 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024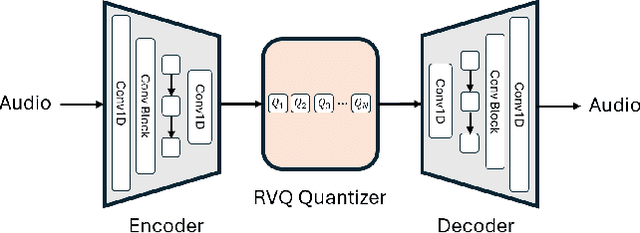

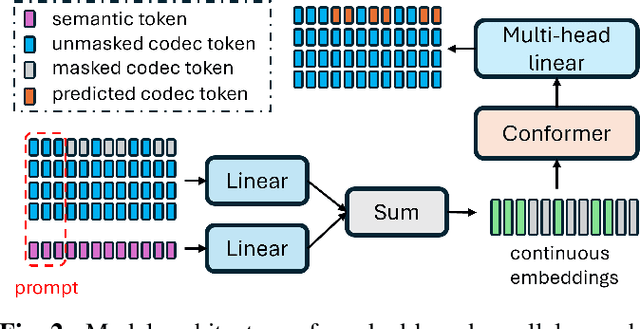
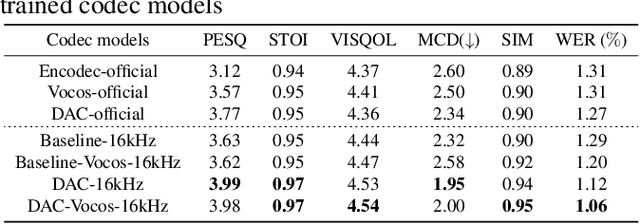
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Apr 10, 2024



Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Nov 10, 2023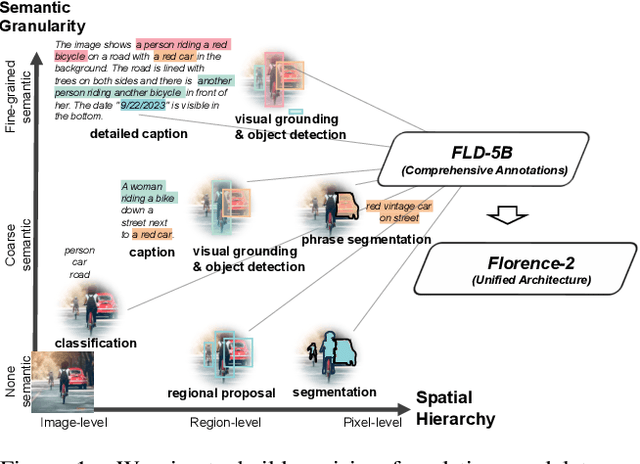
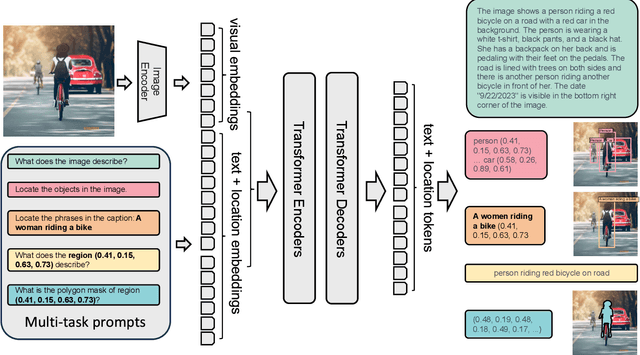
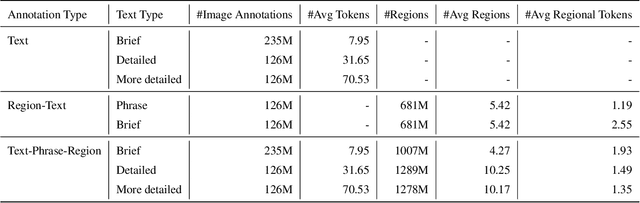
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchy and semantic granularity. Florence-2 was designed to take text-prompt as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B that consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement. We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
Diffusion Conditional Expectation Model for Efficient and Robust Target Speech Extraction
Sep 25, 2023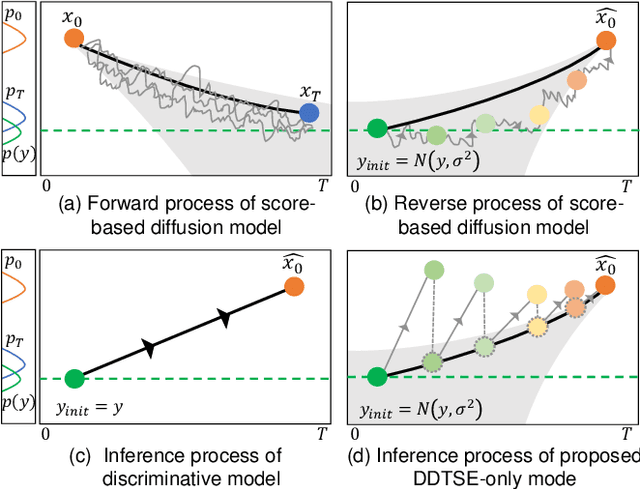
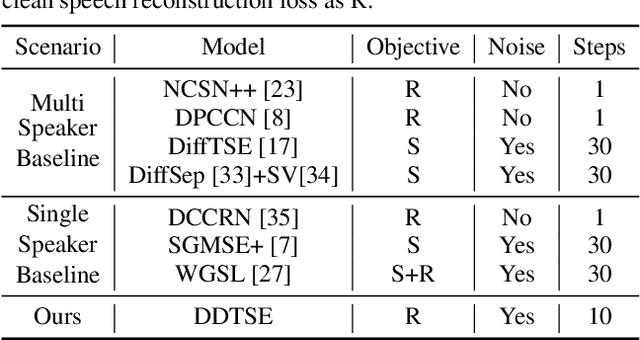
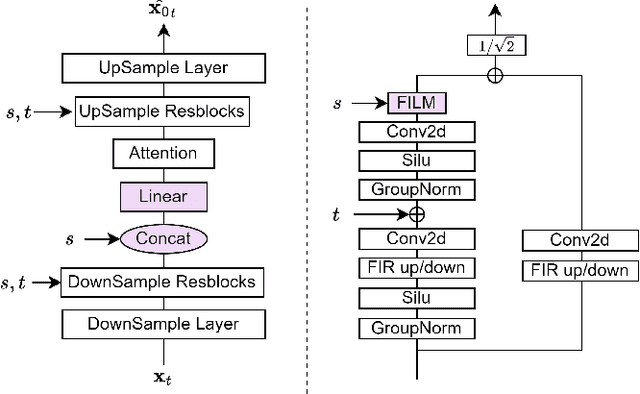
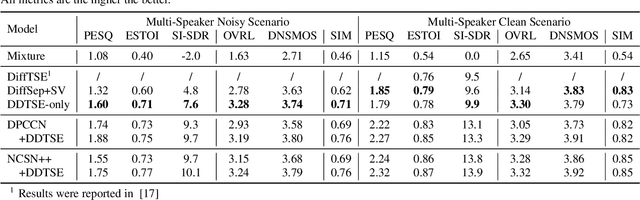
Target Speech Extraction (TSE) is a crucial task in speech processing that focuses on isolating the clean speech of a specific speaker from complex mixtures. While discriminative methods are commonly used for TSE, they can introduce distortion in terms of speech perception quality. On the other hand, generative approaches, particularly diffusion-based methods, can enhance speech quality perceptually but suffer from slower inference speed. We propose an efficient generative approach named Diffusion Conditional Expectation Model (DCEM) for TSE. It can handle multi- and single-speaker scenarios in both noisy and clean conditions. Additionally, we introduce Regenerate-DCEM (R-DCEM) that can regenerate and optimize speech quality based on pre-processed speech from a discriminative model. Our method outperforms conventional methods in terms of both intrusive and non-intrusive metrics and demonstrates notable strengths in inference efficiency and robustness to unseen tasks. Audio examples are available online (https://vivian556123.github.io/dcem).
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023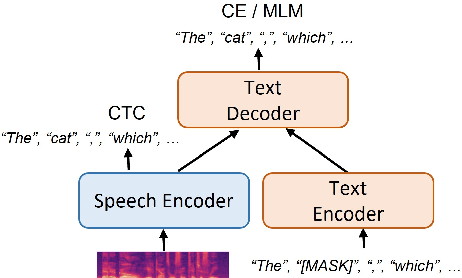
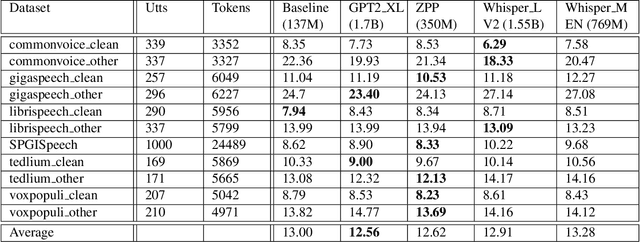
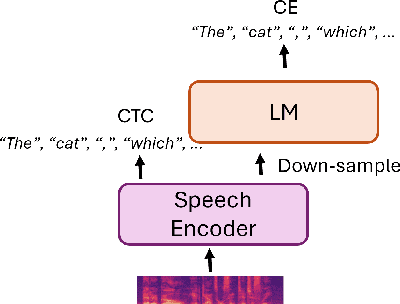
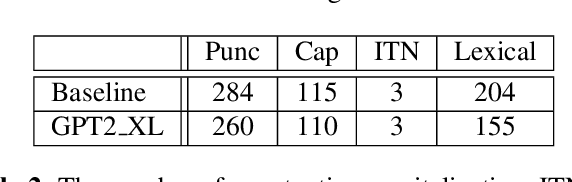
Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023



