 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing GUI Agent for Electronic Design Automation
Dec 12, 2025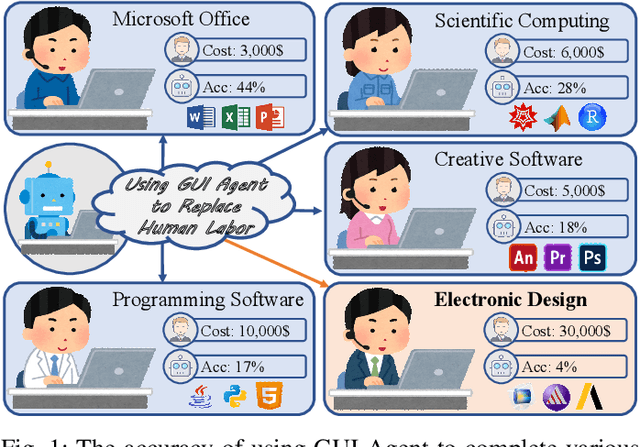
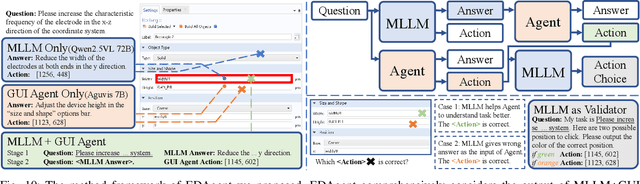
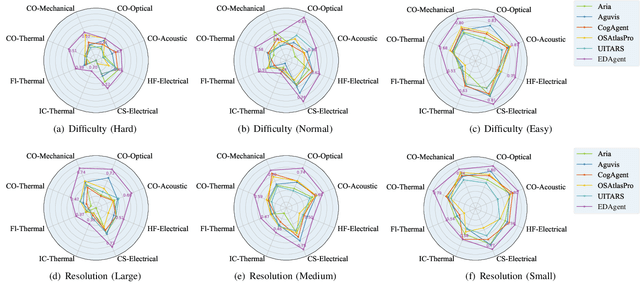
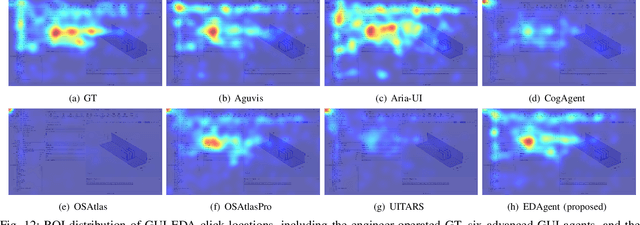
Graphical User Interface (GUI) agents adopt an end-to-end paradigm that maps a screenshot to an action sequence, thereby automating repetitive tasks in virtual environments. However, existing GUI agents are evaluated almost exclusively on commodity software such as Microsoft Word and Excel. Professional Computer-Aided Design (CAD) suites promise an order-of-magnitude higher economic return, yet remain the weakest performance domain for existing agents and are still far from replacing expert Electronic-Design-Automation (EDA) engineers. We therefore present the first systematic study that deploys GUI agents for EDA workflows. Our contributions are: (1) a large-scale dataset named GUI-EDA, including 5 CAD tools and 5 physical domains, comprising 2,000+ high-quality screenshot-answer-action pairs recorded by EDA scientists and engineers during real-world component design; (2) a comprehensive benchmark that evaluates 30+ mainstream GUI agents, demonstrating that EDA tasks constitute a major, unsolved challenge; and (3) an EDA-specialized metric named EDAgent, equipped with a reflection mechanism that achieves reliable performance on industrial CAD software and, for the first time, outperforms Ph.D. students majored in Electrical Engineering. This work extends GUI agents from generic office automation to specialized, high-value engineering domains and offers a new avenue for advancing EDA productivity. The dataset will be released at: https://github.com/aiben-ch/GUI-EDA.
