 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindClaw: Closed-Loop Embodied Mental-State Reasoning for Precision Intervention
May 31, 2026Theory of Mind (ToM) enables an agent to reason about another actor's beliefs, goals, and intentions, which is essential for human-centered embodied assistance. Existing ToM benchmarks have advanced text and multimodal mental-state recognition, but they mostly evaluate offline question answering or final action prediction. They do not fully test whether an embodied agent can stay connected to a changing environment, update actor-specific beliefs, decide when reasoning is needed, and intervene only when help is useful. Building on MindPower, we extend robot-centric ToM reasoning to a real-time closed-loop setting and introduce MindClaw, a framework for embodied mental-state reasoning with precision intervention. MindClaw connects multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation, allowing the agent to output helpful actions at the right time while remaining silent when intervention is unnecessary. Experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance, demonstrating the importance of trigger-skill optimization for closed-loop embodied ToM assistance.
Latent Policy Steering through One-Step Flow Policies
Mar 05, 2026Offline reinforcement learning (RL) allows robots to learn from offline datasets without risky exploration. Yet, offline RL's performance often hinges on a brittle trade-off between (1) return maximization, which can push policies outside the dataset support, and (2) behavioral constraints, which typically require sensitive hyperparameter tuning. Latent steering offers a structural way to stay within the dataset support during RL, but existing offline adaptations commonly approximate action values using latent-space critics learned via indirect distillation, which can lose information and hinder convergence. We propose Latent Policy Steering (LPS), which enables high-fidelity latent policy improvement by backpropagating original-action-space Q-gradients through a differentiable one-step MeanFlow policy to update a latent-action-space actor. By eliminating proxy latent critics, LPS allows an original-action-space critic to guide end-to-end latent-space optimization, while the one-step MeanFlow policy serves as a behavior-constrained generative prior. This decoupling yields a robust method that works out-of-the-box with minimal tuning. Across OGBench and real-world robotic tasks, LPS achieves state-of-the-art performance and consistently outperforms behavioral cloning and strong latent steering baselines.
LoLA: Long Horizon Latent Action Learning for General Robot Manipulation
Dec 23, 2025The capability of performing long-horizon, language-guided robotic manipulation tasks critically relies on leveraging historical information and generating coherent action sequences. However, such capabilities are often overlooked by existing Vision-Language-Action (VLA) models. To solve this challenge, we propose LoLA (Long Horizon Latent Action Learning), a framework designed for robot manipulation that integrates long-term multi-view observations and robot proprioception to enable multi-step reasoning and action generation. We first employ Vision-Language Models to encode rich contextual features from historical sequences and multi-view observations. We further introduces a key module, State-Aware Latent Re-representation, which transforms visual inputs and language commands into actionable robot motion space. Unlike existing VLA approaches that merely concatenate robot proprioception (e.g., joint angles) with VL embeddings, this module leverages such robot states to explicitly ground VL representations in physical scale through a learnable "embodiment-anchored" latent space. We trained LoLA on diverse robotic pre-training datasets and conducted extensive evaluations on simulation benchmarks (SIMPLER and LIBERO), as well as two real-world tasks on Franka and Bi-Manual Aloha robots. Results show that LoLA significantly outperforms prior state-of-the-art methods (e.g., pi0), particularly in long-horizon manipulation tasks.
