Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Synthesis as Augmentation for Low-Resource ASR
Paper and Code
Dec 23, 2020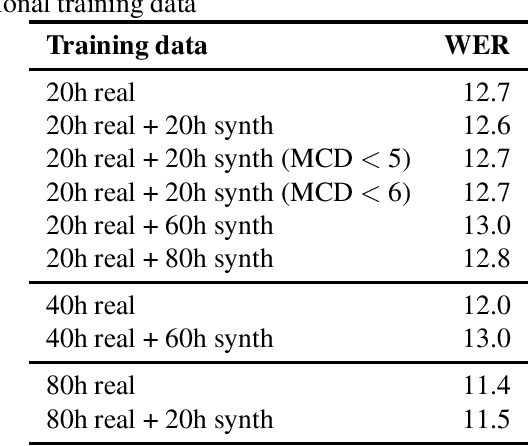

Speech synthesis might hold the key to low-resource speech recognition. Data augmentation techniques have become an essential part of modern speech recognition training. Yet, they are simple, naive, and rarely reflect real-world conditions. Meanwhile, speech synthesis techniques have been rapidly getting closer to the goal of achieving human-like speech. In this paper, we investigate the possibility of using synthesized speech as a form of data augmentation to lower the resources necessary to build a speech recognizer. We experiment with three different kinds of synthesizers: statistical parametric, neural, and adversarial. Our findings are interesting and point to new research directions for the future.
View paper on