 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-resource Low-footprint Wake-word Detection using Knowledge Distillation
Jul 06, 2022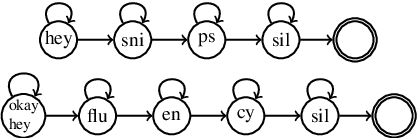
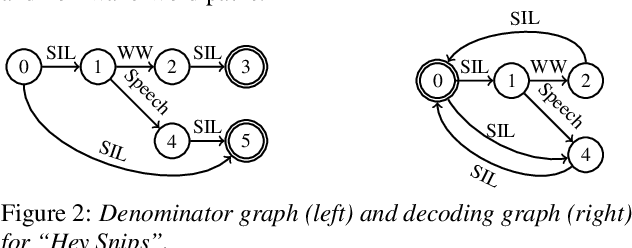
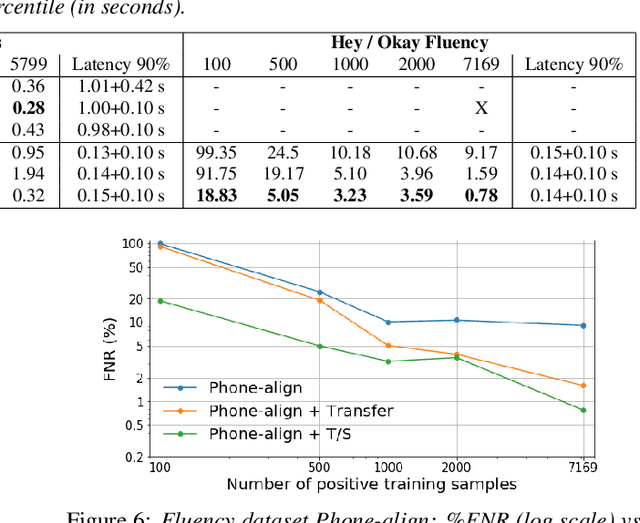
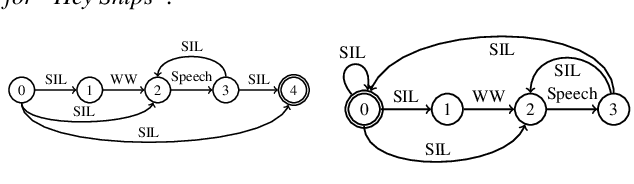
As virtual assistants have become more diverse and specialized, so has the demand for application or brand-specific wake words. However, the wake-word-specific datasets typically used to train wake-word detectors are costly to create. In this paper, we explore two techniques to leverage acoustic modeling data for large-vocabulary speech recognition to improve a purpose-built wake-word detector: transfer learning and knowledge distillation. We also explore how these techniques interact with time-synchronous training targets to improve detection latency. Experiments are presented on the open-source "Hey Snips" dataset and a more challenging in-house far-field dataset. Using phone-synchronous targets and knowledge distillation from a large acoustic model, we are able to improve accuracy across dataset sizes for both datasets while reducing latency.
