 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning
Jan 26, 2026We propose FROST, an attention-aware method for efficient reasoning. Unlike traditional approaches, FROST leverages attention weights to prune uncritical reasoning paths, yielding shorter and more reliable reasoning trajectories. Methodologically, we introduce the concept of reasoning outliers and design an attention-based mechanism to remove them. Theoretically, FROST preserves and enhances the model's reasoning capacity while eliminating outliers at the sentence level. Empirically, we validate FROST on four benchmarks using two strong reasoning models (Phi-4-Reasoning and GPT-OSS-20B), outperforming state-of-the-art methods such as TALE and ThinkLess. Notably, FROST achieves an average 69.68% reduction in token usage and a 26.70% improvement in accuracy over the base model. Furthermore, in evaluations of attention outlier metrics, FROST reduces the maximum infinity norm by 15.97% and the average kurtosis by 91.09% compared to the base model. Code is available at https://github.com/robinzixuan/FROST
A Variational Information Theoretic Approach to Out-of-Distribution Detection
Jun 17, 2025We present a theory for the construction of out-of-distribution (OOD) detection features for neural networks. We introduce random features for OOD through a novel information-theoretic loss functional consisting of two terms, the first based on the KL divergence separates resulting in-distribution (ID) and OOD feature distributions and the second term is the Information Bottleneck, which favors compressed features that retain the OOD information. We formulate a variational procedure to optimize the loss and obtain OOD features. Based on assumptions on OOD distributions, one can recover properties of existing OOD features, i.e., shaping functions. Furthermore, we show that our theory can predict a new shaping function that out-performs existing ones on OOD benchmarks. Our theory provides a general framework for constructing a variety of new features with clear explainability.
Speech Synthesis as Augmentation for Low-Resource ASR
Dec 23, 2020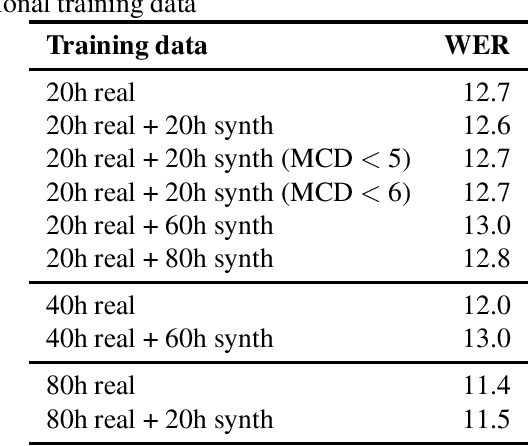

Speech synthesis might hold the key to low-resource speech recognition. Data augmentation techniques have become an essential part of modern speech recognition training. Yet, they are simple, naive, and rarely reflect real-world conditions. Meanwhile, speech synthesis techniques have been rapidly getting closer to the goal of achieving human-like speech. In this paper, we investigate the possibility of using synthesized speech as a form of data augmentation to lower the resources necessary to build a speech recognizer. We experiment with three different kinds of synthesizers: statistical parametric, neural, and adversarial. Our findings are interesting and point to new research directions for the future.
