 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINC: Self-Supervised In-Context Learning for Vision-Language Tasks
Jul 15, 2023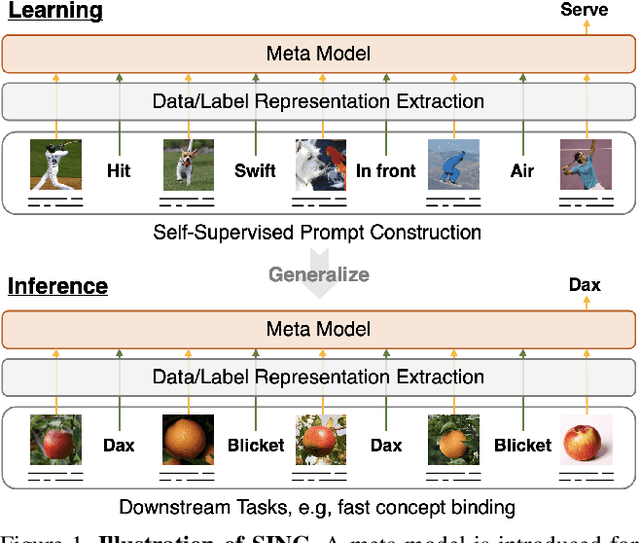
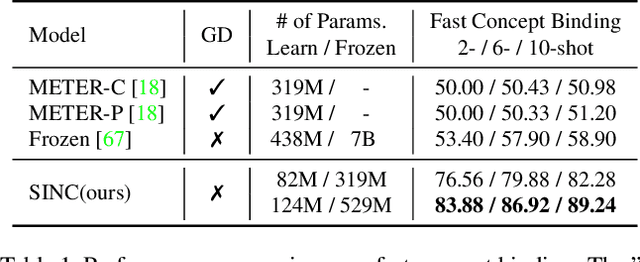
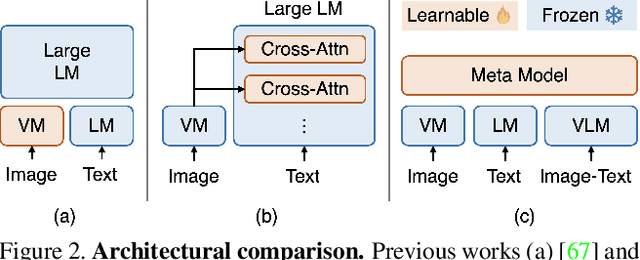
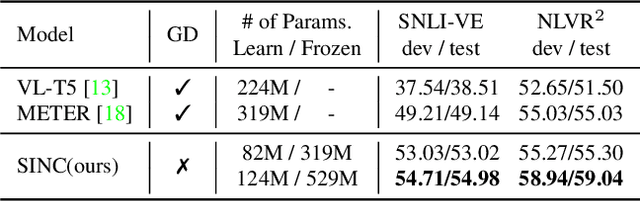
Large Pre-trained Transformers exhibit an intriguing capacity for in-context learning. Without gradient updates, these models can rapidly construct new predictors from demonstrations presented in the inputs. Recent works promote this ability in the vision-language domain by incorporating visual information into large language models that can already make in-context predictions. However, these methods could inherit issues in the language domain, such as template sensitivity and hallucination. Also, the scale of these language models raises a significant demand for computations, making learning and operating these models resource-intensive. To this end, we raise a question: ``How can we enable in-context learning for general models without being constrained on large language models?". To answer it, we propose a succinct and general framework, Self-supervised IN-Context learning (SINC), that introduces a meta-model to learn on self-supervised prompts consisting of tailored demonstrations. The learned models can be transferred to downstream tasks for making in-context predictions on-the-fly. Extensive experiments show that SINC outperforms gradient-based methods in various vision-language tasks under few-shot settings. Furthermore, the designs of SINC help us investigate the benefits of in-context learning across different tasks, and the analysis further reveals the essential components for the emergence of in-context learning in the vision-language domain.
Shilling Black-box Review-based Recommender Systems through Fake Review Generation
Jun 27, 2023



Review-Based Recommender Systems (RBRS) have attracted increasing research interest due to their ability to alleviate well-known cold-start problems. RBRS utilizes reviews to construct the user and items representations. However, in this paper, we argue that such a reliance on reviews may instead expose systems to the risk of being shilled. To explore this possibility, in this paper, we propose the first generation-based model for shilling attacks against RBRSs. Specifically, we learn a fake review generator through reinforcement learning, which maliciously promotes items by forcing prediction shifts after adding generated reviews to the system. By introducing the auxiliary rewards to increase text fluency and diversity with the aid of pre-trained language models and aspect predictors, the generated reviews can be effective for shilling with high fidelity. Experimental results demonstrate that the proposed framework can successfully attack three different kinds of RBRSs on the Amazon corpus with three domains and Yelp corpus. Furthermore, human studies also show that the generated reviews are fluent and informative. Finally, equipped with Attack Review Generators (ARGs), RBRSs with adversarial training are much more robust to malicious reviews.
SPEC: Summary Preference Decomposition for Low-Resource Abstractive Summarization
Mar 24, 2023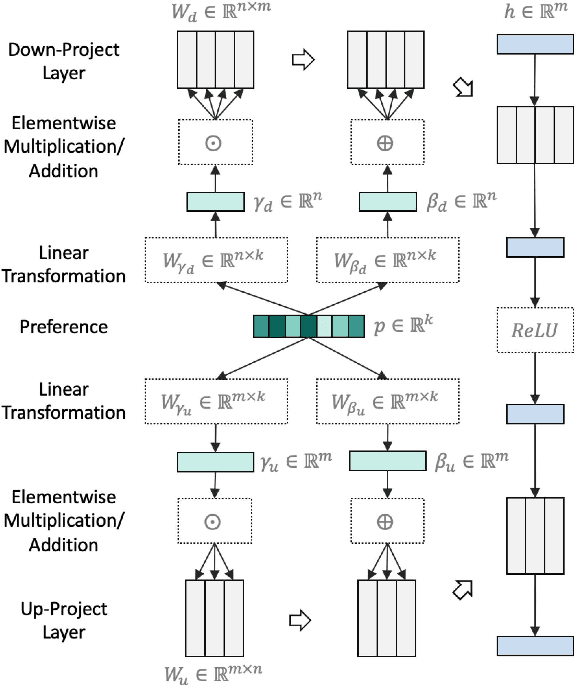



