 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speech Representations with Variational Predictive Coding
Dec 31, 2025Despite being the best known objective for learning speech representations, the HuBERT objective has not been further developed and improved. We argue that it is the lack of an underlying principle that stalls the development, and, in this paper, we show that predictive coding under a variational view is the principle behind the HuBERT objective. Due to its generality, our formulation provides opportunities to improve parameterization and optimization, and we show two simple modifications that bring immediate improvements to the HuBERT objective. In addition, the predictive coding formulation has tight connections to various other objectives, such as APC, CPC, wav2vec, and BEST-RQ. Empirically, the improvement in pre-training brings significant improvements to four downstream tasks: phone classification, f0 tracking, speaker recognition, and automatic speech recognition, highlighting the importance of the predictive coding interpretation.
Estimating the Completeness of Discrete Speech Units
Sep 09, 2024
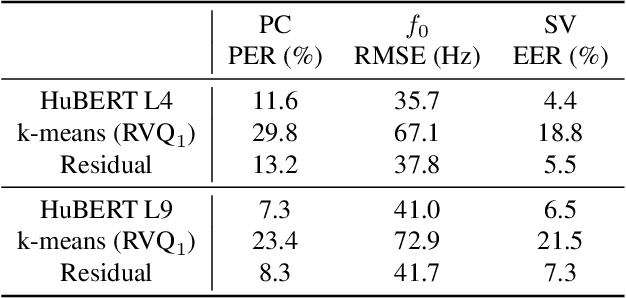

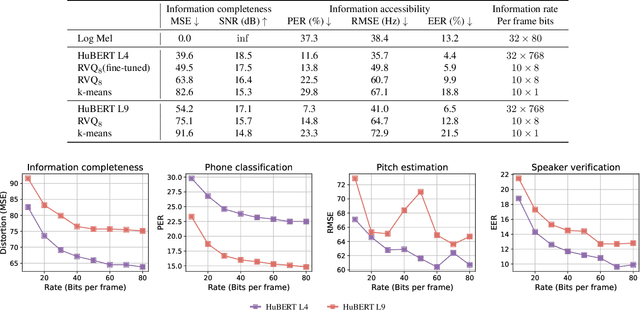
Representing speech with discrete units has been widely used in speech codec and speech generation. However, there are several unverified claims about self-supervised discrete units, such as disentangling phonetic and speaker information with k-means, or assuming information loss after k-means. In this work, we take an information-theoretic perspective to answer how much information is present (information completeness) and how much information is accessible (information accessibility), before and after residual vector quantization. We show a lower bound for information completeness and estimate completeness on discretized HuBERT representations after residual vector quantization. We find that speaker information is sufficiently present in HuBERT discrete units, and that phonetic information is sufficiently present in the residual, showing that vector quantization does not achieve disentanglement. Our results offer a comprehensive assessment on the choice of discrete units, and suggest that a lot more information in the residual should be mined rather than discarded.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024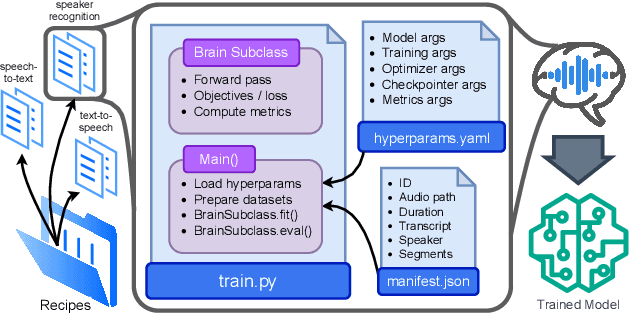

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Revisiting Self-supervised Learning of Speech Representation from a Mutual Information Perspective
Jan 16, 2024
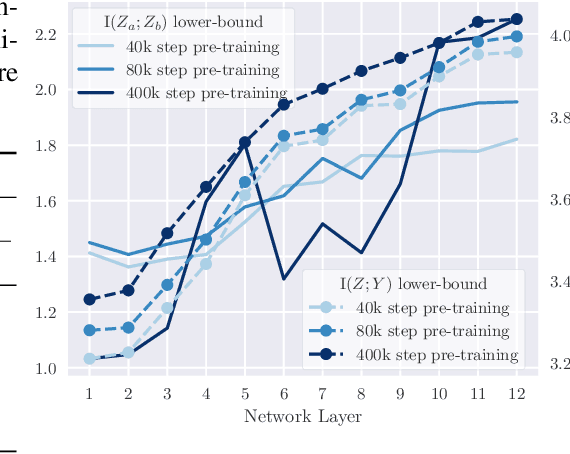
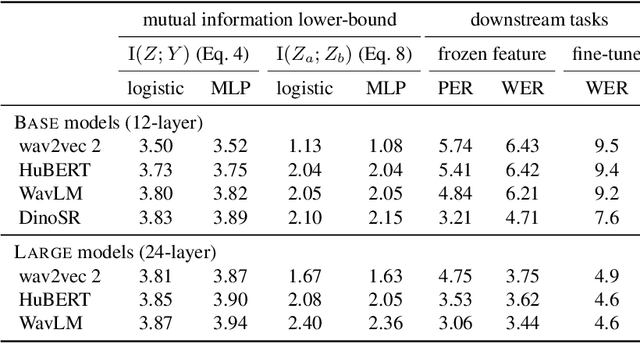