Learning from Noisy Labels with Noise Modeling Network
May 01, 2020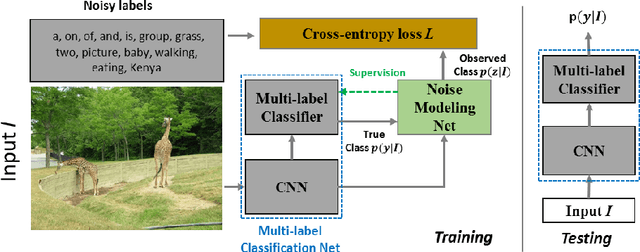
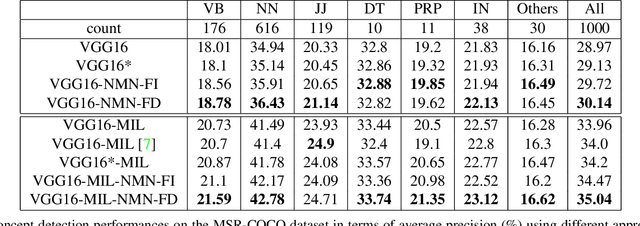
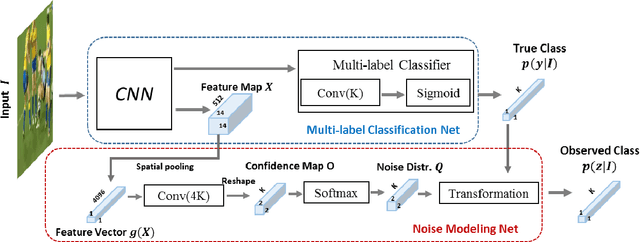
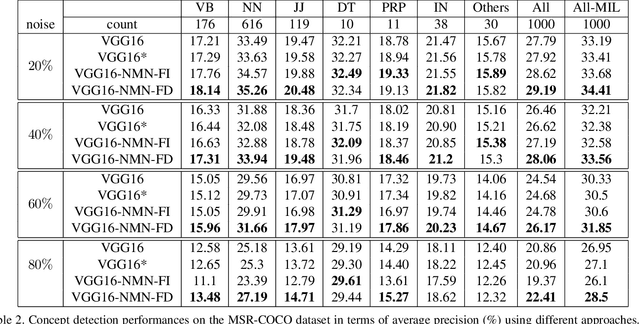
Multi-label image classification has generated significant interest in recent years and the performance of such systems often suffers from the not so infrequent occurrence of incorrect or missing labels in the training data. In this paper, we extend the state-of the-art of training classifiers to jointly deal with both forms of errorful data. We accomplish this by modeling noisy and missing labels in multi-label images with a new Noise Modeling Network (NMN) that follows our convolutional neural network (CNN), integrates with it, forming an end-to-end deep learning system, which can jointly learn the noise distribution and CNN parameters. The NMN learns the distribution of noise patterns directly from the noisy data without the need for any clean training data. The NMN can model label noise that depends only on the true label or is also dependent on the image features. We show that the integrated NMN/CNN learning system consistently improves the classification performance, for different levels of label noise, on the MSR-COCO dataset and MSR-VTT dataset. We also show that noise performance improvements are obtained when multiple instance learning methods are used.
Combining Word Embeddings and N-grams for Unsupervised Document Summarization
Apr 25, 2020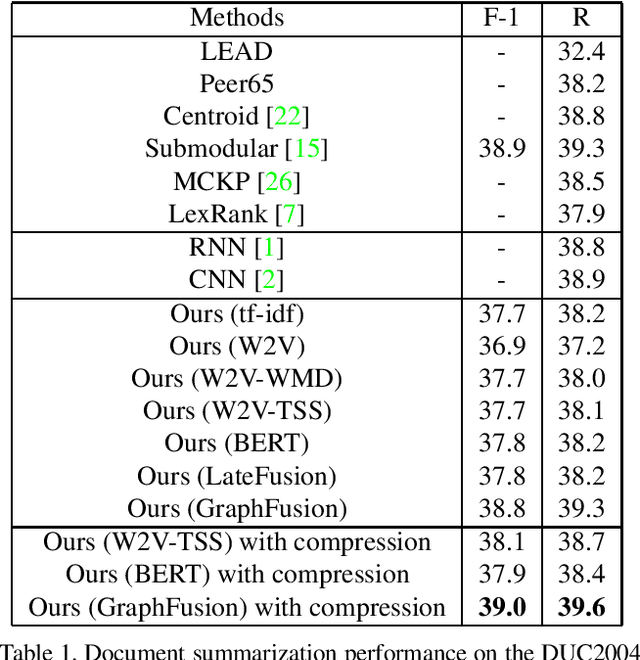
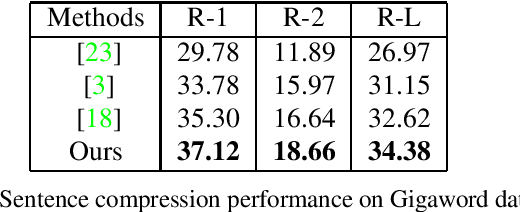