DeepRTE: Pre-trained Attention-based Neural Network for Radiative Tranfer
May 29, 2025In this study, we propose a novel neural network approach, termed DeepRTE, to address the steady-state Radiative Transfer Equation (RTE). The RTE is a differential-integral equation that governs the propagation of radiation through a participating medium, with applications spanning diverse domains such as neutron transport, atmospheric radiative transfer, heat transfer, and optical imaging. Our proposed DeepRTE framework leverages pre-trained attention-based neural networks to solve the RTE with high accuracy and computational efficiency. The efficacy of the proposed approach is substantiated through comprehensive numerical experiments.
Flow Matching based Sequential Recommender Model
May 22, 2025Generative models, particularly diffusion model, have emerged as powerful tools for sequential recommendation. However, accurately modeling user preferences remains challenging due to the noise perturbations inherent in the forward and reverse processes of diffusion-based methods. Towards this end, this study introduces FMRec, a Flow Matching based model that employs a straight flow trajectory and a modified loss tailored for the recommendation task. Additionally, from the diffusion-model perspective, we integrate a reconstruction loss to improve robustness against noise perturbations, thereby retaining user preferences during the forward process. In the reverse process, we employ a deterministic reverse sampler, specifically an ODE-based updating function, to eliminate unnecessary randomness, thereby ensuring that the generated recommendations closely align with user needs. Extensive evaluations on four benchmark datasets reveal that FMRec achieves an average improvement of 6.53% over state-of-the-art methods. The replication code is available at https://github.com/FengLiu-1/FMRec.
RLCAD: Reinforcement Learning Training Gym for Revolution Involved CAD Command Sequence Generation
Mar 24, 2025A CAD command sequence is a typical parametric design paradigm in 3D CAD systems where a model is constructed by overlaying 2D sketches with operations such as extrusion, revolution, and Boolean operations. Although there is growing academic interest in the automatic generation of command sequences, existing methods and datasets only support operations such as 2D sketching, extrusion,and Boolean operations. This limitation makes it challenging to represent more complex geometries. In this paper, we present a reinforcement learning (RL) training environment (gym) built on a CAD geometric engine. Given an input boundary representation (B-Rep) geometry, the policy network in the RL algorithm generates an action. This action, along with previously generated actions, is processed within the gym to produce the corresponding CAD geometry, which is then fed back into the policy network. The rewards, determined by the difference between the generated and target geometries within the gym, are used to update the RL network. Our method supports operations beyond sketches, Boolean, and extrusion, including revolution operations. With this training gym, we achieve state-of-the-art (SOTA) quality in generating command sequences from B-Rep geometries. In addition, our method can significantly improve the efficiency of command sequence generation by a factor of 39X compared with the previous training gym.
