 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation
Nov 26, 2024



CLIP is a foundational multimodal model that aligns image and text features into a shared space using contrastive learning on large-scale image-text pairs. Its strength lies in leveraging natural language as a rich supervisory signal. With the rapid progress of large language models (LLMs), we explore their potential to further enhance CLIP's multimodal representation learning. This work introduces a fine-tuning approach that integrates LLMs with the pretrained CLIP visual encoder, leveraging LLMs' advanced text understanding and open-world knowledge to improve CLIP's ability to process long and complex captions. To address the challenge of LLMs' autoregressive nature, we propose a caption-to-caption contrastive learning framework to enhance the discriminative power of their outputs. Our method achieves substantial performance gains on various downstream tasks, demonstrating the effectiveness of combining LLMs with CLIP for enhanced multimodal learning.
LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation
Nov 07, 2024CLIP is one of the most important multimodal foundational models today. What powers CLIP's capabilities? The rich supervision signals provided by natural language, the carrier of human knowledge, shape a powerful cross-modal representation space. However, with the rapid advancements in large language models LLMs like GPT-4 and LLaMA, the boundaries of language comprehension and generation are continually being pushed. This raises an intriguing question: can the capabilities of LLMs be harnessed to further improve multimodal representation learning? The potential benefits of incorporating LLMs into CLIP are clear. LLMs' strong textual understanding can fundamentally improve CLIP's ability to handle image captions, drastically enhancing its ability to process long and complex texts, a well-known limitation of vanilla CLIP. Moreover, LLMs are trained on a vast corpus of text, possessing open-world knowledge. This allows them to expand on caption information during training, increasing the efficiency of the learning process. In this paper, we propose LLM2CLIP, a novel approach that embraces the power of LLMs to unlock CLIP's potential. By fine-tuning the LLM in the caption space with contrastive learning, we extract its textual capabilities into the output embeddings, significantly improving the output layer's textual discriminability. We then design an efficient training process where the fine-tuned LLM acts as a powerful teacher for CLIP's visual encoder. Thanks to the LLM's presence, we can now incorporate longer and more complex captions without being restricted by vanilla CLIP's text encoder's context window and ability limitations. Our experiments demonstrate that this approach brings substantial improvements in cross-modal tasks.
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
Jun 06, 2024Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer \textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by \textbf{2.7} and \textbf{2.9} on average across \textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., \textbf{4.2}, \textbf{11.0}, and \textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, \textbf{3.8} on average compared with LLaVA-1.5-7B.
Rewrite the Stars
Mar 29, 2024Recent studies have drawn attention to the untapped potential of the "star operation" (element-wise multiplication) in network design. While intuitive explanations abound, the foundational rationale behind its application remains largely unexplored. Our study attempts to reveal the star operation's ability to map inputs into high-dimensional, non-linear feature spaces -- akin to kernel tricks -- without widening the network. We further introduce StarNet, a simple yet powerful prototype, demonstrating impressive performance and low latency under compact network structure and efficient budget. Like stars in the sky, the star operation appears unremarkable but holds a vast universe of potential. Our work encourages further exploration across tasks, with codes available at https://github.com/ma-xu/Rewrite-the-Stars.
Efficient Modulation for Vision Networks
Mar 29, 2024In this work, we present efficient modulation, a novel design for efficient vision networks. We revisit the modulation mechanism, which operates input through convolutional context modeling and feature projection layers, and fuses features via element-wise multiplication and an MLP block. We demonstrate that the modulation mechanism is particularly well suited for efficient networks and further tailor the modulation design by proposing the efficient modulation (EfficientMod) block, which is considered the essential building block for our networks. Benefiting from the prominent representational ability of modulation mechanism and the proposed efficient design, our network can accomplish better trade-offs between accuracy and efficiency and set new state-of-the-art performance in the zoo of efficient networks. When integrating EfficientMod with the vanilla self-attention block, we obtain the hybrid architecture which further improves the performance without loss of efficiency. We carry out comprehensive experiments to verify EfficientMod's performance. With fewer parameters, our EfficientMod-s performs 0.6 top-1 accuracy better than EfficientFormerV2-s2 and is 25% faster on GPU, and 2.9 better than MobileViTv2-1.0 at the same GPU latency. Additionally, our method presents a notable improvement in downstream tasks, outperforming EfficientFormerV2-s by 3.6 mIoU on the ADE20K benchmark. Code and checkpoints are available at https://github.com/ma-xu/EfficientMod.
