 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Speech Tasks in Human Expert and Machine Detection of Parkinson's Disease
Oct 08, 2025The speech of people with Parkinson's Disease (PD) has been shown to hold important clues about the presence and progression of the disease. We investigate the factors based on which humans experts make judgments of the presence of disease in speech samples over five different speech tasks: phonations, sentence repetition, reading, recall, and picture description. We make comparisons by conducting listening tests to determine clinicians accuracy at recognizing signs of PD from audio alone, and we conduct experiments with a machine learning system for detection based on Whisper. Across tasks, Whisper performs on par or better than human experts when only audio is available, especially on challenging but important subgroups of the data: younger patients, mild cases, and female patients. Whisper's ability to recognize acoustic cues in difficult cases complements the multimodal and contextual strengths of human experts.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024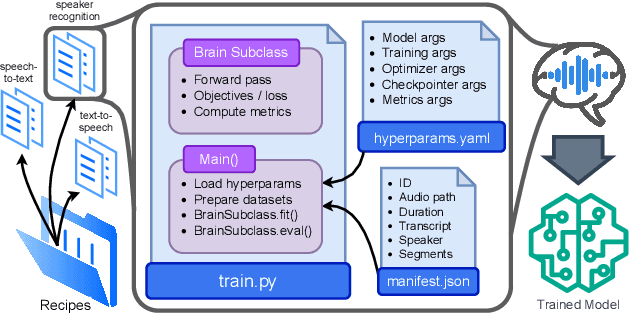

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Continual Learning for End-to-End ASR by Averaging Domain Experts
May 12, 2023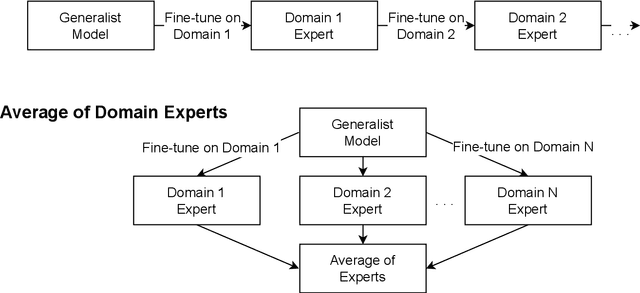
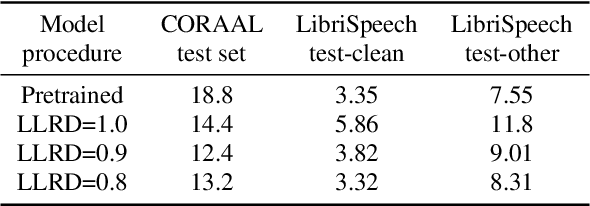
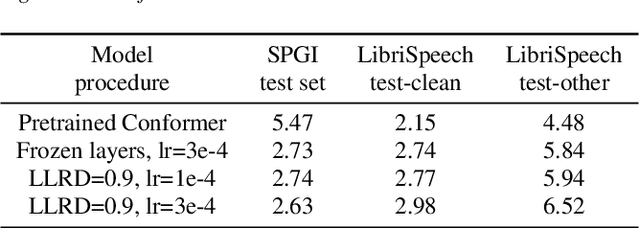
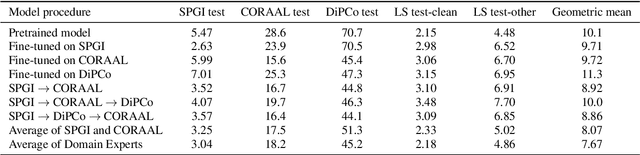
Continual learning for end-to-end automatic speech recognition has to contend with a number of difficulties. Fine-tuning strategies tend to lose performance on data already seen, a process known as catastrophic forgetting. On the other hand, strategies that freeze parameters and append tunable parameters must maintain multiple models. We suggest a strategy that maintains only a single model for inference and avoids catastrophic forgetting. Our experiments show that a simple linear interpolation of several models' parameters, each fine-tuned from the same generalist model, results in a single model that performs well on all tested data. For our experiments we selected two open-source end-to-end speech recognition models pre-trained on large datasets and fine-tuned them on 3 separate datasets: SGPISpeech, CORAAL, and DiPCo. The proposed average of domain experts model performs well on all tested data, and has almost no loss in performance on data from the domain of original training.