Neural abstractive summarization has been widely studied and achieved great success with large-scale corpora. However, the considerable cost of annotating data motivates the need for learning strategies under low-resource settings. In this paper, we investigate the problems of learning summarizers with only few examples and propose corresponding methods for improvements. First, typical transfer learning methods are prone to be affected by data properties and learning objectives in the pretext tasks. Therefore, based on pretrained language models, we further present a meta learning framework to transfer few-shot learning processes from source corpora to the target corpus. Second, previous methods learn from training examples without decomposing the content and preference. The generated summaries could therefore be constrained by the preference bias in the training set, especially under low-resource settings. As such, we propose decomposing the contents and preferences during learning through the parameter modulation, which enables control over preferences during inference. Third, given a target application, specifying required preferences could be non-trivial because the preferences may be difficult to derive through observations. Therefore, we propose a novel decoding method to automatically estimate suitable preferences and generate corresponding summary candidates from the few training examples. Extensive experiments demonstrate that our methods achieve state-of-the-art performance on six diverse corpora with 30.11%/33.95%/27.51% and 26.74%/31.14%/24.48% average improvements on ROUGE-1/2/L under 10- and 100-example settings.
Improving Multi-Document Summarization through Referenced Flexible Extraction with Credit-Awareness
May 04, 2022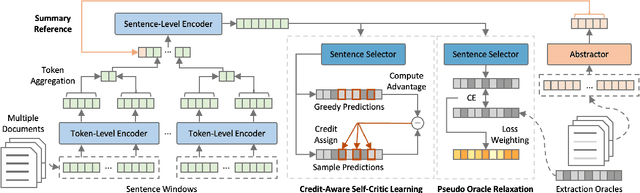



A notable challenge in Multi-Document Summarization (MDS) is the extremely-long length of the input. In this paper, we present an extract-then-abstract Transformer framework to overcome the problem. Specifically, we leverage pre-trained language models to construct a hierarchical extractor for salient sentence selection across documents and an abstractor for rewriting the selected contents as summaries. However, learning such a framework is challenging since the optimal contents for the abstractor are generally unknown. Previous works typically create pseudo extraction oracle to enable the supervised learning for both the extractor and the abstractor. Nevertheless, we argue that the performance of such methods could be restricted due to the insufficient information for prediction and inconsistent objectives between training and testing. To this end, we propose a loss weighting mechanism that makes the model aware of the unequal importance for the sentences not in the pseudo extraction oracle, and leverage the fine-tuned abstractor to generate summary references as auxiliary signals for learning the extractor. Moreover, we propose a reinforcement learning method that can efficiently apply to the extractor for harmonizing the optimization between training and testing. Experiment results show that our framework substantially outperforms strong baselines with comparable model sizes and achieves the best results on the Multi-News, Multi-XScience, and WikiCatSum corpora.
Attractive or Faithful? Popularity-Reinforced Learning for Inspired Headline Generation
Feb 06, 2020
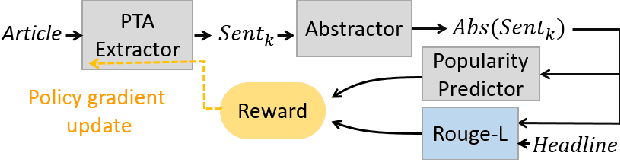


With the rapid proliferation of online media sources and published news, headlines have become increasingly important for attracting readers to news articles, since users may be overwhelmed with the massive information. In this paper, we generate inspired headlines that preserve the nature of news articles and catch the eye of the reader simultaneously. The task of inspired headline generation can be viewed as a specific form of Headline Generation (HG) task, with the emphasis on creating an attractive headline from a given news article. To generate inspired headlines, we propose a novel framework called POpularity-Reinforced Learning for inspired Headline Generation (PORL-HG). PORL-HG exploits the extractive-abstractive architecture with 1) Popular Topic Attention (PTA) for guiding the extractor to select the attractive sentence from the article and 2) a popularity predictor for guiding the abstractor to rewrite the attractive sentence. Moreover, since the sentence selection of the extractor is not differentiable, techniques of reinforcement learning (RL) are utilized to bridge the gap with rewards obtained from a popularity score predictor. Through quantitative and qualitative experiments, we show that the proposed PORL-HG significantly outperforms the state-of-the-art headline generation models in terms of attractiveness evaluated by both human (71.03%) and the predictor (at least 27.60%), while the faithfulness of PORL-HG is also comparable to the state-of-the-art generation model.