TwinVLA: Data-Efficient Bimanual Manipulation with Twin Single-Arm Vision-Language-Action Models
Nov 07, 2025Vision-language-action models (VLAs) trained on large-scale robotic datasets have demonstrated strong performance on manipulation tasks, including bimanual tasks. However, because most public datasets focus on single-arm demonstrations, adapting VLAs for bimanual tasks typically requires substantial additional bimanual data and fine-tuning. To address this challenge, we introduce TwinVLA, a modular framework that composes two copies of a pretrained single-arm VLA into a coordinated bimanual VLA. Unlike monolithic cross-embodiment models trained on mixtures of single-arm and bimanual data, TwinVLA improves both data efficiency and performance by composing pretrained single-arm policies. Across diverse bimanual tasks in real-world and simulation settings, TwinVLA outperforms a comparably-sized monolithic RDT-1B model without requiring any bimanual pretraining. Furthermore, it narrows the gap to state-of-the-art model, $π_0$ which rely on extensive proprietary bimanual data and compute cost. These results establish our modular composition approach as a data-efficient and scalable path toward high-performance bimanual manipulation, leveraging public single-arm data.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
PromptFix: You Prompt and We Fix the Photo
May 27, 2024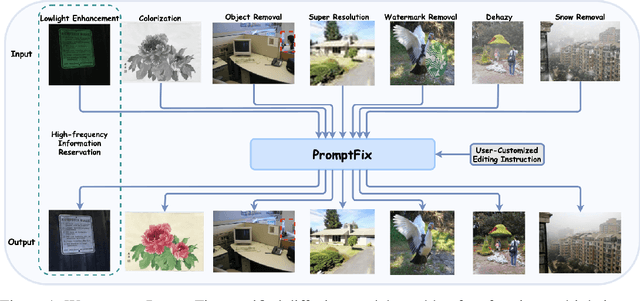
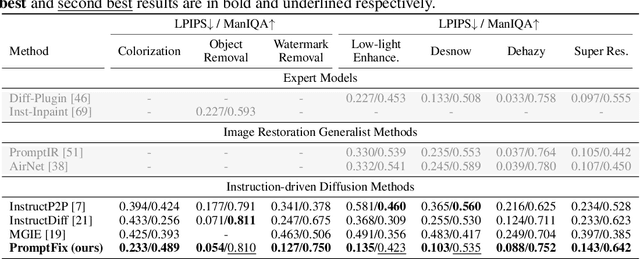
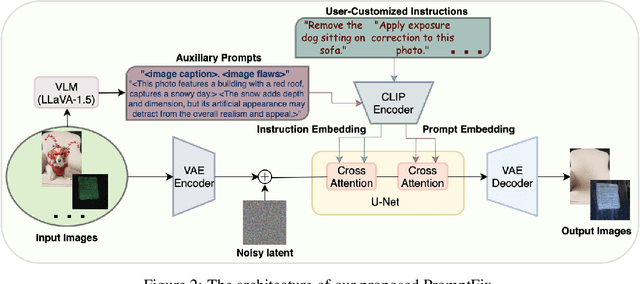

Diffusion models equipped with language models demonstrate excellent controllability in image generation tasks, allowing image processing to adhere to human instructions. However, the lack of diverse instruction-following data hampers the development of models that effectively recognize and execute user-customized instructions, particularly in low-level tasks. Moreover, the stochastic nature of the diffusion process leads to deficiencies in image generation or editing tasks that require the detailed preservation of the generated images. To address these limitations, we propose PromptFix, a comprehensive framework that enables diffusion models to follow human instructions to perform a wide variety of image-processing tasks. First, we construct a large-scale instruction-following dataset that covers comprehensive image-processing tasks, including low-level tasks, image editing, and object creation. Next, we propose a high-frequency guidance sampling method to explicitly control the denoising process and preserve high-frequency details in unprocessed areas. Finally, we design an auxiliary prompting adapter, utilizing Vision-Language Models (VLMs) to enhance text prompts and improve the model's task generalization. Experimental results show that PromptFix outperforms previous methods in various image-processing tasks. Our proposed model also achieves comparable inference efficiency with these baseline models and exhibits superior zero-shot capabilities in blind restoration and combination tasks. The dataset and code will be aviliable at https://github.com/yeates/PromptFix.
Zero-Reference Low-Light Enhancement via Physical Quadruple Priors
Mar 19, 2024



Understanding illumination and reducing the need for supervision pose a significant challenge in low-light enhancement. Current approaches are highly sensitive to data usage during training and illumination-specific hyper-parameters, limiting their ability to handle unseen scenarios. In this paper, we propose a new zero-reference low-light enhancement framework trainable solely with normal light images. To accomplish this, we devise an illumination-invariant prior inspired by the theory of physical light transfer. This prior serves as the bridge between normal and low-light images. Then, we develop a prior-to-image framework trained without low-light data. During testing, this framework is able to restore our illumination-invariant prior back to images, automatically achieving low-light enhancement. Within this framework, we leverage a pretrained generative diffusion model for model ability, introduce a bypass decoder to handle detail distortion, as well as offer a lightweight version for practicality. Extensive experiments demonstrate our framework's superiority in various scenarios as well as good interpretability, robustness, and efficiency. Code is available on our project homepage: http://daooshee.github.io/QuadPrior-Website/
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Mar 14, 2024Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal predictive learning utilizing large-scale video data, termed as STP. Our STP samples paired frames from video clips. It adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. These efficient designs ensure that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training.