State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.
ComSL: A Composite Speech-Language Model for End-to-End Speech-to-Text Translation
May 24, 2023



Joint speech-language training is challenging due to the large demand for training data and GPU consumption, as well as the modality gap between speech and language. We present ComSL, a speech-language model built atop a composite architecture of public pretrained speech-only and language-only models and optimized data-efficiently for spoken language tasks. Particularly, we propose to incorporate cross-modality learning into transfer learning and conduct them simultaneously for downstream tasks in a multi-task learning manner. Our approach has demonstrated effectiveness in end-to-end speech-to-text translation tasks, achieving a new state-of-the-art average BLEU score of 31.5 on the multilingual speech to English text translation task for 21 languages, as measured on the public CoVoST2 evaluation set.
i-Code Studio: A Configurable and Composable Framework for Integrative AI
May 23, 2023



Artificial General Intelligence (AGI) requires comprehensive understanding and generation capabilities for a variety of tasks spanning different modalities and functionalities. Integrative AI is one important direction to approach AGI, through combining multiple models to tackle complex multimodal tasks. However, there is a lack of a flexible and composable platform to facilitate efficient and effective model composition and coordination. In this paper, we propose the i-Code Studio, a configurable and composable framework for Integrative AI. The i-Code Studio orchestrates multiple pre-trained models in a finetuning-free fashion to conduct complex multimodal tasks. Instead of simple model composition, the i-Code Studio provides an integrative, flexible, and composable setting for developers to quickly and easily compose cutting-edge services and technologies tailored to their specific requirements. The i-Code Studio achieves impressive results on a variety of zero-shot multimodal tasks, such as video-to-text retrieval, speech-to-speech translation, and visual question answering. We also demonstrate how to quickly build a multimodal agent based on the i-Code Studio that can communicate and personalize for users.