Perceptual Loss with Recognition Model for Single-Channel Enhancement and Robust ASR
Dec 11, 2021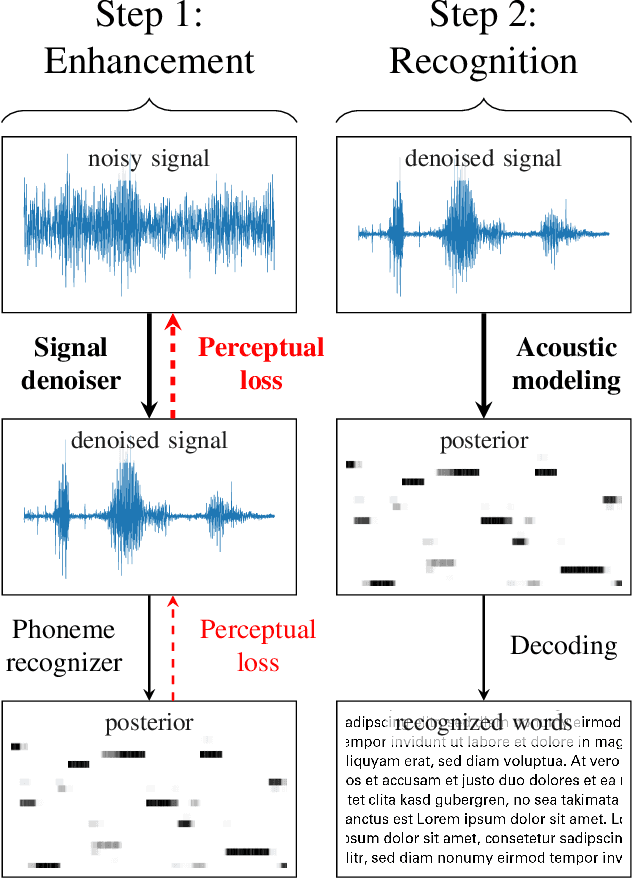
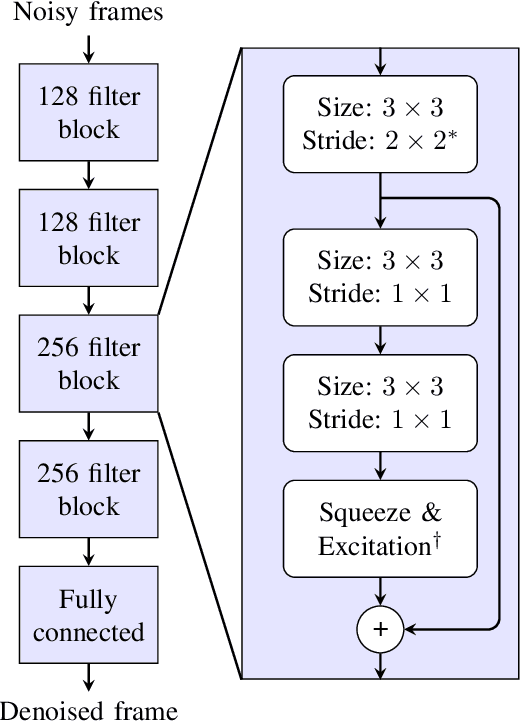
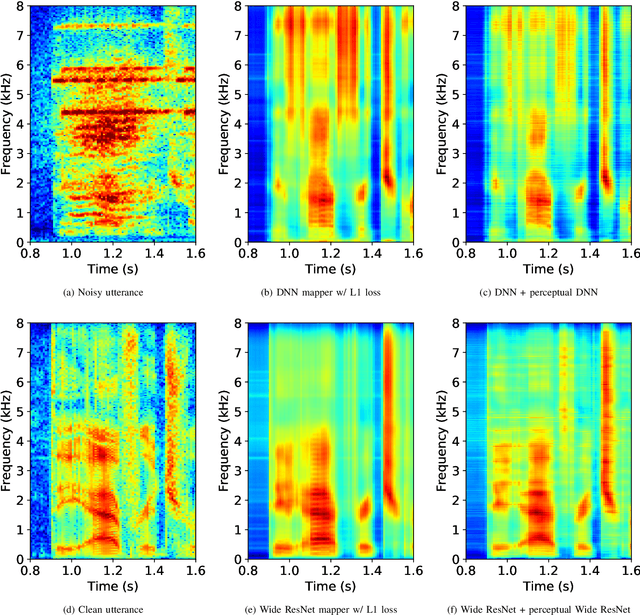
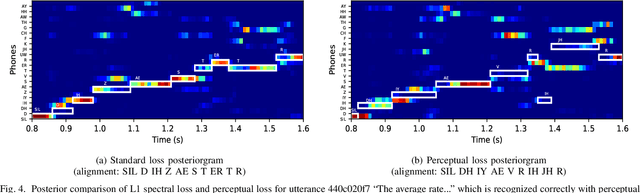
Single-channel speech enhancement approaches do not always improve automatic recognition rates in the presence of noise, because they can introduce distortions unhelpful for recognition. Following a trend towards end-to-end training of sequential neural network models, several research groups have addressed this problem with joint training of front-end enhancement module with back-end recognition module. While this approach ensures enhancement outputs are helpful for recognition, the enhancement model can overfit to the training data, weakening the recognition model in the presence of unseen noise. To address this, we used a pre-trained acoustic model to generate a perceptual loss that makes speech enhancement more aware of the phonetic properties of the signal. This approach keeps some benefits of joint training, while alleviating the overfitting problem. Experiments on Voicebank + DEMAND dataset for enhancement show that this approach achieves a new state of the art for some objective enhancement scores. In combination with distortion-independent training, our approach gets a WER of 2.80\% on the test set, which is more than 20\% relative better recognition performance than joint training, and 14\% relative better than distortion-independent mask training.
