 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChecking Fact with Better Retrieval: Dynamic Contrastive Learning for Evidence Retrieval
May 24, 2026In the field of multimodal fact checking, the accuracy of retrieving evidence from different modalities has a significant impact on the downstream claim verification process. Existing general multimodal retrieval methods are often constructed based on semantics, resulting in the retrieved evidence being similar but not relevant to the claim. This paper proposes a \textbf{D}ynamic \textbf{A}daptive \textbf{C}ontrastive \textbf{L}earning method for evidence \textbf{R}etrieval called DACLR to address these issues. DACLR first uses a Multimodal Large Language Model (MLLM) to uniformly convert multimodal evidence and claims into text modalities, and extracts the features of these information at event level. Then, it conducts evidence retrieval through a two-stage retrieval method of recall-rerank. DACLR enhances the model's event perception ability of the retrieval stage by optimizing the contrastive loss and mining hard negative samples. Specifically, DACLR designs three loss functions at two levels (semantic and event) based on the InfoNCE loss.Corresponding to these, three sets of hard negative sample candidates are set up. The model dynamically adjusts the ratio based on the accuracy supervision signal of intra-batch samples, allowing the model to learn the correlation between claims and positive samples at the event level without forgetting the semantic retrieval ability. Extensive comparison and ablation experiments demonstrates the effectiveness of DACLR and its internal optimization methods. Further research also prove the advantages of DACLR in the field of multimodal evidence retrieval.
DataClaw: A Process-Oriented Agent Benchmark for Exploratory Real-World Data Analysis
May 04, 2026Evaluating autonomous data analysis agents requires testing their ability to perform exploratory analysis in underexplored data environments. However, many existing benchmarks emphasize final answer accuracy in prior-guided data settings and provide limited support for reasoning process evaluation. We introduce DataClaw, a process-oriented benchmark for exploratory real-world data analysis. DataClaw contains approximately 2.06 million real-world records across enterprise, industry and policy domains, with native data noise preserved. It further includes 492 cross-domain tasks derived from think-tank consulting scenarios, each annotated with intermediate milestones for process-level evaluation. These annotations allow DataClaw to measure how far an agent progresses and where its reasoning breaks down. Experiments with eight advanced LLMs show that current agents remain far from reliable in this setting, with seven models achieving below 50% overall accuracy. Process analysis further reveals partial progress hidden behind wrong answers and distinct exploration strategies across models. Overall, DataClaw provides a less data constrained diagnostic testbed for probing the capability boundaries of autonomous data-analysis agents.
EvoNash-MARL: A Closed-Loop Multi-Agent Reinforcement Learning Framework for Medium-Horizon Equity Allocation
Apr 14, 2026Medium- to long-horizon equity allocation is challenging due to weak predictive structure, non-stationary market regimes, and the degradation of signals under realistic trading constraints. Conventional approaches often rely on single predictors or loosely coupled pipelines, which limit robustness under distributional shift. This paper proposes EvoNash-MARL, a closed-loop framework that integrates reinforcement learning with population-based policy optimization and execution-aware selection to improve robustness in medium- to long-horizon allocation. The framework combines multi-agent policy populations, game-theoretic aggregation, and constraint-aware validation within a unified walk-forward design. Under a 120-window walk-forward protocol, the final configuration achieves the highest robust score among internal baselines. On out-of-sample data from 2014 to 2024, it delivers a 19.6% annualized return, compared to 11.7% for SPY, and remains stable under extended evaluation through 2026. While the framework demonstrates consistent performance under realistic constraints and across market settings, strong global statistical significance is not established under White's Reality Check (WRC) and SPA-lite tests. The results therefore provide evidence of improved robustness rather than definitive proof of superior market timing performance.