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Nov 06, 2024Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
Efficient Sparse Attention needs Adaptive Token Release
Jul 02, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide array of text-centric tasks. However, their `large' scale introduces significant computational and storage challenges, particularly in managing the key-value states of the transformer, which limits their wider applicability. Therefore, we propose to adaptively release resources from caches and rebuild the necessary key-value states. Particularly, we accomplish this by a lightweight controller module to approximate an ideal top-$K$ sparse attention. This module retains the tokens with the highest top-$K$ attention weights and simultaneously rebuilds the discarded but necessary tokens, which may become essential for future decoding. Comprehensive experiments in natural language generation and modeling reveal that our method is not only competitive with full attention in terms of performance but also achieves a significant throughput improvement of up to 221.8%. The code for replication is available on the https://github.com/WHUIR/ADORE.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024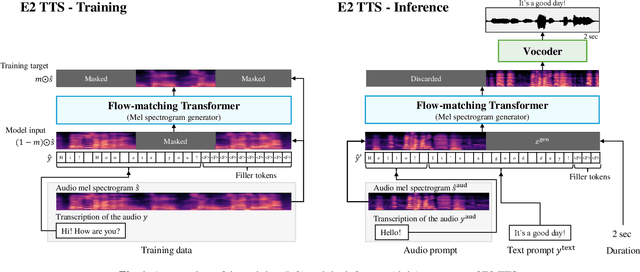
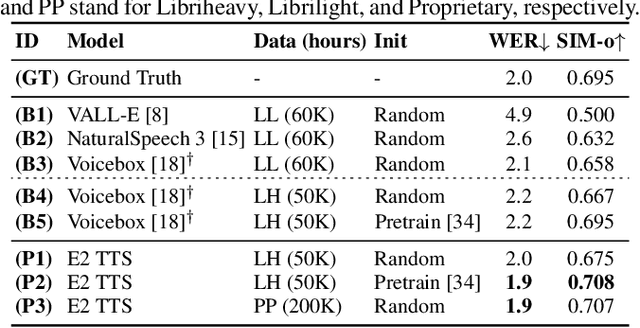
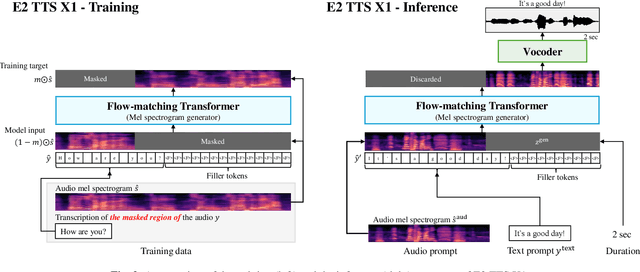
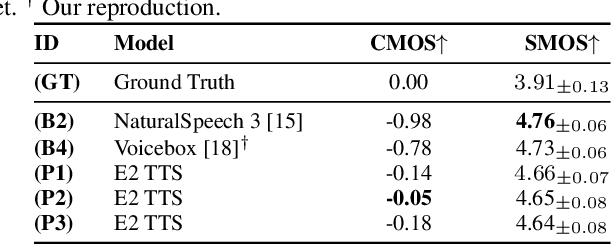
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Jun 09, 2024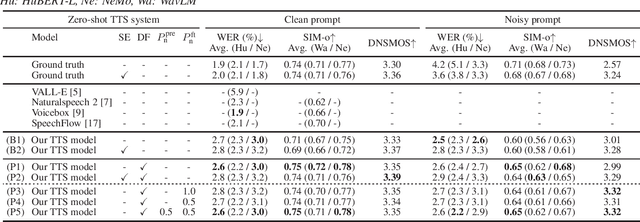
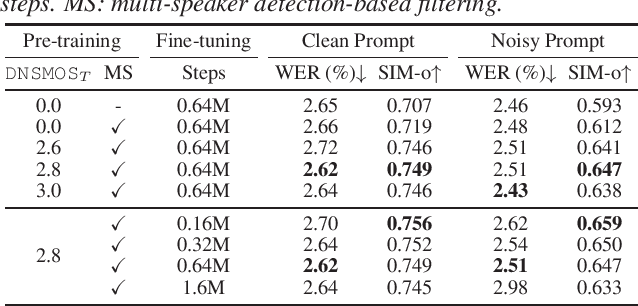
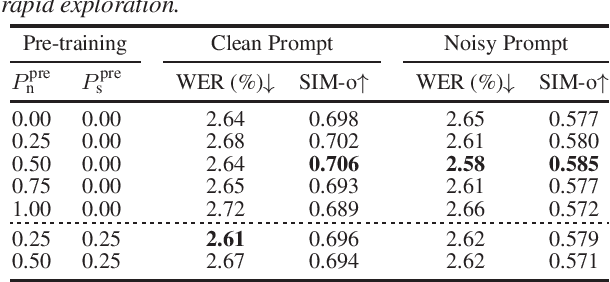
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
Jun 06, 2024



Accurate control of the total duration of generated speech by adjusting the speech rate is crucial for various text-to-speech (TTS) applications. However, the impact of adjusting the speech rate on speech quality, such as intelligibility and speaker characteristics, has been underexplored. In this work, we propose a novel total-duration-aware (TDA) duration model for TTS, where phoneme durations are predicted not only from the text input but also from an additional input of the total target duration. We also propose a MaskGIT-based duration model that enhances the diversity and quality of the predicted phoneme durations. Our results demonstrate that the proposed TDA duration models achieve better intelligibility and speaker similarity for various speech rate configurations compared to the baseline models. We also show that the proposed MaskGIT-based model can generate phoneme durations with higher quality and diversity compared to its regression or flow-matching counterparts.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.