 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Mar 01, 2026Open-world promptable 3D semantic segmentation remains brittle as semantics are inferred in the input sensor coordinates. Yet, humans, in contrast, interpret parts via functional roles in a canonical space -- wings extend laterally, handles protrude to the side, and legs support from below. Psychophysical evidence shows that we mentally rotate objects into canonical frames to reveal these roles. To fill this gap, we propose \methodName{}, which attains canonical space perception by inducing a latent canonical reference frame learned directly from data. By construction, we create a unified canonical dataset through LLM-guided intra- and cross-category alignment, exposing canonical spatial regularities across 200 categories. By induction, we realize canonicality inside the model through a dual-branch architecture with canonical map anchoring and canonical box calibration, collapsing pose variation and symmetry into a stable canonical embedding. This shift from input pose space to canonical embedding yields far more stable and transferable part semantics. Experimental results show that \methodName{} establishes new state of the art in open-world promptable 3D segmentation.
Large Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
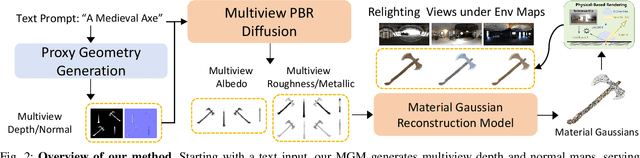
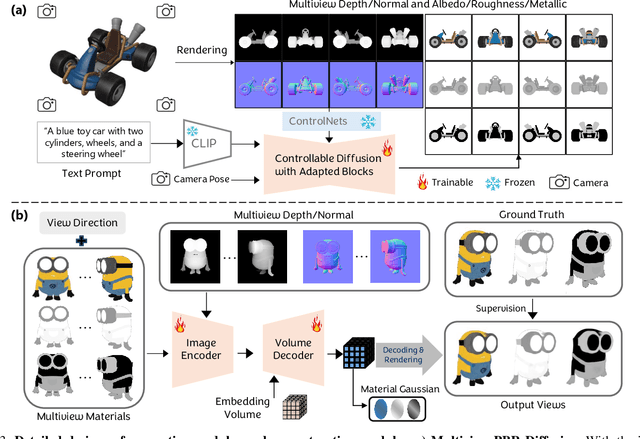

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
MAR-3D: Progressive Masked Auto-regressor for High-Resolution 3D Generation
Mar 27, 2025Recent advances in auto-regressive transformers have revolutionized generative modeling across different domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential next-token prediction paradigm, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution latent prediction. To address these challenges, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent upscaling in the continuous space. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficiently up-scale the latent token resolution with fast convergence. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling capabilities compared to joint distribution modeling approaches (e.g., diffusion transformers).
MotionLab: Unified Human Motion Generation and Editing via the Motion-Condition-Motion Paradigm
Feb 06, 2025



Human motion generation and editing are key components of computer graphics and vision. However, current approaches in this field tend to offer isolated solutions tailored to specific tasks, which can be inefficient and impractical for real-world applications. While some efforts have aimed to unify motion-related tasks, these methods simply use different modalities as conditions to guide motion generation. Consequently, they lack editing capabilities, fine-grained control, and fail to facilitate knowledge sharing across tasks. To address these limitations and provide a versatile, unified framework capable of handling both human motion generation and editing, we introduce a novel paradigm: Motion-Condition-Motion, which enables the unified formulation of diverse tasks with three concepts: source motion, condition, and target motion. Based on this paradigm, we propose a unified framework, MotionLab, which incorporates rectified flows to learn the mapping from source motion to target motion, guided by the specified conditions. In MotionLab, we introduce the 1) MotionFlow Transformer to enhance