Real-Time Image Segmentation via Hybrid Convolutional-Transformer Architecture Search
Mar 15, 2024



Image segmentation is one of the most fundamental problems in computer vision and has drawn a lot of attentions due to its vast applications in image understanding and autonomous driving. However, designing effective and efficient segmentation neural architectures is a labor-intensive process that may require lots of trials by human experts. In this paper, we address the challenge of integrating multi-head self-attention into high resolution representation CNNs efficiently, by leveraging architecture search. Manually replacing convolution layers with multi-head self-attention is non-trivial due to the costly overhead in memory to maintain high resolution. By contrast, we develop a multi-target multi-branch supernet method, which not only fully utilizes the advantages of high-resolution features, but also finds the proper location for placing multi-head self-attention module. Our search algorithm is optimized towards multiple objective s (e.g., latency and mIoU) and capable of finding architectures on Pareto frontier with arbitrary number of branches in a single search. We further present a series of model via Hybrid Convolutional-Transformer Architecture Search (HyCTAS) method that searched for the best hybrid combination of light-weight convolution layers and memory-efficient self-attention layers between branches from different resolutions and fuse to high resolution for both efficiency and effectiveness. Extensive experiments demonstrate that HyCTAS outperforms previous methods on semantic segmentation task. Code and models are available at \url{https://github.com/MarvinYu1995/HyCTAS}.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023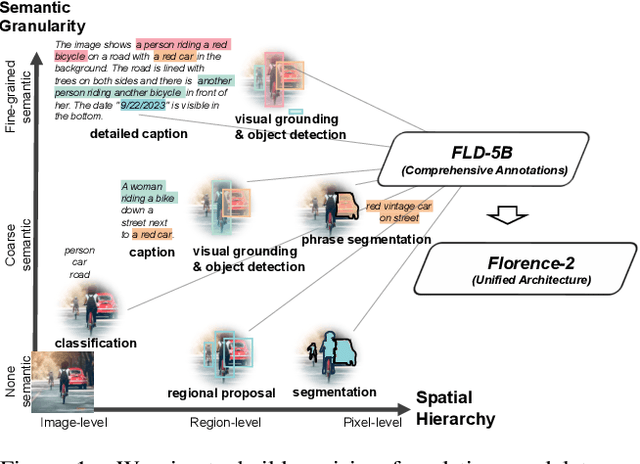
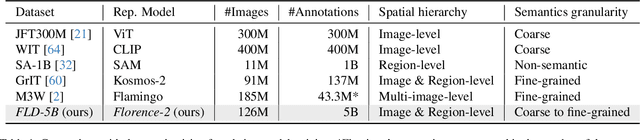
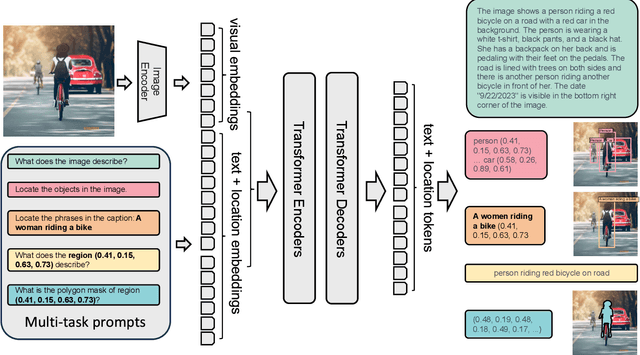
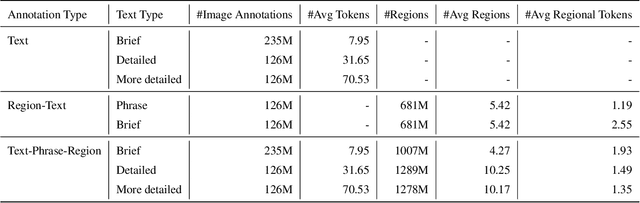
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
On the Hidden Waves of Image
Oct 19, 2023



In this paper, we introduce an intriguing phenomenon-the successful reconstruction of images using a set of one-way wave equations with hidden and learnable speeds. Each individual image corresponds to a solution with a unique initial condition, which can be computed from the original image using a visual encoder (e.g., a convolutional neural network). Furthermore, the solution for each image exhibits two noteworthy mathematical properties: (a) it can be decomposed into a collection of special solutions of the same one-way wave equations that are first-order autoregressive, with shared coefficient matrices for autoregression, and (b) the product of these coefficient matrices forms a diagonal matrix with the speeds of the wave equations as its diagonal elements. We term this phenomenon hidden waves, as it reveals that, although the speeds of the set of wave equations and autoregressive coefficient matrices are latent, they are both learnable and shared across images. This represents a mathematical invariance across images, providing a new mathematical perspective to understand images.