DBU-OFDM: A Trainable Deep Block-Unitary OFDM Waveform for Integrated Sensing and Communication
Apr 11, 2026Orthogonal frequency-division multiplexing (OFDM) is a dominant waveform in modern wireless systems, yet its high peak-to-average power ratio (PAPR) and limited adaptability hinder efficient support for integrated communication and sensing. This paper proposes deep block-unitary precoded OFDM (DBU-OFDM), a structure-preserving learning framework that enables trainable waveform adaptation while preserving the DFT-based signal structure, pilot/null resource protection, and compatibility with low-complexity frequency-domain equalization. The proposed design restricts learning to a block-unitary transformation over data subcarriers and preserves pilot and null resources for structural compatibility. The transform is parameterized by recursive Householder reflections, ensuring strict unitarity as well as differentiable, numerically stable, and complexity-controllable implementation. Results show that DBU-OFDM achieves PAPR tails close to block-pilot DFT-s-OFDM while retaining comb-type pilots, improves communication reliability in frequency-selective fading via frequency-domain diversity, and enhances range and velocity estimation in direct sensing, especially in dimension-limited settings. Over-the-air USRP experiments and FPGA prototyping further verify its practical feasibility, demonstrating low error vector magnitude (EVM), clear PAPR reduction in real transmission, and hardware throughput up to 200~MS/s with microsecond-level latency. DBU-OFDM therefore offers a practical intermediate solution between conventional model-based OFDM waveforms and unconstrained neural transceivers for next-generation integrated communication and sensing systems.
Neighbourhood Transformer: Switchable Attention for Monophily-Aware Graph Learning
Apr 10, 2026Graph neural networks (GNNs) have been widely adopted in engineering applications such as social network analysis, chemical research and computer vision. However, their efficacy is severely compromised by the inherent homophily assumption, which fails to hold for heterophilic graphs where dissimilar nodes are frequently connected. To address this fundamental limitation in graph learning, we first draw inspiration from the recently discovered monophily property of real-world graphs, and propose Neighbourhood Transformers (NT), a novel paradigm that applies self-attention within every local neighbourhood instead of aggregating messages to the central node as in conventional message-passing GNNs. This design makes NT inherently monophily-aware and theoretically guarantees its expressiveness is no weaker than traditional message-passing frameworks. For practical engineering deployment, we further develop a neighbourhood partitioning strategy equipped with switchable attentions, which reduces the space consumption of NT by over 95% and time consumption by up to 92.67%, significantly expanding its applicability to larger graphs. Extensive experiments on 10 real-world datasets (5 heterophilic and 5 homophilic graphs) show that NT outperforms all current state-of-the-art methods on node classification tasks, demonstrating its superior performance and cross-domain adaptability. The full implementation code of this work is publicly available at https://github.com/cf020031308/MoNT to facilitate reproducibility and industrial adoption.
See More, Change Less: Anatomy-Aware Diffusion for Contrast Enhancement
Dec 08, 2025Image enhancement improves visual quality and helps reveal details that are hard to see in the original image. In medical imaging, it can support clinical decision-making, but current models often over-edit. This can distort organs, create false findings, and miss small tumors because these models do not understand anatomy or contrast dynamics. We propose SMILE, an anatomy-aware diffusion model that learns how organs are shaped and how they take up contrast. It enhances only clinically relevant regions while leaving all other areas unchanged. SMILE introduces three key ideas: (1) structure-aware supervision that follows true organ boundaries and contrast patterns; (2) registration-free learning that works directly with unaligned multi-phase CT scans; (3) unified inference that provides fast and consistent enhancement across all contrast phases. Across six external datasets, SMILE outperforms existing methods in image quality (14.2% higher SSIM, 20.6% higher PSNR, 50% better FID) and in clinical usefulness by producing anatomically accurate and diagnostically meaningful images. SMILE also improves cancer detection from non-contrast CT, raising the F1 score by up to 10 percent.
Scale-Aware Curriculum Learning for Ddata-Efficient Lung Nodule Detection with YOLOv11
Oct 30, 2025Lung nodule detection in chest CT is crucial for early lung cancer diagnosis, yet existing deep learning approaches face challenges when deployed in clinical settings with limited annotated data. While curriculum learning has shown promise in improving model training, traditional static curriculum strategies fail in data-scarce scenarios. We propose Scale Adaptive Curriculum Learning (SACL), a novel training strategy that dynamically adjusts curriculum design based on available data scale. SACL introduces three key mechanisms:(1) adaptive epoch scheduling, (2) hard sample injection, and (3) scale-aware optimization. We evaluate SACL on the LUNA25 dataset using YOLOv11 as the base detector. Experimental results demonstrate that while SACL achieves comparable performance to static curriculum learning on the full dataset in mAP50, it shows significant advantages under data-limited conditions with 4.6%, 3.5%, and 2.0% improvements over baseline at 10%, 20%, and 50% of training data respectively. By enabling robust training across varying data scales without architectural modifications, SACL provides a practical solution for healthcare institutions to develop effective lung nodule detection systems despite limited annotation resources.