conditional generation and editing without task-specific modules; 2) Aligned Rotational Position Encoding} to guarantee the time synchronization between source motion and target motion; 3) Task Specified Instruction Modulation; and 4) Motion Curriculum Learning for effective multi-task learning and knowledge sharing across tasks. Notably, our MotionLab demonstrates promising generalization capabilities and inference efficiency across multiple benchmarks for human motion. Our code and additional video results are available at: https://diouo.github.io/motionlab.github.io/.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
Off-the-shelf ChatGPT is a Good Few-shot Human Motion Predictor
May 24, 2024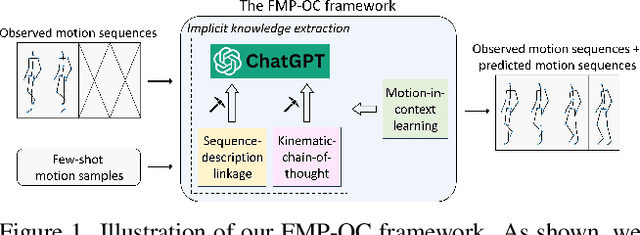
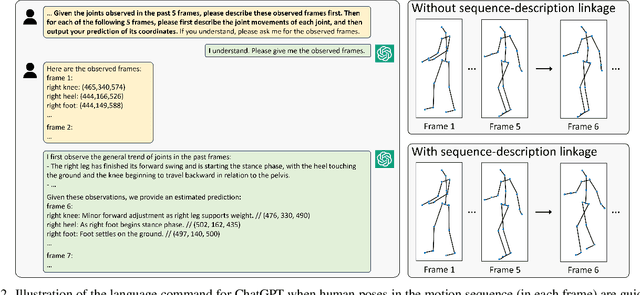
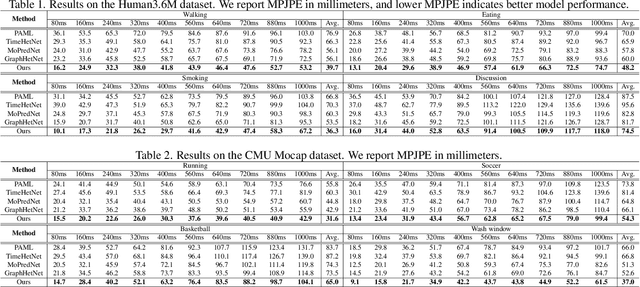
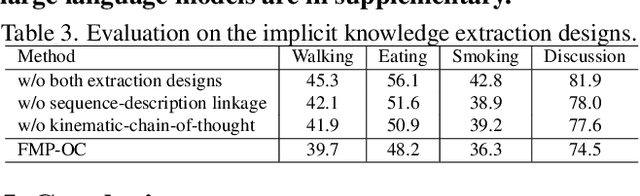
To facilitate the application of motion prediction in practice, recently, the few-shot motion prediction task has attracted increasing research attention. Yet, in existing few-shot motion prediction works, a specific model that is dedicatedly trained over human motions is generally required. In this work, rather than tackling this task through training a specific human motion prediction model, we instead propose a novel FMP-OC framework. In FMP-OC, in a totally training-free manner, we enable Few-shot Motion Prediction, which is a non-language task, to be performed directly via utilizing the Off-the-shelf language model ChatGPT. Specifically, to lead ChatGPT as a language model to become an accurate motion predictor, in FMP-OC, we first introduce several novel designs to facilitate extracting implicit knowledge from ChatGPT. Moreover, we also incorporate our framework with a motion-in-context learning mechanism. Extensive experiments demonstrate the efficacy of our proposed framework.
Contrastive Learning Method for Sequential Recommendation based on Multi-Intention Disentanglement
Apr 28, 2024Sequential recommendation is one of the important branches of recommender system, aiming to achieve personalized recommended items for the future through the analysis and prediction of users' ordered historical interactive behaviors. However, along with the growth of the user volume and the increasingly rich behavioral information, how to understand and disentangle the user's interactive multi-intention effectively also poses challenges to behavior prediction and sequential recommendation. In light of these challenges, we propose a Contrastive Learning sequential recommendation method based on Multi-Intention Disentanglement (MIDCL). In our work, intentions are recognized as dynamic and diverse, and user behaviors are often driven by current multi-intentions, which means that the model needs to not only mine the most relevant implicit intention for each user, but also impair the influence from irrelevant intentions. Therefore, we choose Variational Auto-Encoder (VAE) to realize the disentanglement of users' multi-intentions, and propose two types of contrastive learning paradigms for finding the most relevant user's interactive intention, and maximizing the mutual information of positive sample pairs, respectively. Experimental results show that MIDCL not only has significant superiority over most existing baseline methods, but also brings a more interpretable case to the research about intention-based prediction and recommendation.
