 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
May 26, 2025
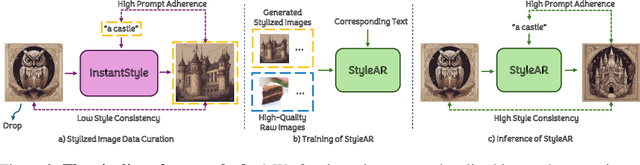

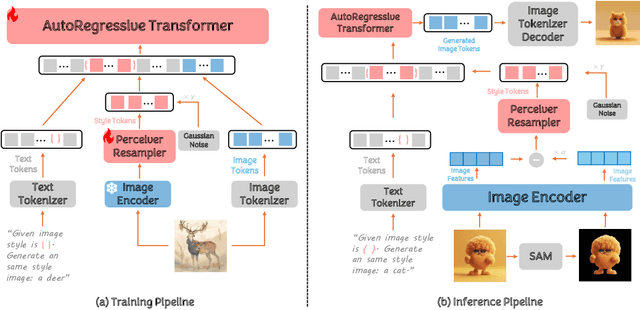
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.
MAR-3D: Progressive Masked Auto-regressor for High-Resolution 3D Generation
Mar 27, 2025Recent advances in auto-regressive transformers have revolutionized generative modeling across different domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential next-token prediction paradigm, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution latent prediction. To address these challenges, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent upscaling in the continuous space. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficiently up-scale the latent token resolution with fast convergence. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling capabilities compared to joint distribution modeling approaches (e.g., diffusion transformers).
Text-Animator: Controllable Visual Text Video Generation
Jun 25, 2024Video generation is a challenging yet pivotal task in various industries, such as gaming, e-commerce, and advertising. One significant unresolved aspect within T2V is the effective visualization of text within generated videos. Despite the progress achieved in Text-to-Video~(T2V) generation, current methods still cannot effectively visualize texts in videos directly, as they mainly focus on summarizing semantic scene information, understanding, and depicting actions. While recent advances in image-level visual text generation show promise, transitioning these techniques into the video domain faces problems, notably in preserving textual fidelity and motion coherence. In this paper, we propose an innovative approach termed Text-Animator for visual text video generation. Text-Animator contains a text embedding injection module to precisely depict the structures of visual text in generated videos. Besides, we develop a camera control module and a text refinement module to improve the stability of generated visual text by controlling the camera movement as well as the motion of visualized text. Quantitative and qualitative experimental results demonstrate the superiority of our approach to the accuracy of generated visual text over state-of-the-art video generation methods. The project page can be found at https://laulampaul.github.io/text-animator.html.
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Apr 23, 2024



Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation. Extensive experiments demonstrate the superiority of ID-Animator to generate personalized human videos over previous models. Moreover, our method is highly compatible with popular pre-trained T2V models like animatediff and various community backbone models, showing high extendability in real-world applications for video generation where identity preservation is highly desired. Our codes and checkpoints will be released at https://github.com/ID-Animator/ID-Animator.
Visual CoT: Unleashing Chain-of-Thought Reasoning in Multi-Modal Language Models
Mar 25, 2024



This paper presents Visual CoT, a novel pipeline that leverages the reasoning capabilities of multi-modal large language models (MLLMs) by incorporating visual Chain-of-Thought (CoT) reasoning. While MLLMs have shown promise in various visual tasks, they often lack interpretability and struggle with complex visual inputs. To address these challenges, we propose a multi-turn processing pipeline that dynamically focuses on visual inputs and provides interpretable thoughts. We collect and introduce the Visual CoT dataset comprising 373k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions. Importantly, the introduced benchmark is capable of evaluating MLLMs in scenarios requiring specific local region identification. Extensive experiments demonstrate the effectiveness of our framework and shed light on better inference strategies. The Visual CoT dataset, benchmark, and pre-trained models are available to foster further research in this direction.
Prompt Highlighter: Interactive Control for Multi-Modal LLMs
Dec 07, 2023