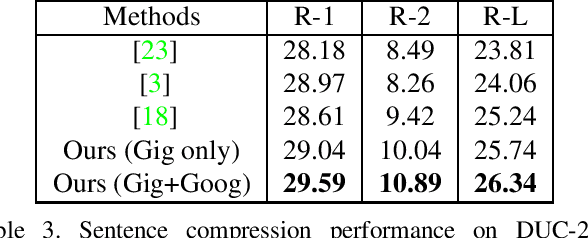
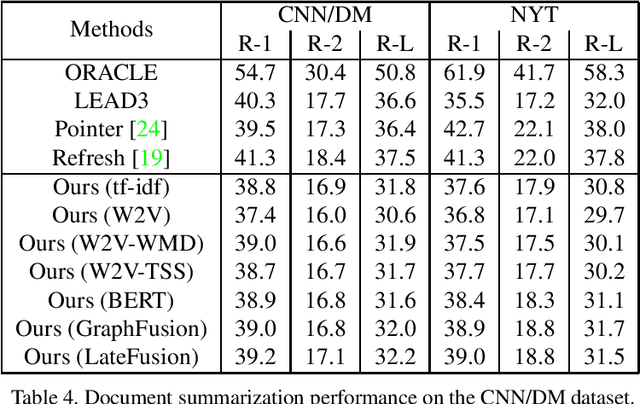
Graph-based extractive document summarization relies on the quality of the sentence similarity graph. Bag-of-words or tf-idf based sentence similarity uses exact word matching, but fails to measure the semantic similarity between individual words or to consider the semantic structure of sentences. In order to improve the similarity measure between sentences, we employ off-the-shelf deep embedding features and tf-idf features, and introduce a new text similarity metric. An improved sentence similarity graph is built and used in a submodular objective function for extractive summarization, which consists of a weighted coverage term and a diversity term. A Transformer based compression model is developed for sentence compression to aid in document summarization. Our summarization approach is extractive and unsupervised. Experiments demonstrate that our approach can outperform the tf-idf based approach and achieve state-of-the-art performance on the DUC04 dataset, and comparable performance to the fully supervised learning methods on the CNN/DM and NYT datasets.
Cross-lingual Information Retrieval with BERT
Apr 24, 2020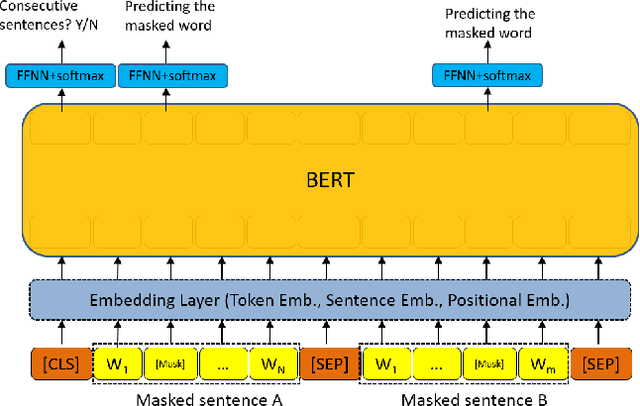

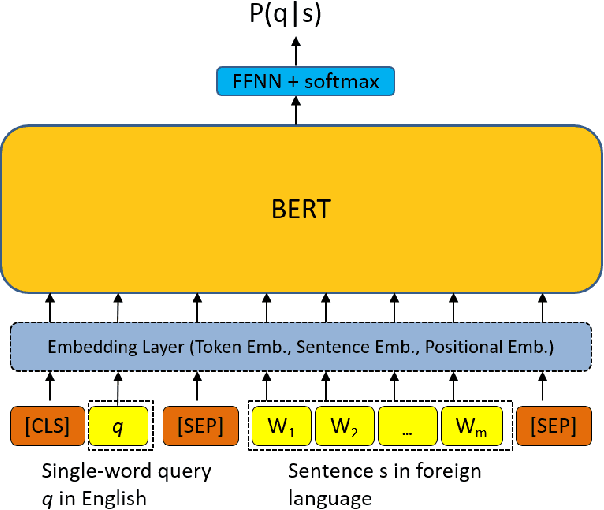
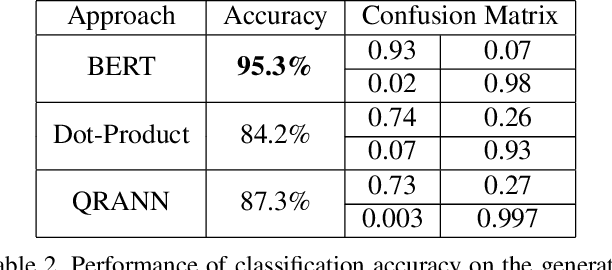
Multiple neural language models have been developed recently, e.g., BERT and XLNet, and achieved impressive results in various NLP tasks including sentence classification, question answering and document ranking. In this paper, we explore the use of the popular bidirectional