Perceptual Loss with Recognition Model for Single-Channel Enhancement and Robust ASR
Dec 11, 2021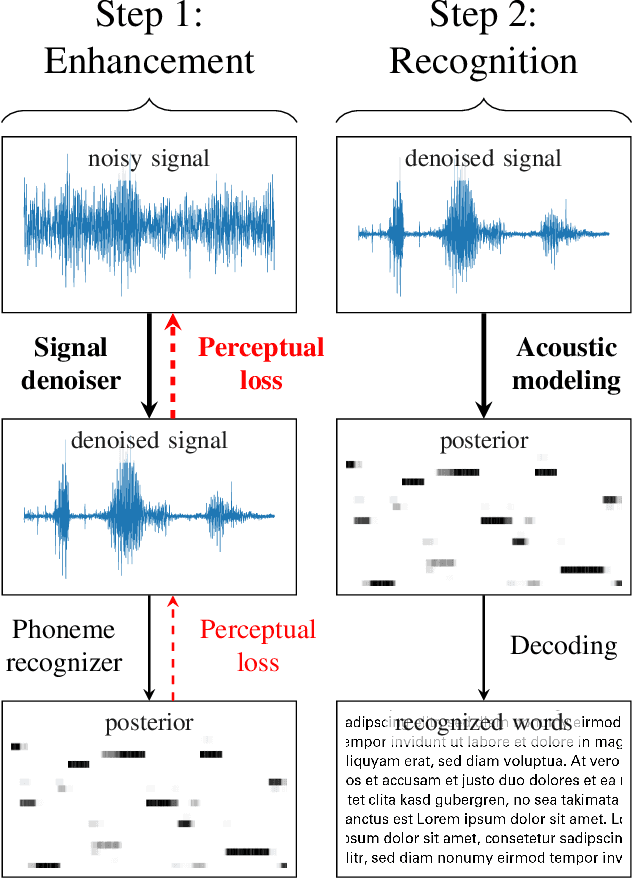
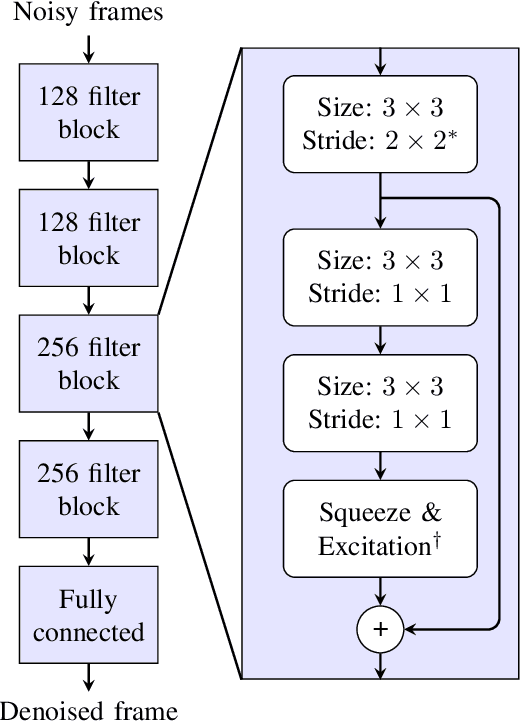
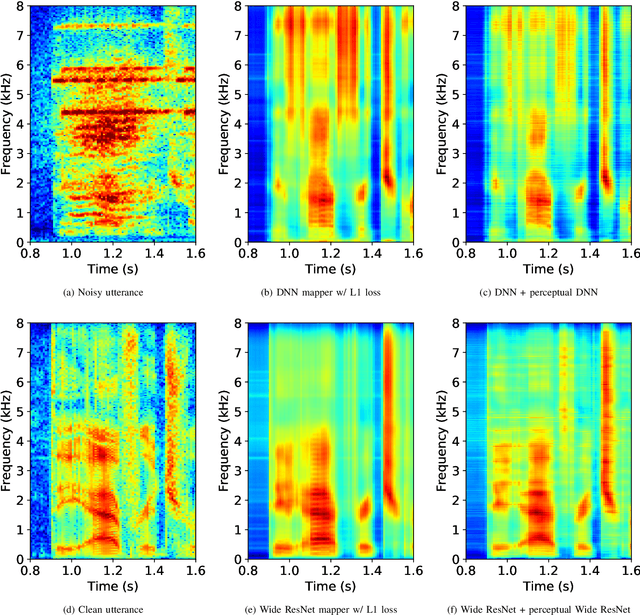
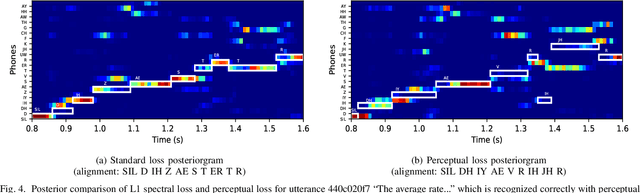
Single-channel speech enhancement approaches do not always improve automatic recognition rates in the presence of noise, because they can introduce distortions unhelpful for recognition. Following a trend towards end-to-end training of sequential neural network models, several research groups have addressed this problem with joint training of front-end enhancement module with back-end recognition module. While this approach ensures enhancement outputs are helpful for recognition, the enhancement model can overfit to the training data, weakening the recognition model in the presence of unseen noise. To address this, we used a pre-trained acoustic model to generate a perceptual loss that makes speech enhancement more aware of the phonetic properties of the signal. This approach keeps some benefits of joint training, while alleviating the overfitting problem. Experiments on Voicebank + DEMAND dataset for enhancement show that this approach achieves a new state of the art for some objective enhancement scores. In combination with distortion-independent