 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Cauchy Non-negative Matrix Factorization
Jun 02, 2019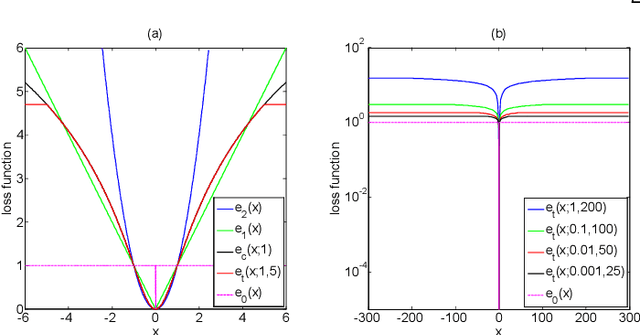



Non-negative matrix factorization (NMF) minimizes the Euclidean distance between the data matrix and its low rank approximation, and it fails when applied to corrupted data because the loss function is sensitive to outliers. In this paper, we propose a Truncated CauchyNMF loss that handle outliers by truncating large errors, and develop a Truncated CauchyNMF to robustly learn the subspace on noisy datasets contaminated by outliers. We theoretically analyze the robustness of Truncated CauchyNMF comparing with the competing models and theoretically prove that Truncated CauchyNMF has a generalization bound which converges at a rate of order $O(\sqrt{{\ln n}/{n}})$, where $n$ is the sample size. We evaluate Truncated CauchyNMF by image clustering on both simulated and real datasets. The experimental results on the datasets containing gross corruptions validate the effectiveness and robustness of Truncated CauchyNMF for learning robust subspaces.
Generating Discriminative Object Proposals via Submodular Ranking
Feb 11, 2016
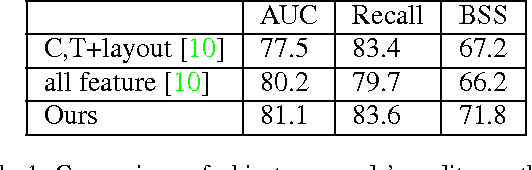
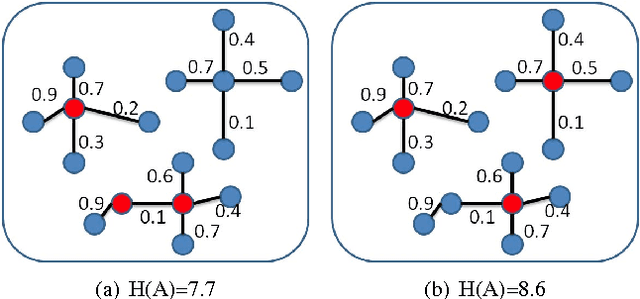
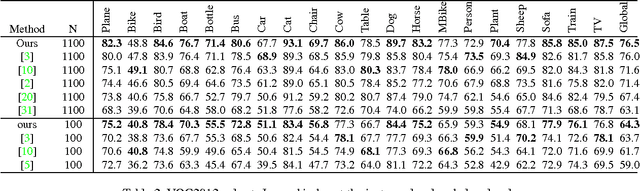
A multi-scale greedy-based object proposal generation approach is presented. Based on the multi-scale nature of objects in images, our approach is built on top of a hierarchical segmentation. We first identify the representative and diverse exemplar clusters within each scale by using a diversity ranking algorithm. Object proposals are obtained by selecting a subset from the multi-scale segment pool via maximizing a submodular objective function, which consists of a weighted coverage term, a single-scale diversity term and a multi-scale reward term. The weighted coverage term forces the selected set of object proposals to be representative and compact; the single-scale diversity term encourages choosing segments from different exemplar clusters so that they will cover as many object patterns as possible; the multi-scale reward term encourages the selected proposals to be discriminative and selected from multiple layers generated by the hierarchical image segmentation. The experimental results on the Berkeley Segmentation Dataset and PASCAL VOC2012 segmentation dataset demonstrate the accuracy and efficiency of our object proposal model. Additionally, we validate our object proposals in simultaneous segmentation and detection and outperform the state-of-art performance.
Parameterizing Region Covariance: An Efficient Way To Apply Sparse Codes On Second Order Statistics
Feb 09, 2016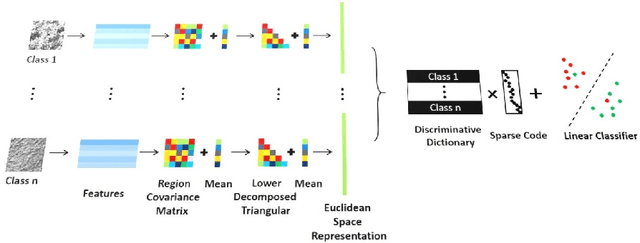
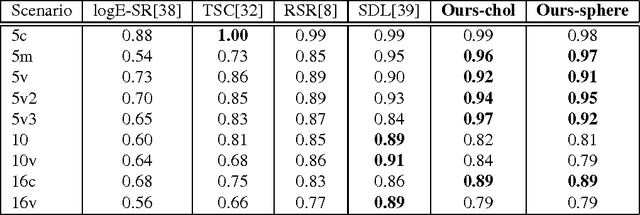