language model, BERT, to model and learn the relevance between English queries and foreign-language documents in the task of cross-lingual information retrieval. A deep relevance matching model based on BERT is introduced and trained by finetuning a pretrained multilingual BERT model with weak supervision, using home-made CLIR training data derived from parallel corpora. Experimental results of the retrieval of Lithuanian documents against short English queries show that our model is effective and outperforms the competitive baseline approaches.
Towards a New Understanding of the Training of Neural Networks with Mislabeled Training Data
Sep 18, 2019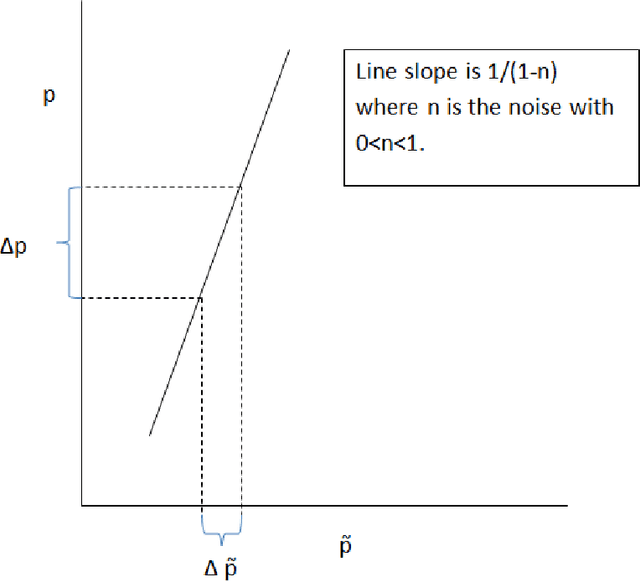
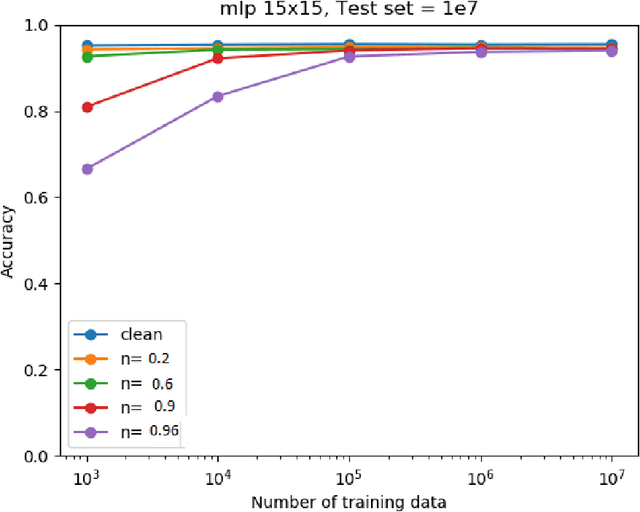
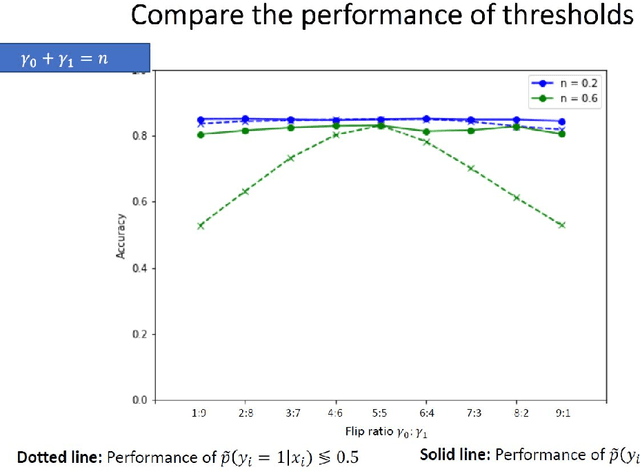
We investigate the problem of machine learning with mislabeled training data. We try to make the effects of mislabeled training better understood through analysis of the basic model and equations that characterize the problem. This includes results about the ability of the noisy model to make the same decisions as the clean model and the effects of noise on model performance. In addition to providing better insights we also are able to show that the Maximum Likelihood (ML) estimate of the parameters of the noisy model determine those of the clean model. This property is obtained through the use of the ML invariance property and leads to an approach to developing a classifier when training has been mislabeled: namely train the classifier on noisy data and adjust the decision threshold based on the noise levels and/or class priors. We show how our approach to mislabeled training works with multi-layered perceptrons (MLPs).