WAKE: Watermarking Audio with Key Enrichment
Jun 06, 2025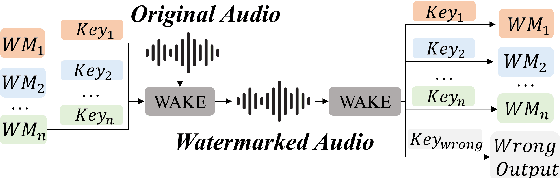

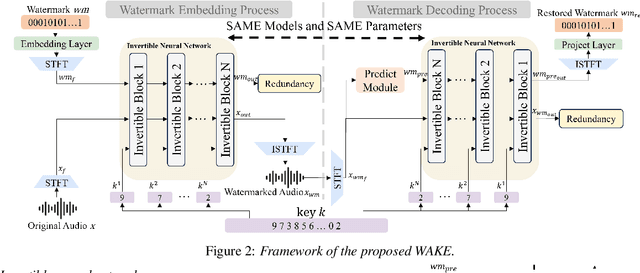
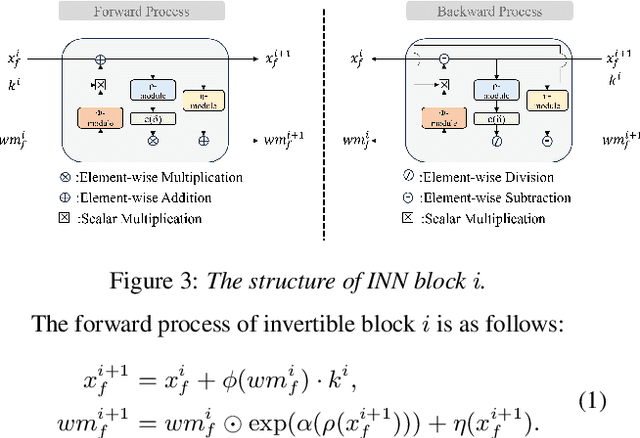
As deep learning advances in audio generation, challenges in audio security and copyright protection highlight the need for robust audio watermarking. Recent neural network-based methods have made progress but still face three main issues: preventing unauthorized access, decoding initial watermarks after multiple embeddings, and embedding varying lengths of watermarks. To address these issues, we propose WAKE, the first key-controllable audio watermark framework. WAKE embeds watermarks using specific keys and recovers them with corresponding keys, enhancing security by making incorrect key decoding impossible. It also resolves the overwriting issue by allowing watermark decoding after multiple embeddings and supports variable-length watermark insertion. WAKE outperforms existing models in both watermarked audio quality and watermark detection accuracy. Code, more results, and demo page: https://thuhcsi.github.io/WAKE.
HiCaM: A Hierarchical-Causal Modification Framework for Long-Form Text Modification
May 30, 2025Large Language Models (LLMs) have achieved remarkable success in various domains. However, when handling long-form text modification tasks, they still face two major problems: (1) producing undesired modifications by inappropriately altering or summarizing irrelevant content, and (2) missing necessary modifications to implicitly related passages that are crucial for maintaining document coherence. To address these issues, we propose HiCaM, a Hierarchical-Causal Modification framework that operates through a hierarchical summary tree and a causal graph. Furthermore, to evaluate HiCaM, we derive a multi-domain dataset from various benchmarks, providing a resource for assessing its effectiveness. Comprehensive evaluations on the dataset demonstrate significant improvements over strong LLMs, with our method achieving up to a 79.50\% win rate. These results highlight the comprehensiveness of our approach, showing consistent performance improvements across multiple models and domains.
Generalized Category Discovery in Event-Centric Contexts: Latent Pattern Mining with LLMs
May 29, 2025Generalized Category Discovery (GCD) aims to classify both known and novel categories using partially labeled data that contains only known classes. Despite achieving strong performance on existing benchmarks, current textual GCD methods lack sufficient validation in realistic settings. We introduce Event-Centric GCD (EC-GCD), characterized by long, complex narratives and highly imbalanced class distributions, posing two main challenges: (1) divergent clustering versus classification groupings caused by subjective criteria, and (2) Unfair alignment for minority classes. To tackle these, we propose PaMA, a framework leveraging LLMs to extract and refine event patterns for improved cluster-class alignment. Additionally, a ranking-filtering-mining pipeline ensures balanced representation of prototypes across imbalanced categories. Evaluations on two EC-GCD benchmarks, including a newly constructed Scam Report dataset, demonstrate that PaMA outperforms prior methods with up to 12.58% H-score gains, while maintaining strong generalization on base GCD datasets.