Learning from Rich Semantics and Coarse Locations for Long-tailed Object Detection
Oct 18, 2023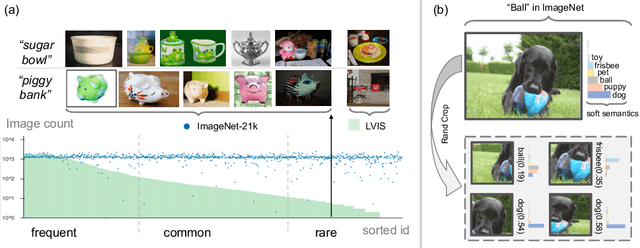
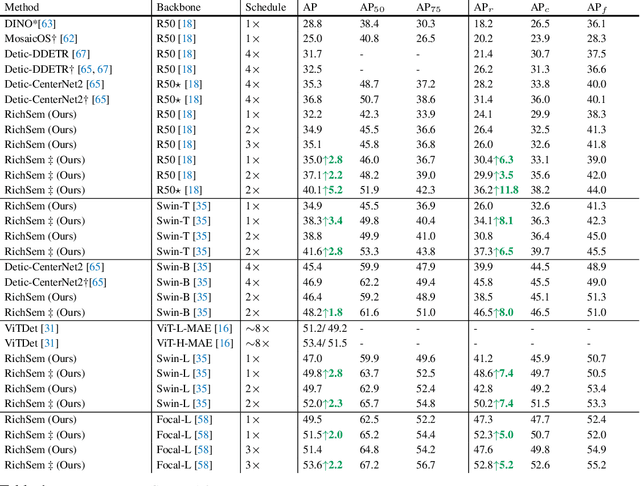
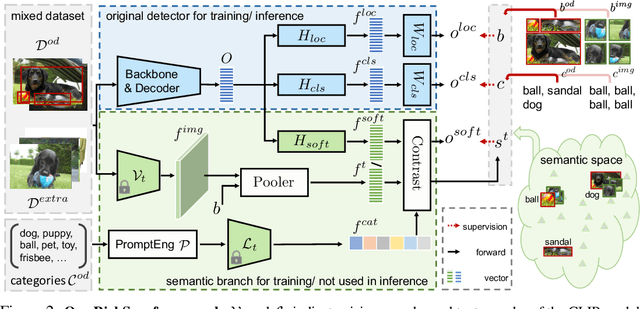
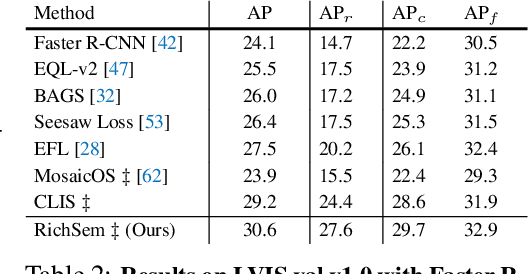
Long-tailed object detection (LTOD) aims to handle the extreme data imbalance in real-world datasets, where many tail classes have scarce instances. One popular strategy is to explore extra data with image-level labels, yet it produces limited results due to (1) semantic ambiguity -- an image-level label only captures a salient part of the image, ignoring the remaining rich semantics within the image; and (2) location sensitivity -- the label highly depends on the locations and crops of the original image, which may change after data transformations like random cropping. To remedy this, we propose RichSem, a simple but effective method, which is robust to learn rich semantics from coarse locations without the need of accurate bounding boxes. RichSem leverages rich semantics from images, which are then served as additional soft supervision for training detectors. Specifically, we add a semantic branch to our detector to learn these soft semantics and enhance feature representations for long-tailed object detection. The semantic branch is only used for training and is removed during inference. RichSem achieves consistent improvements on both overall and rare-category of LVIS under different backbones and detectors. Our method achieves state-of-the-art performance without requiring complex training and testing procedures. Moreover, we show the effectiveness of our method on other long-tailed datasets with additional experiments. Code is available at \url{https://github.com/MengLcool/RichSem}.