Learning Spatiotemporal Features for Infrared Action Recognition with 3D Convolutional Neural Networks
May 18, 2017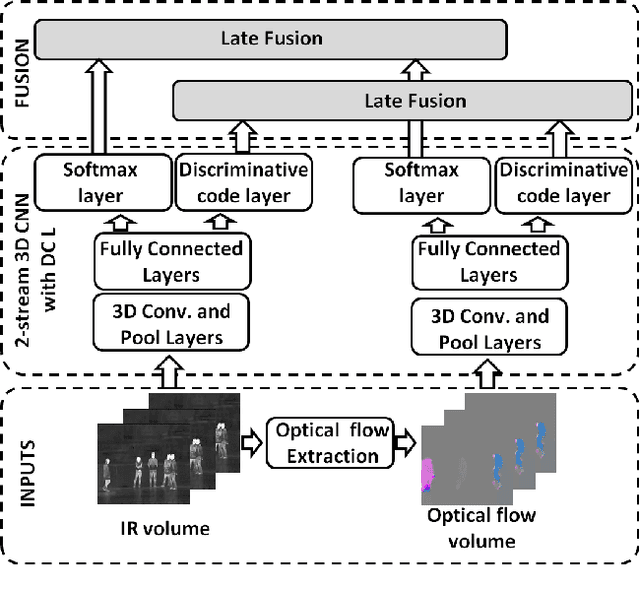
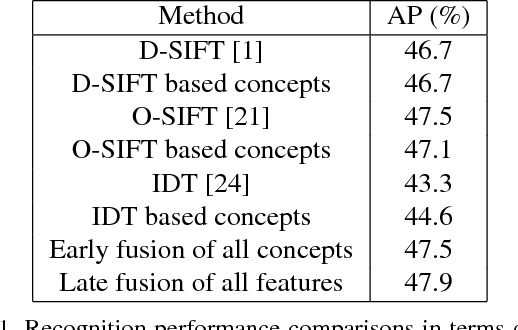
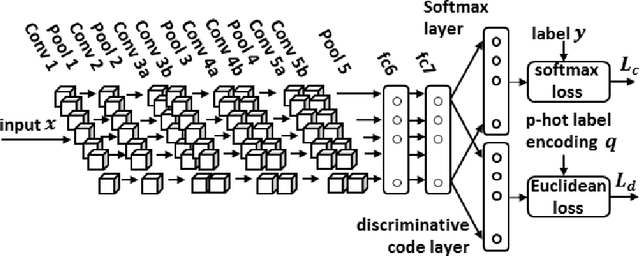
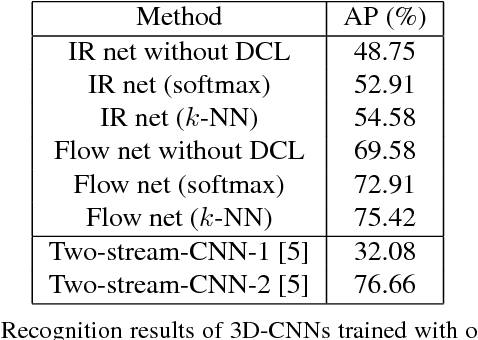
Infrared (IR) imaging has the potential to enable more robust action recognition systems compared to visible spectrum cameras due to lower sensitivity to lighting conditions and appearance variability. While the action recognition task on videos collected from visible spectrum imaging has received much attention, action recognition in IR videos is significantly less explored. Our objective is to exploit imaging data in this modality for the action recognition task. In this work, we propose a novel two-stream 3D convolutional neural network (CNN) architecture by introducing the discriminative code layer and the corresponding discriminative code loss function. The proposed network processes IR image and the IR-based optical flow field sequences. We pretrain the 3D CNN model on the visible spectrum Sports-1M action dataset and finetune it on the Infrared Action Recognition (InfAR) dataset. To our best knowledge, this is the first application of the 3D CNN to action recognition in the IR domain. We conduct an elaborate analysis of different fusion schemes (weighted average, single and double-layer neural nets) applied to different 3D CNN outputs. Experimental results demonstrate that our approach