 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems
Feb 10, 2025



Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list. Due to the inherent challenges of combinatorial search spaces, some current research adopts an evaluator-generator paradigm, with a generator generating feasible sequences and an evaluator selecting the best sequence based on the estimated list utility. However, these methods still face two issues. Firstly, due to the goal inconsistency problem between the evaluator and generator, the generator tends to fit the local optimal solution of exposure distribution rather than combinatorial space optimization. Secondly, the strategy of generating target items one by one is difficult to achieve optimality because it ignores the information of subsequent items. To address these issues, we propose a utilizing Neighbor Lists model for Generative Reranking (NLGR), which aims to improve the performance of the generator in the combinatorial space. NLGR follows the evaluator-generator paradigm and improves the generator's training and generating methods. Specifically, we use neighbor lists in combination space to enhance the training process, making the generator perceive the relative scores and find the optimization direction. Furthermore, we propose a novel sampling-based non-autoregressive generation method, which allows the generator to jump flexibly from the current list to any neighbor list. Extensive experiments on public and industrial datasets validate NLGR's effectiveness and we have successfully deployed NLGR on the Meituan food delivery platform.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
ContourFormer:Real-Time Contour-Based End-to-End Instance Segmentation Transformer
Jan 30, 2025



This paper presents Contourformer, a real-time contour-based instance segmentation algorithm. The method is fully based on the DETR paradigm and achieves end-to-end inference through iterative and progressive mechanisms to optimize contours. To improve efficiency and accuracy, we develop two novel techniques: sub-contour decoupling mechanisms and contour fine-grained distribution refinement. In the sub-contour decoupling mechanism, we propose a deformable attention-based module that adaptively selects sampling regions based on the current predicted contour, enabling more effective capturing of object boundary information. Additionally, we design a multi-stage optimization process to enhance segmentation precision by progressively refining sub-contours. The contour fine-grained distribution refinement technique aims to further improve the ability to express fine details of contours. These innovations enable Contourformer to achieve stable and precise segmentation for each instance while maintaining real-time performance. Extensive experiments demonstrate the superior performance of Contourformer on multiple benchmark datasets, including SBD, COCO, and KINS. We conduct comprehensive evaluations and comparisons with existing state-of-the-art methods, showing significant improvements in both accuracy and inference speed. This work provides a new solution for contour-based instance segmentation tasks and lays a foundation for future research, with the potential to become a strong baseline method in this field.
Entire Chain Uplift Modeling with Context-Enhanced Learning for Intelligent Marketing
Feb 04, 2024



Uplift modeling, vital in online marketing, seeks to accurately measure the impact of various strategies, such as coupons or discounts, on different users by predicting the Individual Treatment Effect (ITE). In an e-commerce setting, user behavior follows a defined sequential chain, including impression, click, and conversion. Marketing strategies exert varied uplift effects at each stage within this chain, impacting metrics like click-through and conversion rate. Despite its utility, existing research has neglected to consider the inter-task across all stages impacts within a specific treatment and has insufficiently utilized the treatment information, potentially introducing substantial bias into subsequent marketing decisions. We identify these two issues as the chain-bias problem and the treatment-unadaptive problem. This paper introduces the Entire Chain UPlift method with context-enhanced learning (ECUP), devised to tackle these issues. ECUP consists of two primary components: 1) the Entire Chain-Enhanced Network, which utilizes user behavior patterns to estimate ITE throughout the entire chain space, models the various impacts of treatments on each task, and integrates task prior information to enhance context awareness across all stages, capturing the impact of treatment on different tasks, and 2) the Treatment-Enhanced Network, which facilitates fine-grained treatment modeling through bit-level feature interactions, thereby enabling adaptive feature adjustment. Extensive experiments on public and industrial datasets validate ECUPs effectiveness. Moreover, ECUP has been deployed on the Meituan food delivery platform, serving millions of daily active users, with the related dataset released for future research.
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024

