 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIPER: Generalizable Factorized Fields for Joint Image Compression and Super-Resolution
Oct 23, 2024In this work, we propose a unified representation for Super-Resolution (SR) and Image Compression, termed **Factorized Fields**, motivated by the shared principles between these two tasks. Both SISR and Image Compression require recovering and preserving fine image details--whether by enhancing resolution or reconstructing compressed data. Unlike previous methods that mainly focus on network architecture, our proposed approach utilizes a basis-coefficient decomposition to explicitly capture multi-scale visual features and structural components in images, addressing the core challenges of both tasks. We first derive our SR model, which includes a Coefficient Backbone and Basis Swin Transformer for generalizable Factorized Fields. Then, to further unify these two tasks, we leverage the strong information-recovery capabilities of the trained SR modules as priors in the compression pipeline, improving both compression efficiency and detail reconstruction. Additionally, we introduce a merged-basis compression branch that consolidates shared structures, further optimizing the compression process. Extensive experiments show that our unified representation delivers state-of-the-art performance, achieving an average relative improvement of 204.4% in PSNR over the baseline in Super-Resolution (SR) and 9.35% BD-rate reduction in Image Compression compared to the previous SOTA.
SINC: Self-Supervised In-Context Learning for Vision-Language Tasks
Jul 15, 2023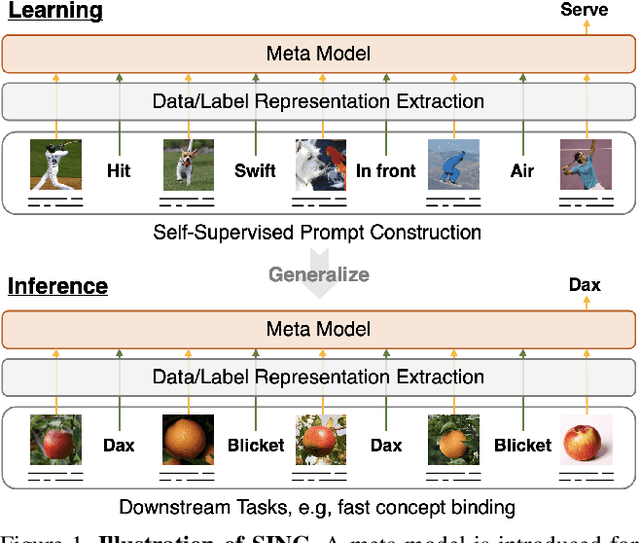
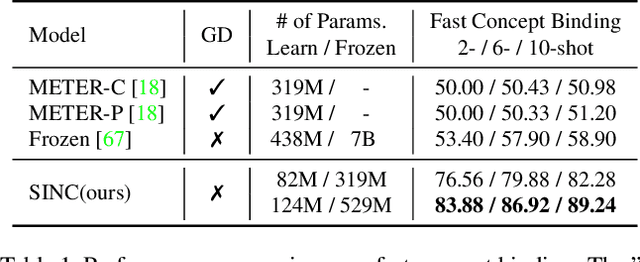
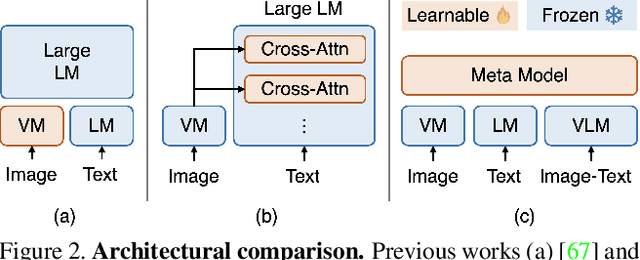
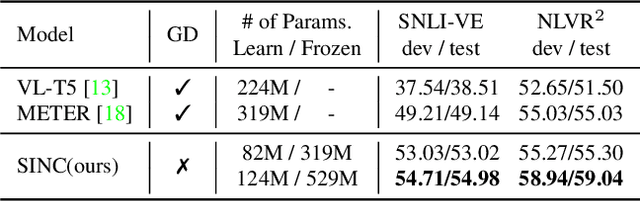
Large Pre-trained Transformers exhibit an intriguing capacity for in-context learning. Without gradient updates, these models can rapidly construct new predictors from demonstrations presented in the inputs. Recent works promote this ability in the vision-language domain by incorporating visual information into large language models that can already make in-context predictions. However, these methods could inherit issues in the language domain, such as template sensitivity and hallucination. Also, the scale of these language models raises a significant demand for computations, making learning and operating these models resource-intensive. To this end, we raise a question: ``How can we enable in-context learning for general models without being constrained on large language models?". To answer it, we propose a succinct and general framework, Self-supervised IN-Context learning (SINC), that introduces a meta-model to learn on self-supervised prompts consisting of tailored demonstrations. The learned models can be transferred to downstream tasks for making in-context predictions on-the-fly. Extensive experiments show that SINC outperforms gradient-based methods in various vision-language tasks under few-shot settings. Furthermore, the designs of SINC help us investigate the benefits of in-context learning across different tasks, and the analysis further reveals the essential components for the emergence of in-context learning in the vision-language domain.