can achieve state-of-the-art average precision (AP) performances on the InfAR dataset: (1) the proposed two-stream 3D CNN achieves the best reported 77.5% AP, and (2) our 3D CNN model applied to the optical flow fields achieves the best reported single stream 75.42% AP.
Learning Discriminative Features via Label Consistent Neural Network
Jun 05, 2016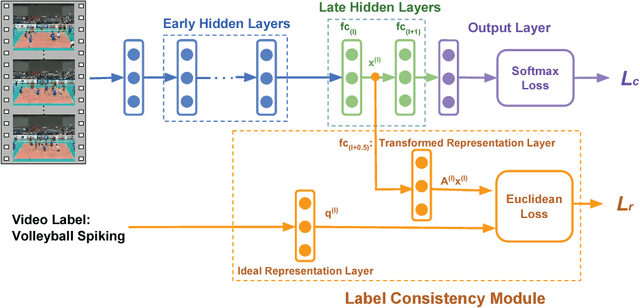
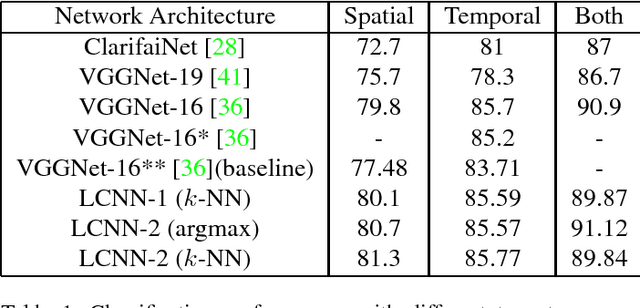

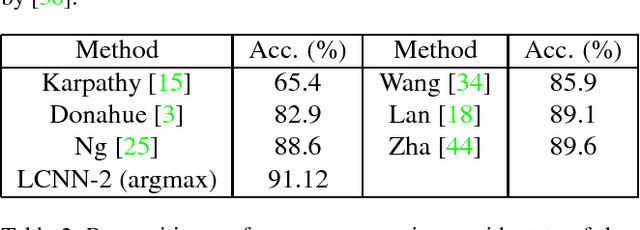
Deep Convolutional Neural Networks (CNN) enforces supervised information only at the output layer, and hidden layers are trained by back propagating the prediction error from the output layer without explicit supervision. We propose a supervised feature learning approach, Label Consistent Neural Network, which enforces direct supervision in late hidden layers. We associate each neuron in a hidden layer with a particular class label and encourage it to be activated for input signals from the same class. More specifically, we introduce a label consistency regularization called "discriminative representation error" loss for late hidden layers and combine it with classification error loss to build our overall objective function. This label consistency constraint alleviates the common problem of gradient vanishing and tends to faster convergence; it also makes the features derived from late hidden layers discriminative enough for classification even using a simple $k$-NN classifier, since input signals from the same class will have very similar representations. Experimental results demonstrate that our approach achieves state-of-the-art performances on several public benchmarks for action and object category recognition.