training, our approach gets a WER of 2.80\% on the test set, which is more than 20\% relative better recognition performance than joint training, and 14\% relative better than distortion-independent mask training.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
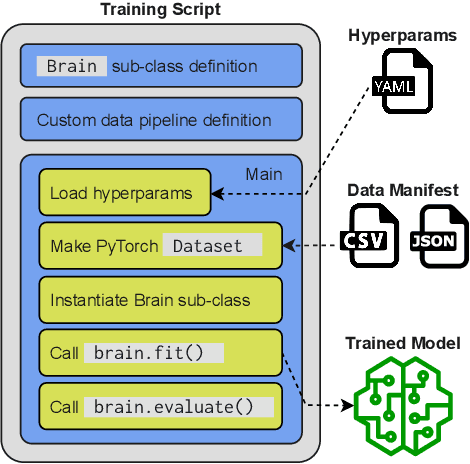

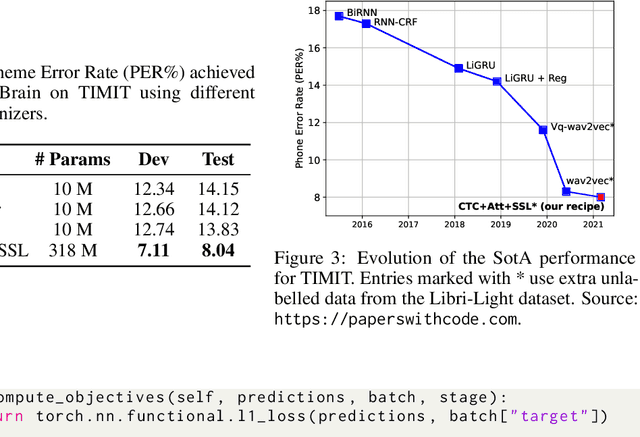
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
Apr 08, 2021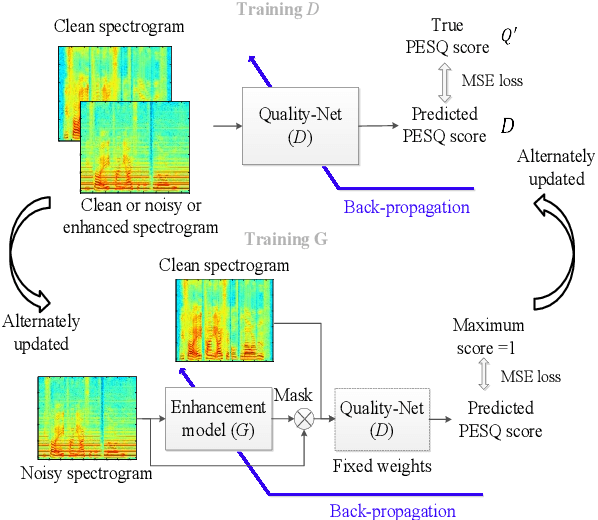
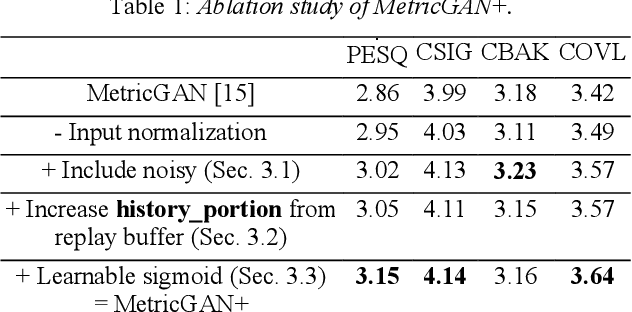
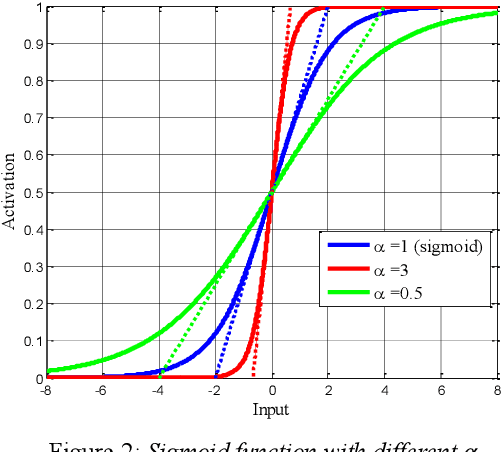

The discrepancy between the cost function used for training a speech enhancement model and human auditory perception usually makes the quality of enhanced speech unsatisfactory. Objective evaluation metrics which consider human perception can hence serve as a bridge to reduce the gap. Our previously proposed MetricGAN was designed to optimize objective metrics by connecting the metric with a discriminator. Because only the scores of the target evaluation functions are needed during training, the metrics can even be non-differentiable. In this study, we propose a MetricGAN+ in which three training techniques incorporating domain-knowledge of speech processing are proposed. With these techniques, experimental results on the VoiceBank-DEMAND dataset show that MetricGAN+ can increase PESQ score by 0.3 compared to the previous MetricGAN and achieve state-of-the-art results (PESQ score = 3.15).