We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
Profile-Error-Tolerant Target-Speaker Voice Activity Detection
Sep 21, 2023Target-Speaker Voice Activity Detection (TS-VAD) utilizes a set of speaker profiles alongside an input audio signal to perform speaker diarization. While its superiority over conventional methods has been demonstrated, the method can suffer from errors in speaker profiles, as those profiles are typically obtained by running a traditional clustering-based diarization method over the input signal. This paper proposes an extension to TS-VAD, called Profile-Error-Tolerant TS-VAD (PET-TSVAD), which is robust to such speaker profile errors. This is achieved by employing transformer-based TS-VAD that can handle a variable number of speakers and further introducing a set of additional pseudo-speaker profiles to handle speakers undetected during the first pass diarization. During training, we use speaker profiles estimated by multiple different clustering algorithms to reduce the mismatch between the training and testing conditions regarding speaker profiles. Experimental results show that PET-TSVAD consistently outperforms the existing TS-VAD method on both the VoxConverse and DIHARD-I datasets.
A robust method for reliability updating with equality information using sequential adaptive importance sampling
Mar 08, 2023Reliability updating refers to a problem that integrates Bayesian updating technique with structural reliability analysis and cannot be directly solved by structural reliability methods (SRMs) when it involves equality information. The state-of-the-art approaches transform equality information into inequality information by introducing an auxiliary standard normal parameter. These methods, however, encounter the loss of computational efficiency due to the difficulty in finding the maximum of the likelihood function, the large coefficient of variation (COV) associated with the posterior failure probability and the inapplicability to dynamic updating problems where new information is constantly available. To overcome these limitations, this paper proposes an innovative method called RU-SAIS (reliability updating using sequential adaptive importance sampling), which combines elements of sequential importance sampling and K-means clustering to construct a series of important sampling densities (ISDs) using Gaussian mixture. The last ISD of the sequence is further adaptively modified through application of the cross entropy method. The performance of RU-SAIS is demonstrated by three examples. Results show that RU-SAIS achieves a more accurate and robust estimator of the posterior failure probability than the existing methods such as subset simulation.
Speaker Change Detection for Transformer Transducer ASR