Speech Synthesis as Augmentation for Low-Resource ASR
Dec 23, 2020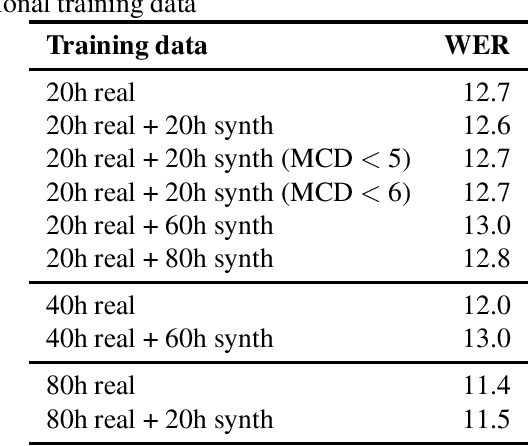

Speech synthesis might hold the key to low-resource speech recognition. Data augmentation techniques have become an essential part of modern speech recognition training. Yet, they are simple, naive, and rarely reflect real-world conditions. Meanwhile, speech synthesis techniques have been rapidly getting closer to the goal of achieving human-like speech. In this paper, we investigate the possibility of using synthesized speech as a form of data augmentation to lower the resources necessary to build a speech recognizer. We experiment with three different kinds of synthesizers: statistical parametric, neural, and adversarial. Our findings are interesting and point to new research directions for the future.
Phonetic Feedback for Speech Enhancement With and Without Parallel Speech Data
Mar 03, 2020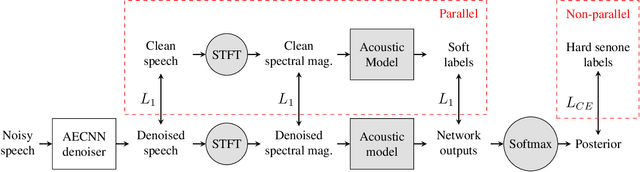
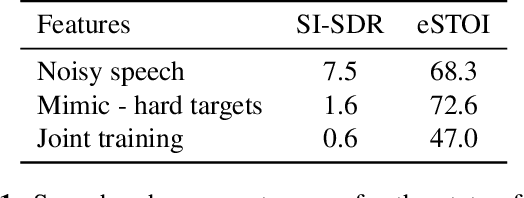
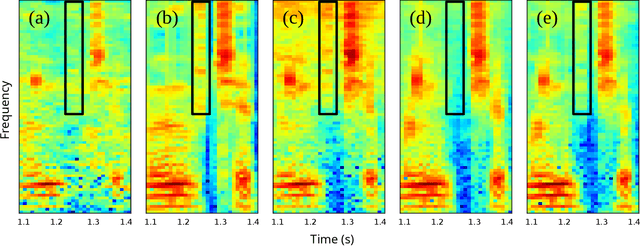
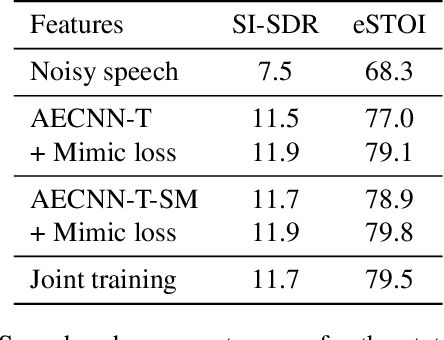
While deep learning systems have gained significant ground in speech enhancement research, these systems have yet to make use of the full potential of deep learning systems to provide high-level feedback. In particular, phonetic feedback is rare in speech enhancement research even though it includes valuable top-down information. We use the technique of mimic loss to provide phonetic feedback to an off-the-shelf enhancement system, and find gains in objective intelligibility scores on CHiME-4 data. This technique takes a frozen acoustic model trained on clean speech to provide valuable feedback to the enhancement model, even in the case where no parallel speech data is available. Our work is one of the first to show intelligibility improvement for neural enhancement systems without parallel speech data, and we show phonetic feedback can improve a state-of-the-art neural enhancement system trained with parallel speech data.