Phonetic Feedback for Speech Enhancement With and Without Parallel Speech Data
Mar 03, 2020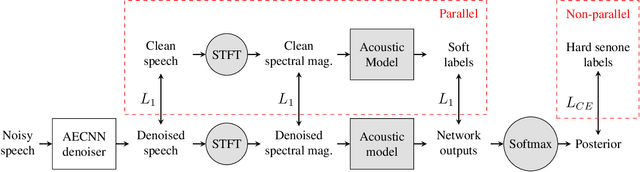
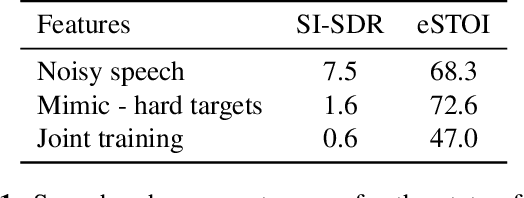
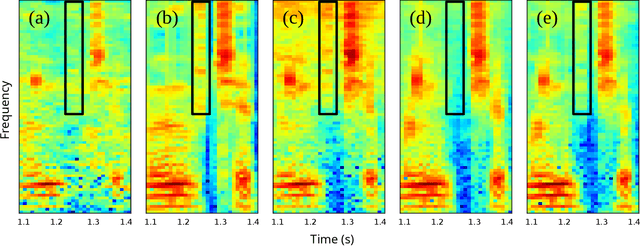
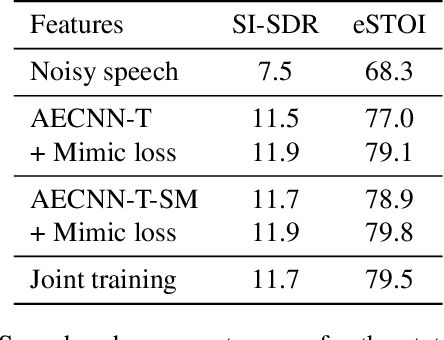
While deep learning systems have gained significant ground in speech enhancement research, these systems have yet to make use of the full potential of deep learning systems to provide high-level feedback. In particular, phonetic feedback is rare in speech enhancement research even though it includes valuable top-down information. We use the technique of mimic loss to provide phonetic feedback to an off-the-shelf enhancement system, and find gains in objective intelligibility scores on CHiME-4 data. This technique takes a frozen acoustic model trained on clean speech to provide valuable feedback to the enhancement model, even in the case where no parallel speech data is available. Our work is one of the first to show intelligibility improvement for neural enhancement systems without parallel speech data, and we show phonetic feedback can improve a state-of-the-art neural enhancement system trained with parallel speech data.