Generating Discriminative Object Proposals via Submodular Ranking
Feb 11, 2016
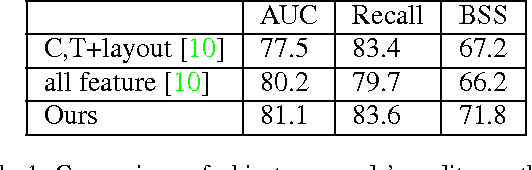
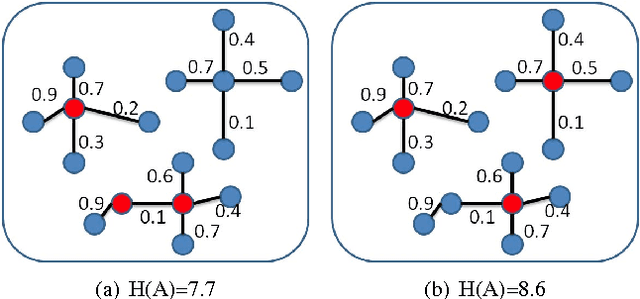
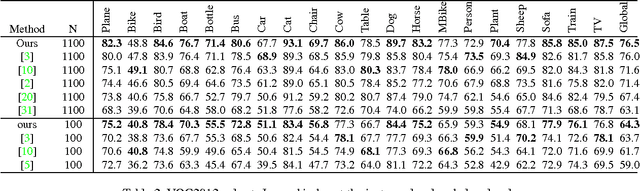
A multi-scale greedy-based object proposal generation approach is presented. Based on the multi-scale nature of objects in images, our approach is built on top of a hierarchical segmentation. We first identify the representative and diverse exemplar clusters within each scale by using a diversity ranking algorithm. Object proposals are obtained by selecting a subset from the multi-scale segment pool via maximizing a submodular objective function, which consists of a weighted coverage term, a single-scale diversity term and a multi-scale reward term. The weighted coverage term forces the selected set of object proposals to be representative and compact; the single-scale diversity term encourages choosing segments from different exemplar clusters so that they will cover as many object patterns as possible; the multi-scale reward term encourages the selected proposals to be discriminative and selected from multiple layers generated by the hierarchical image segmentation. The experimental results on the Berkeley Segmentation Dataset and PASCAL VOC2012 segmentation dataset demonstrate the accuracy and efficiency of our object proposal model. Additionally, we validate our object proposals in simultaneous segmentation and detection and outperform the state-of-art performance.