Existing studies on self-supervised speech representation learning have focused on developing new training methods and applying pre-trained models for different applications. However, the quality of these models is often measured by the performance of different downstream tasks. How well the representations access the information of interest is less studied. In this work, we take a closer look into existing self-supervised methods of speech from an information-theoretic perspective. We aim to develop metrics using mutual information to help practical problems such as model design and selection. We use linear probes to estimate the mutual information between the target information and learned representations, showing another insight into the accessibility to the target information from speech representations. Further, we explore the potential of evaluating representations in a self-supervised fashion, where we estimate the mutual information between different parts of the data without using any labels. Finally, we show that both supervised and unsupervised measures echo the performance of the models on layer-wise linear probing and speech recognition.
Learning Dependencies of Discrete Speech Representations with Neural Hidden Markov Models
Oct 29, 2022While discrete latent variable models have had great success in self-supervised learning, most models assume that frames are independent. Due to the segmental nature of phonemes in speech perception, modeling dependencies among latent variables at the frame level can potentially improve the learned representations on phonetic-related tasks. In this work, we assume Markovian dependencies among latent variables, and propose to learn speech representations with neural hidden Markov models. Our general framework allows us to compare to self-supervised models that assume independence, while keeping the number of parameters fixed. The added dependencies improve the accessibility of phonetic information, phonetic segmentation, and the cluster purity of phones, showcasing the benefit of the assumed dependencies.
Conditioning and Sampling in Variational Diffusion Models for Speech Super-resolution
Oct 27, 2022



Recently, diffusion models (DMs) have been increasingly used in audio processing tasks, including speech super-resolution (SR), which aims to restore high-frequency content given low-resolution speech utterances. This is commonly achieved by conditioning the network of noise predictor with low-resolution audio. In this paper, we propose a novel sampling algorithm that communicates the information of the low-resolution audio via the reverse sampling process of DMs. The proposed method can be a drop-in replacement for the vanilla sampling process and can significantly improve the performance of the existing works. Moreover, by coupling the proposed sampling method with an unconditional DM, i.e., a DM with no auxiliary inputs to its noise predictor, we can generalize it to a wide range of SR setups. We also attain state-of-the-art results on the VCTK Multi-Speaker benchmark with this novel formulation.
Autoregressive Co-Training for Learning Discrete Speech Representations
Mar 29, 2022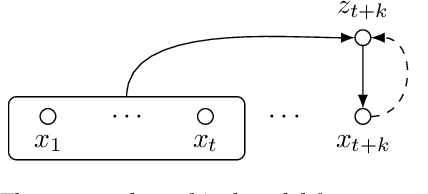
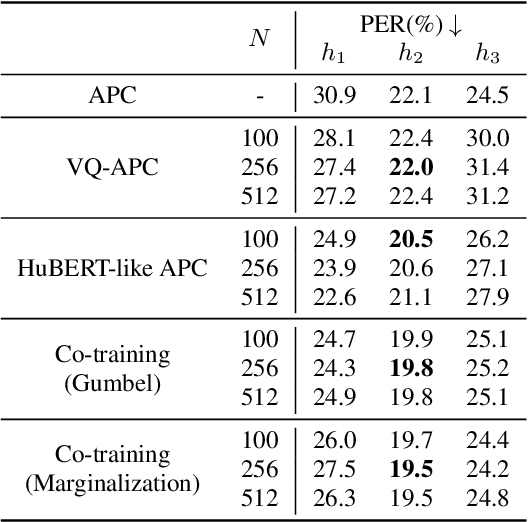
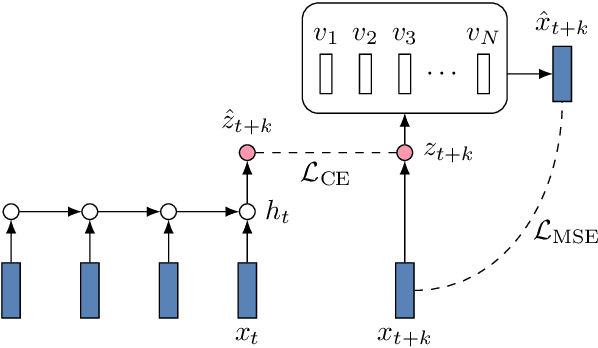
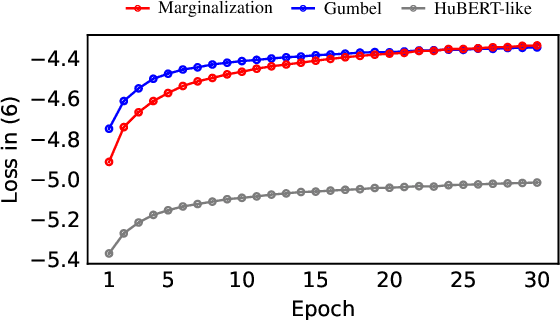
While several self-supervised approaches for learning discrete speech representation have been proposed, it is unclear how these seemingly similar approaches relate to each other. In this paper, we consider a generative model with discrete latent variables that learns a discrete representation for speech. The objective of learning the generative model is formulated as information-theoretic co-training. Besides the wide generality, the objective can be optimized with several approaches, subsuming HuBERT-like training and vector quantization for learning discrete representation. Empirically, we find that the proposed approach learns discrete representation that is highly correlated with phonetic units, more correlated than HuBERT-like training and vector quantization.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021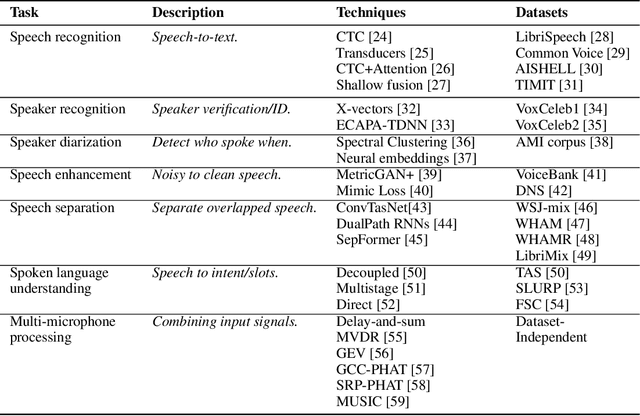
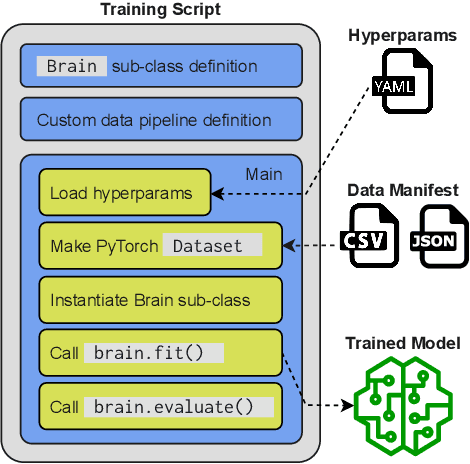