This study targets a critical aspect of multi-modal LLMs' (LLMs&VLMs) inference: explicit controllable text generation. Multi-modal LLMs empower multi-modality understanding with the capability of semantic generation yet bring less explainability and heavier reliance on prompt contents due to their autoregressive generative nature. While manipulating prompt formats could improve outputs, designing specific and precise prompts per task can be challenging and ineffective. To tackle this issue, we introduce a novel inference method, Prompt Highlighter, which enables users to highlight specific prompt spans to interactively control the focus during generation. Motivated by the classifier-free diffusion guidance, we form regular and unconditional context pairs based on highlighted tokens, demonstrating that the autoregressive generation in models can be guided in a classifier-free way. Notably, we find that, during inference, guiding the models with highlighted tokens through the attention weights leads to more desired outputs. Our approach is compatible with current LLMs and VLMs, achieving impressive customized generation results without training. Experiments confirm its effectiveness in focusing on input contexts and generating reliable content. Without tuning on LLaVA-v1.5, our method secured 69.5 in the MMBench test and 1552.5 in MME-perception. The code is available at: https://github.com/dvlab-research/Prompt-Highlighter/
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Sep 21, 2023



We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference. On the other hand, we revisit the parameter-efficient fine-tuning regime for context expansion. Notably, we find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on LLaMA2 models from 7B/13B to 70B. LongLoRA adopts LLaMA2 7B from 4k context to 100k, or LLaMA2 70B to 32k on a single 8x A100 machine. LongLoRA extends models' context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2. In addition, to make LongLoRA practical, we collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation
Apr 15, 2023



Recent success of Contrastive Language-Image Pre-training~(CLIP) has shown great promise in pixel-level open-vocabulary learning tasks. A general paradigm utilizes CLIP's text and patch embeddings to generate semantic masks. However, existing models easily misidentify input pixels from unseen classes, thus confusing novel classes with semantically-similar ones. In our work, we disentangle the ill-posed optimization problem into two parallel processes: one performs semantic matching individually, and the other judges reliability for improving discrimination ability. Motivated by special tokens in language modeling that represents sentence-level embeddings, we design a trusty token that decouples the known and novel category prediction tendency. With almost no extra overhead, we upgrade the pixel-level generalization capacity of existing models effectively. Our TagCLIP (CLIP adapting with Trusty-guidance) boosts the IoU of unseen classes by 7.4% and 1.7% on PASCAL VOC 2012 and COCO-Stuff 164K.
StraIT: Non-autoregressive Generation with Stratified Image Transformer
Mar 01, 2023We propose Stratified Image Transformer(StraIT), a pure non-autoregressive(NAR) generative model that demonstrates superiority in high-quality image synthesis over existing autoregressive(AR) and diffusion models(DMs). In contrast to the under-exploitation of visual characteristics in existing vision tokenizer, we leverage the hierarchical nature of images to encode visual tokens into stratified levels with emergent properties. Through the proposed image stratification that obtains an interlinked token pair, we alleviate the modeling difficulty and lift the generative power of NAR models. Our experiments demonstrate that StraIT significantly improves NAR generation and out-performs existing DMs and AR methods while being order-of-magnitude faster, achieving FID scores of 3.96 at 256*256 resolution on ImageNet without leveraging any guidance in sampling or auxiliary image classifiers. When equipped with classifier-free guidance, our method achieves an FID of 3.36 and IS of 259.3. In addition, we illustrate the decoupled modeling process of StraIT generation, showing its compelling properties on applications including domain transfer.
What Makes for Good Tokenizers in Vision Transformer?
Dec 21, 2022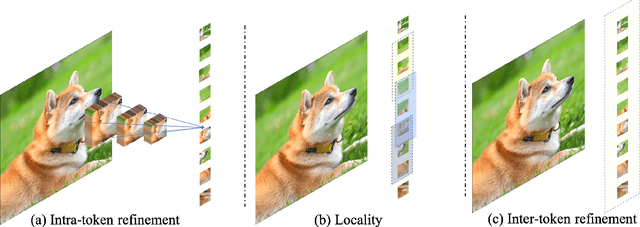



The architecture of transformers, which recently witness booming applications in vision tasks, has pivoted against the widespread convolutional paradigm. Relying on the tokenization process that splits inputs into multiple tokens, transformers are capable of extracting their pairwise relationships using self-attention. While being the stemming building block of transformers, what makes for a good tokenizer has not been well understood in computer vision. In this work, we investigate this uncharted problem from an information trade-off perspective. In addition to unifying and understanding existing structural modifications, our derivation leads to better design strategies for vision tokenizers. The proposed Modulation across Tokens (MoTo) incorporates inter-token modeling capability through normalization. Furthermore, a regularization objective TokenProp is embraced in the standard training regime. Through extensive experiments on various transformer architectures, we observe both improved performance and intriguing properties of these two plug-and-play designs with negligible computational overhead. These observations further indicate the importance of the commonly-omitted designs of tokenizers in vision transformer.