Feb 16, 2023Speaker change detection (SCD) is an important feature that improves the readability of the recognized words from an automatic speech recognition (ASR) system by breaking the word sequence into paragraphs at speaker change points. Existing SCD solutions either require additional ensemble for the time based decisions and recognized word sequences, or implement a tight integration between ASR and SCD, limiting the potential optimum performance for both tasks. To address these issues, we propose a novel framework for the SCD task, where an additional SCD module is built on top of an existing Transformer Transducer ASR (TT-ASR) network. Two variants of the SCD network are explored in this framework that naturally estimate speaker change probability for each word, while allowing the ASR and SCD to have independent optimization scheme for the best performance. Experiments show that our methods can significantly improve the F1 score on LibriCSS and Microsoft call center data sets without ASR degradation, compared with a joint SCD and ASR baseline.
Target Speaker Voice Activity Detection with Transformers and Its Integration with End-to-End Neural Diarization
Aug 27, 2022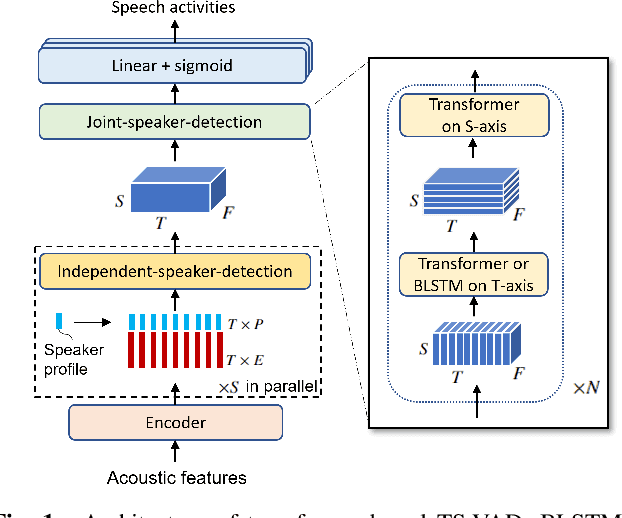
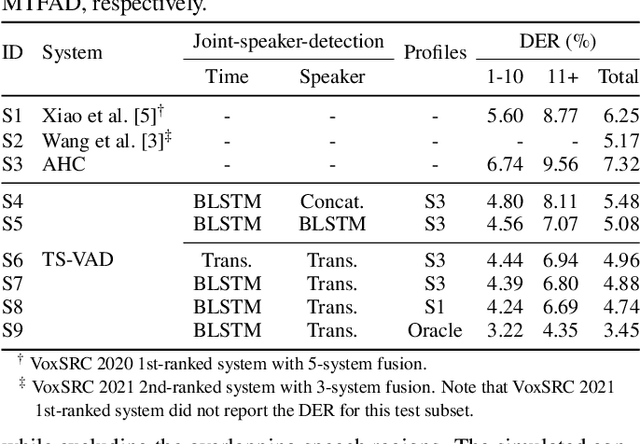
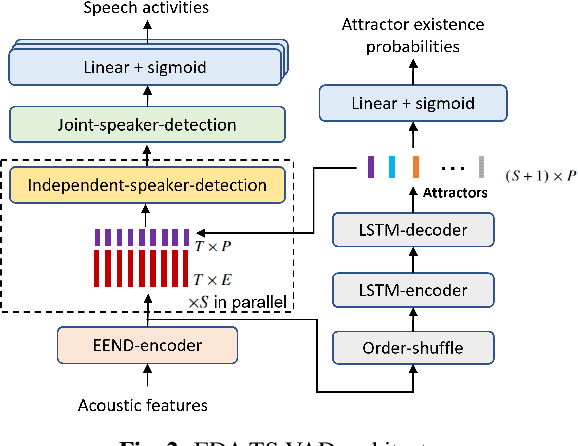
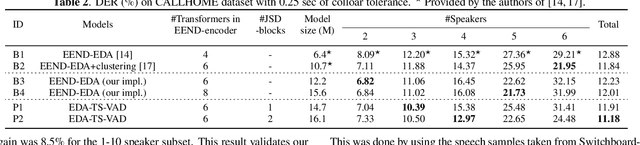
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 10.9%, achieving a new state-of-the-art (SOTA) DER of 4.74%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
Streaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
Mar 30, 2022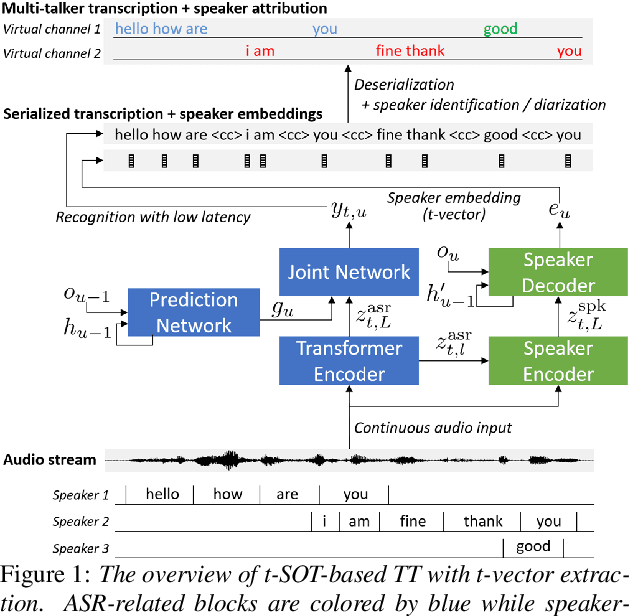
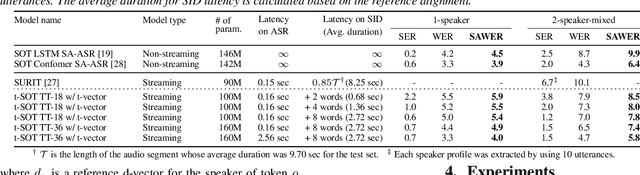
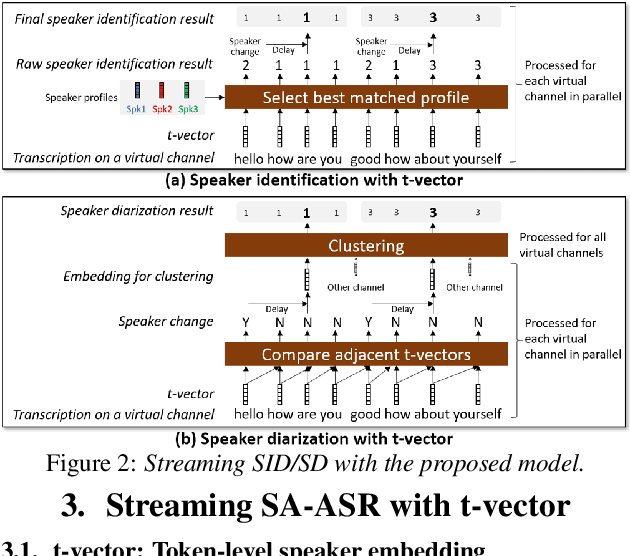

This paper presents a streaming speaker-attributed automatic speech recognition (SA-ASR) model that can recognize "who spoke what" with low latency even when multiple people are speaking simultaneously. Our model is based on token-level serialized output training (t-SOT) which was recently proposed to transcribe multi-talker speech in a streaming fashion. To further recognize speaker identities, we propose an encoder-decoder based speaker embedding extractor that can estimate a speaker representation for each recognized token not only from non-overlapping speech but also from overlapping speech. The proposed speaker embedding, named t-vector, is extracted synchronously with the t-SOT ASR model, enabling joint execution of speaker identification (SID) or speaker diarization (SD) with the multi-talker transcription with low latency. We evaluate the proposed model for a joint task of ASR and SID/SD by using LibriSpeechMix and LibriCSS corpora. The proposed model achieves substantially better accuracy than a prior streaming model and shows comparable or sometimes even superior results to the state-of-the-art offline SA-ASR model.