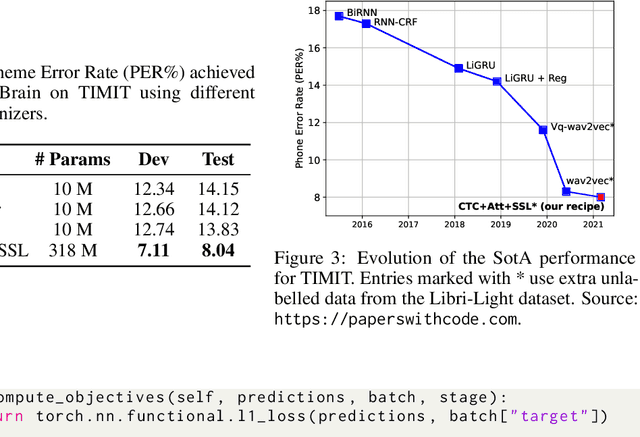
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Attractive or Faithful? Popularity-Reinforced Learning for Inspired Headline Generation
Feb 06, 2020
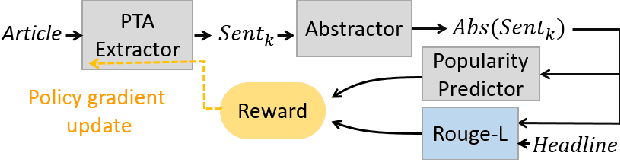


With the rapid proliferation of online media sources and published news, headlines have become increasingly important for attracting readers to news articles, since users may be overwhelmed with the massive information. In this paper, we generate inspired headlines that preserve the nature of news articles and catch the eye of the reader simultaneously. The task of inspired headline generation can be viewed as a specific form of Headline Generation (HG) task, with the emphasis on creating an attractive headline from a given news article. To generate inspired headlines, we propose a novel framework called POpularity-Reinforced Learning for inspired Headline Generation (PORL-HG). PORL-HG exploits the extractive-abstractive architecture with 1) Popular Topic Attention (PTA) for guiding the extractor to select the attractive sentence from the article and 2) a popularity predictor for guiding the abstractor to rewrite the attractive sentence. Moreover, since the sentence selection of the extractor is not differentiable, techniques of reinforcement learning (RL) are utilized to bridge the gap with rewards obtained from a popularity score predictor. Through quantitative and qualitative experiments, we show that the proposed PORL-HG significantly outperforms the state-of-the-art headline generation models in terms of attractiveness evaluated by both human (71.03%) and the predictor (at least 27.60%), while the faithfulness of PORL-HG is also comparable to the state-of-the-art generation model.