LiDAL: Inter-frame Uncertainty Based Active Learning for 3D LiDAR Semantic Segmentation
Nov 11, 2022We propose LiDAL, a novel active learning method for 3D LiDAR semantic segmentation by exploiting inter-frame uncertainty among LiDAR frames. Our core idea is that a well-trained model should generate robust results irrespective of viewpoints for scene scanning and thus the inconsistencies in model predictions across frames provide a very reliable measure of uncertainty for active sample selection. To implement this uncertainty measure, we introduce new inter-frame divergence and entropy formulations, which serve as the metrics for active selection. Moreover, we demonstrate additional performance gains by predicting and incorporating pseudo-labels, which are also selected using the proposed inter-frame uncertainty measure. Experimental results validate the effectiveness of LiDAL: we achieve 95% of the performance of fully supervised learning with less than 5% of annotations on the SemanticKITTI and nuScenes datasets, outperforming state-of-the-art active learning methods. Code release: https://github.com/hzykent/LiDAL.
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
Mar 22, 2022
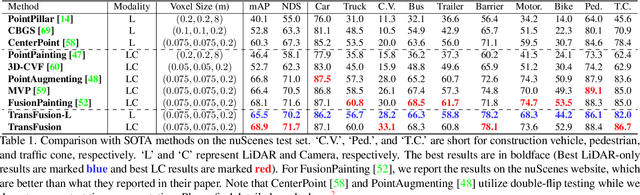
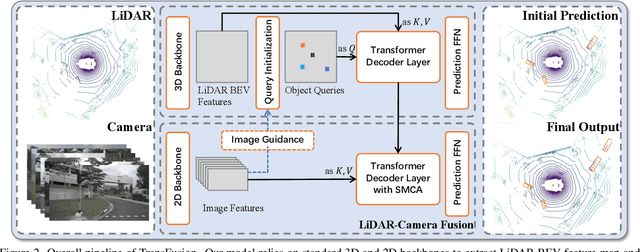
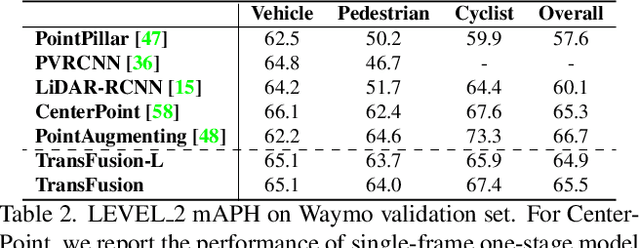
LiDAR and camera are two important sensors for 3D object detection in autonomous driving. Despite the increasing popularity of sensor fusion in this field, the robustness against inferior image conditions, e.g., bad illumination and sensor misalignment, is under-explored. Existing fusion methods are easily affected by such conditions, mainly due to a hard association of LiDAR points and image pixels, established by calibration matrices. We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions. Specifically, our TransFusion consists of convolutional backbones and a detection head based on a transformer decoder. The first layer of the decoder predicts initial bounding boxes from a LiDAR point cloud using a sparse set of object queries, and its second decoder layer adaptively fuses the object queries with useful image features, leveraging both spatial and contextual relationships. The attention mechanism of the transformer enables our model to adaptively determine where and what information should be taken from the image, leading to a robust and effective fusion strategy. We additionally design an image-guided query initialization strategy to deal with objects that are difficult to detect in point clouds. TransFusion achieves state-of-the-art performance on large-scale datasets. We provide extensive experiments to demonstrate its robustness against degenerated image quality and calibration errors. We also extend the proposed method to the 3D tracking task and achieve the 1st place in the leaderboard of nuScenes tracking, showing its effectiveness and generalization capability.