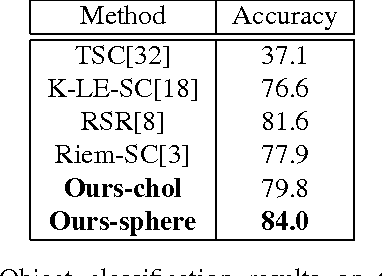
Sparse representations have been successfully applied to signal processing, computer vision and machine learning. Currently there is a trend to learn sparse models directly on structure data, such as region covariance. However, such methods when combined with region covariance often require complex computation. We present an approach to transform a structured sparse model learning problem to a traditional vectorized sparse modeling problem by constructing a Euclidean space representation for region covariance matrices. Our new representation has multiple advantages. Experiments on several vision tasks demonstrate competitive performance with the state-of-the-art methods.
Layer-Specific Adaptive Learning Rates for Deep Networks
Oct 15, 2015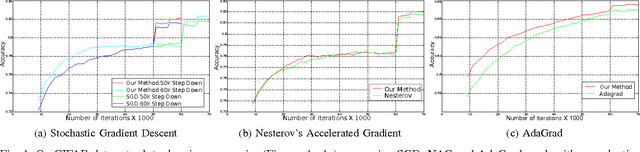



The increasing complexity of deep learning architectures is resulting in training time requiring weeks or even months. This slow training is due in part to vanishing gradients, in which the gradients used by back-propagation are extremely large for weights connecting deep layers (layers near the output layer), and extremely small for shallow layers (near the input layer); this results in slow learning in the shallow layers. Additionally, it has also been shown that in highly non-convex problems, such as deep neural networks, there is a proliferation of high-error low curvature saddle points, which slows down learning dramatically. In this paper, we attempt to overcome the two above problems by proposing an optimization method for training deep neural networks which uses learning rates which are both specific to each layer in the network and adaptive to the curvature of the function, increasing the learning rate at low curvature points. This enables us to speed up learning in the shallow layers of the network and quickly escape high-error low curvature saddle points. We test our method on standard image classification datasets such as MNIST, CIFAR10 and ImageNet, and demonstrate that our method increases accuracy as well as reduces the required training time over standard algorithms.
What makes an Image Iconic? A Fine-Grained Case Study
Aug 19, 2014
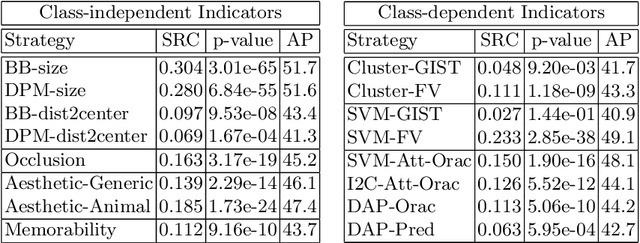

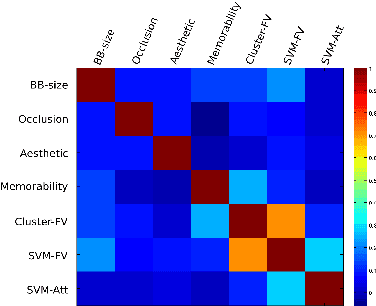
A natural approach to teaching a visual concept, e.g. a bird species, is to show relevant images. However, not all relevant images represent a concept equally well. In other words, they are not necessarily iconic. This observation raises three questions. Is iconicity a subjective property? If not, can we predict iconicity? And what exactly makes an image iconic? We provide answers to these questions through an extensive experimental study on a challenging fine-grained dataset of birds. We first show that iconicity ratings are consistent across individuals, even when they are not domain experts, thus demonstrating that iconicity is not purely subjective. We then consider an exhaustive list of properties that are intuitively related to iconicity and measure their correlation with these iconicity ratings. We combine them to predict iconicity of new unseen images. We also propose a direct iconicity predictor that is discriminatively trained with iconicity ratings. By combining both systems, we get an iconicity prediction that approaches human performance.