Spectral feature mapping with mimic loss for robust speech recognition
Mar 26, 2018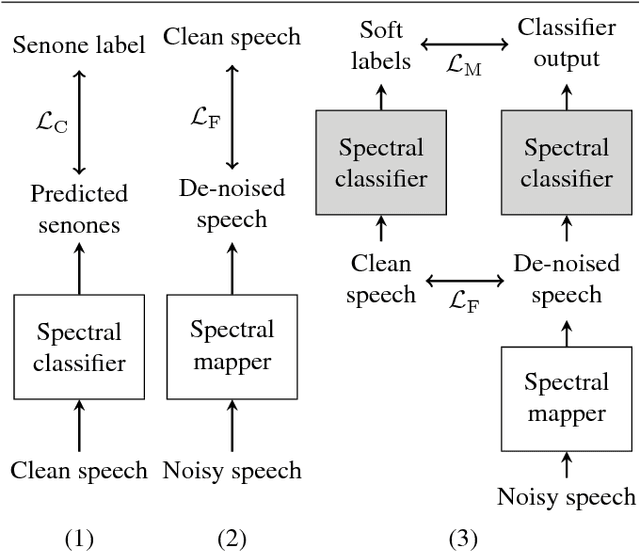
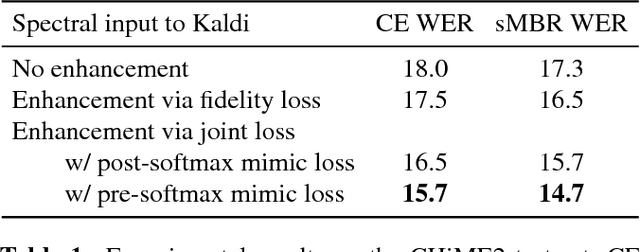
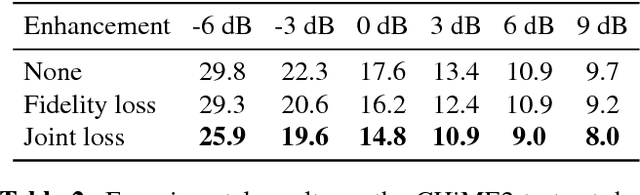
For the task of speech enhancement, local learning objectives are agnostic to phonetic structures helpful for speech recognition. We propose to add a global criterion to ensure de-noised speech is useful for downstream tasks like ASR. We first train a spectral classifier on clean speech to predict senone labels. Then, the spectral classifier is joined with our speech enhancer as a noisy speech recognizer. This model is taught to imitate the output of the spectral classifier alone on clean speech. This \textit{mimic loss} is combined with the traditional local criterion to train the speech enhancer to produce de-noised speech. Feeding the de-noised speech to an off-the-shelf Kaldi training recipe for the CHiME-2 corpus shows significant improvements in WER.