Learning to Match Features with Seeded Graph Matching Network
Aug 19, 2021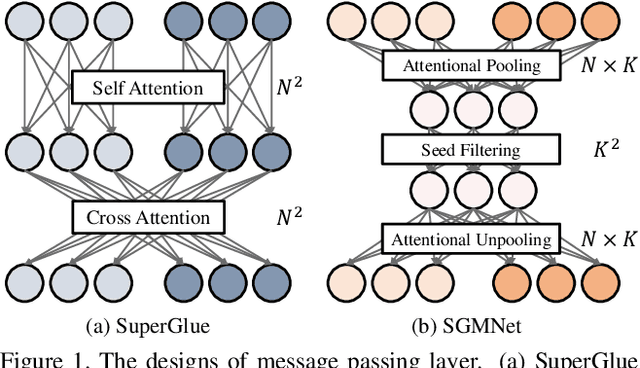
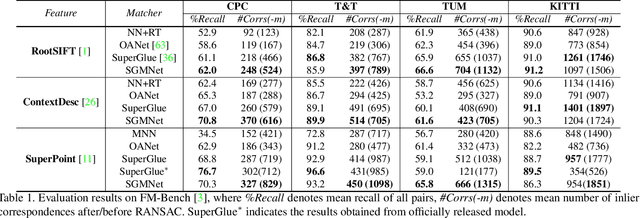
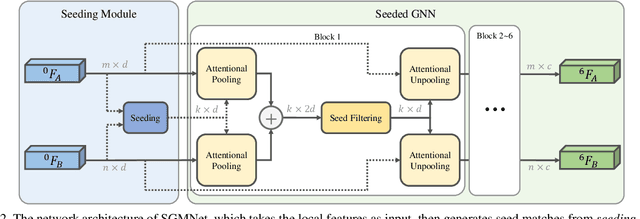
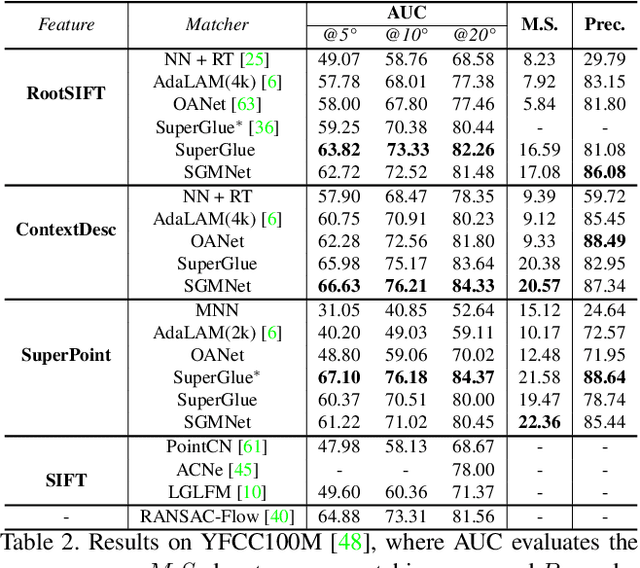
Matching local features across images is a fundamental problem in computer vision. Targeting towards high accuracy and efficiency, we propose Seeded Graph Matching Network, a graph neural network with sparse structure to reduce redundant connectivity and learn compact representation. The network consists of 1) Seeding Module, which initializes the matching by generating a small set of reliable matches as seeds. 2) Seeded Graph Neural Network, which utilizes seed matches to pass messages within/across images and predicts assignment costs. Three novel operations are proposed as basic elements for message passing: 1) Attentional Pooling, which aggregates keypoint features within the image to seed matches. 2) Seed Filtering, which enhances seed features and exchanges messages across images. 3) Attentional Unpooling, which propagates seed features back to original keypoints. Experiments show that our method reduces computational and memory complexity significantly compared with typical attention-based networks while competitive or higher performance is achieved.