Towards Real-time Mispronunciation Detection in Kids' Speech
Mar 03, 2020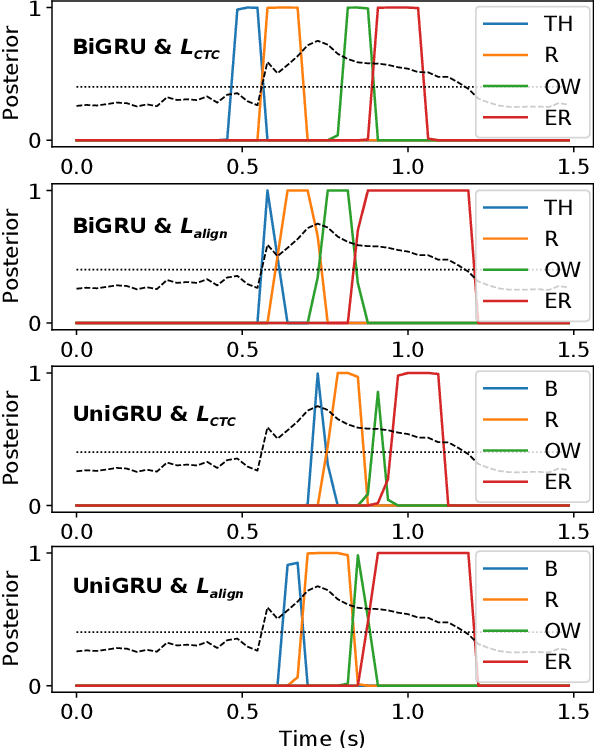
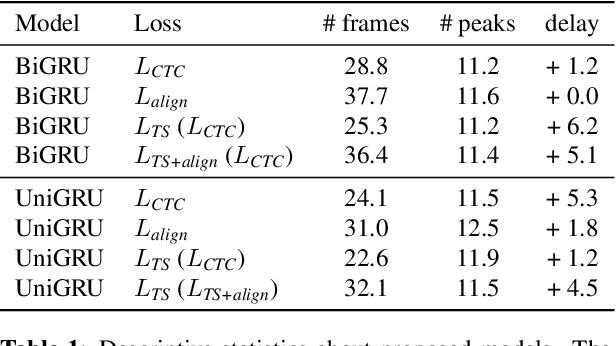
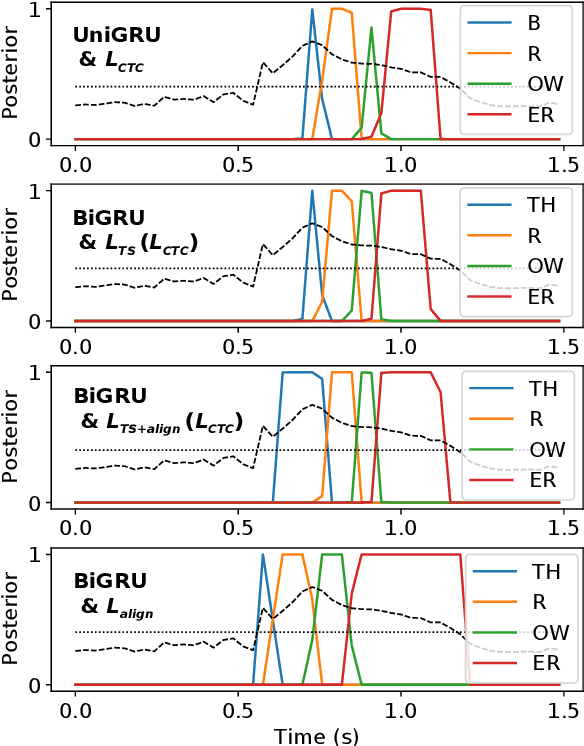
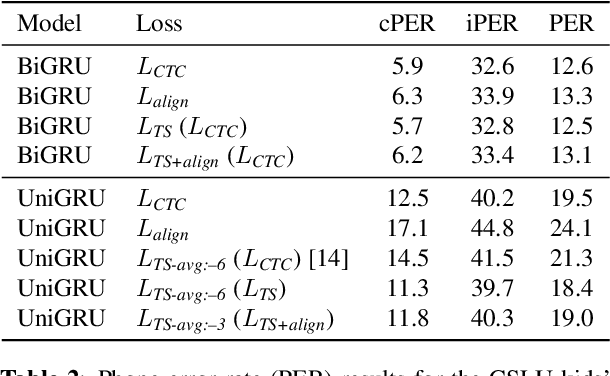
Modern mispronunciation detection and diagnosis systems have seen significant gains in accuracy due to the introduction of deep learning. However, these systems have not been evaluated for the ability to be run in real-time, an important factor in applications that provide rapid feedback. In particular, the state-of-the-art uses bi-directional recurrent networks, where a uni-directional network may be more appropriate. Teacher-student learning is a natural approach to use to improve a uni-directional model, but when using a CTC objective, this is limited by poor alignment of outputs to evidence. We address this limitation by trying two loss terms for improving the alignments of our models. One loss is an "alignment loss" term that encourages outputs only when features do not resemble silence. The other loss term uses a uni-directional model as teacher model to align the bi-directional model. Our proposed model uses these aligned bi-directional models as teacher models. Experiments on the CSLU kids' corpus show that these changes decrease the latency of the outputs, and improve the detection rates, with a trade-off between these goals.