Multi-task Manipulation Policy Modeling with Visuomotor Latent Diffusion
Mar 12, 2024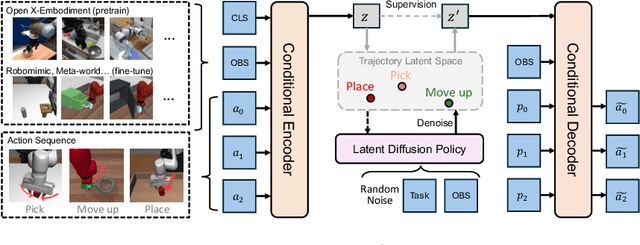
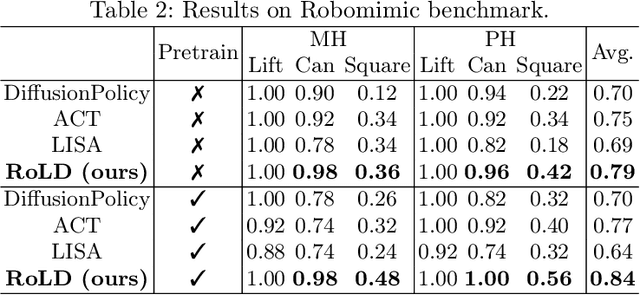
Modeling a generalized visuomotor policy has been a longstanding challenge for both computer vision and robotics communities. Existing approaches often fail to efficiently leverage cross-dataset resources or rely on heavy Vision-Language models, which require substantial computational resources, thereby limiting their multi-task performance and application potential. In this paper, we introduce a novel paradigm that effectively utilizes latent modeling of manipulation skills and an efficient visuomotor latent diffusion policy, which enhances the utilizing of existing cross-embodiment and cross-environment datasets, thereby improving multi-task capabilities. Our methodology consists of two decoupled phases: action modeling and policy modeling. Firstly, we introduce a task-agnostic, embodiment-aware trajectory latent autoencoder for unified action skills modeling. This step condenses action data and observation into a condensed latent space, effectively benefiting from large-scale cross-datasets. Secondly, we propose to use a visuomotor latent diffusion policy that recovers target skill latent from noises for effective task execution. We conducted extensive experiments on two widely used benchmarks, and the results demonstrate the effectiveness of our proposed paradigms on multi-tasking and pre-training. Code is available at https://github.com/AlbertTan404/RoLD.
Learning Position-Aware Implicit Neural Network for Real-World Face Inpainting
Jan 19, 2024Face inpainting requires the model to have a precise global understanding of the facial position structure. Benefiting from the powerful capabilities of deep learning backbones, recent works in face inpainting have achieved decent performance in ideal setting (square shape with $512px$). However, existing methods often produce a visually unpleasant result, especially in the position-sensitive details (e.g., eyes and nose), when directly applied to arbitrary-shaped images in real-world scenarios. The visually unpleasant position-sensitive details indicate the shortcomings of existing methods in terms of position information processing capability. In this paper, we propose an \textbf{I}mplicit \textbf{N}eural \textbf{I}npainting \textbf{N}etwork (IN$^2$) to handle arbitrary-shape face images in real-world scenarios by explicit modeling for position information. Specifically, a downsample processing encoder is proposed to reduce information loss while obtaining the global semantic feature. A neighbor hybrid attention block is proposed with a hybrid attention mechanism to improve the facial understanding ability of the model without restricting the shape of the input. Finally, an implicit neural pyramid decoder is introduced to explicitly model position information and bridge the gap between low-resolution features and high-resolution output. Extensive experiments demonstrate the superiority of the proposed method in real-world face inpainting task.