a special activation function that preserves the sparsity of the feature maps while effectively encouraging the convergence of the network. The performance of SpecNet is evaluated on three competitive object recognition benchmark tasks (MNIST, CIFAR-10, and SVHN), and compared with four state-of-the-art implementations (LeNet, AlexNet, VGG, and DenseNet). Overall, SpecNet is able to reduce memory consumption by about 60% without significant loss of performance for all tested network architectures.