Spectral feature mapping with mimic loss for robust speech recognition
Mar 26, 2018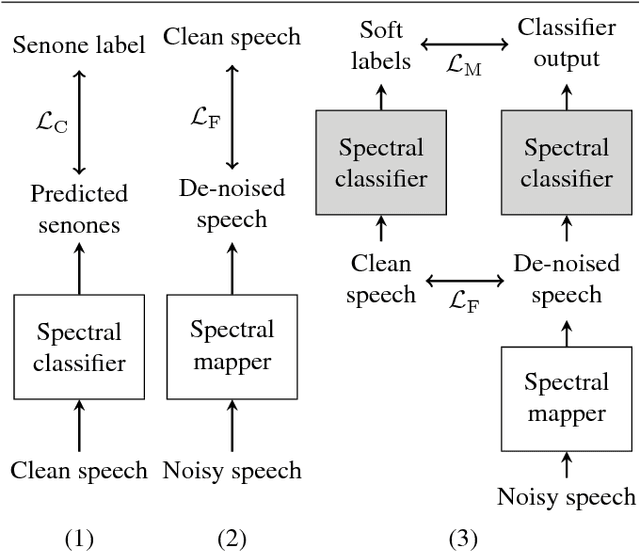
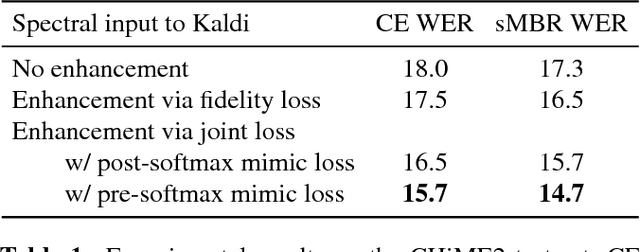
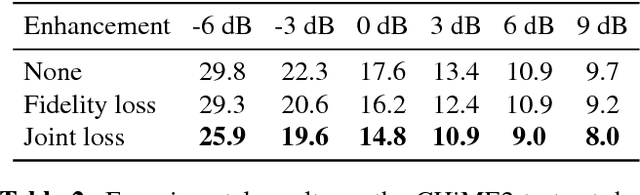
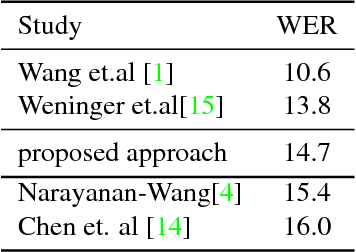
For the task of speech enhancement, local learning objectives are agnostic to phonetic structures helpful for speech recognition. We propose to add a global criterion to ensure de-noised speech is useful for downstream tasks like ASR. We first train a spectral classifier on clean speech to predict senone labels. Then, the spectral classifier is joined with our speech enhancer as a noisy speech recognizer. This model is taught to imitate the output of the spectral classifier alone on clean speech. This \textit{mimic loss} is combined with the traditional local criterion to train the speech enhancer to produce de-noised speech. Feeding the de-noised speech to an off-the-shelf Kaldi training recipe for the CHiME-2 corpus shows significant improvements in WER.