 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
Self-supervised Multiplex Consensus Mamba for General Image Fusion
Dec 24, 2025Image fusion integrates complementary information from different modalities to generate high-quality fused images, thereby enhancing downstream tasks such as object detection and semantic segmentation. Unlike task-specific techniques that primarily focus on consolidating inter-modal information, general image fusion needs to address a wide range of tasks while improving performance without increasing complexity. To achieve this, we propose SMC-Mamba, a Self-supervised Multiplex Consensus Mamba framework for general image fusion. Specifically, the Modality-Agnostic Feature Enhancement (MAFE) module preserves fine details through adaptive gating and enhances global representations via spatial-channel and frequency-rotational scanning. The Multiplex Consensus Cross-modal Mamba (MCCM) module enables dynamic collaboration among experts, reaching a consensus to efficiently integrate complementary information from multiple modalities. The cross-modal scanning within MCCM further strengthens feature interactions across modalities, facilitating seamless integration of critical information from both sources. Additionally, we introduce a Bi-level Self-supervised Contrastive Learning Loss (BSCL), which preserves high-frequency information without increasing computational overhead while simultaneously boosting performance in downstream tasks. Extensive experiments demonstrate that our approach outperforms state-of-the-art (SOTA) image fusion algorithms in tasks such as infrared-visible, medical, multi-focus, and multi-exposure fusion, as well as downstream visual tasks.
Active Intelligence in Video Avatars via Closed-loop World Modeling
Dec 23, 2025Current video avatar generation methods excel at identity preservation and motion alignment but lack genuine agency, they cannot autonomously pursue long-term goals through adaptive environmental interaction. We address this by introducing L-IVA (Long-horizon Interactive Visual Avatar), a task and benchmark for evaluating goal-directed planning in stochastic generative environments, and ORCA (Online Reasoning and Cognitive Architecture), the first framework enabling active intelligence in video avatars. ORCA embodies Internal World Model (IWM) capabilities through two key innovations: (1) a closed-loop OTAR cycle (Observe-Think-Act-Reflect) that maintains robust state tracking under generative uncertainty by continuously verifying predicted outcomes against actual generations, and (2) a hierarchical dual-system architecture where System 2 performs strategic reasoning with state prediction while System 1 translates abstract plans into precise, model-specific action captions. By formulating avatar control as a POMDP and implementing continuous belief updating with outcome verification, ORCA enables autonomous multi-step task completion in open-domain scenarios. Extensive experiments demonstrate that ORCA significantly outperforms open-loop and non-reflective baselines in task success rate and behavioral coherence, validating our IWM-inspired design for advancing video avatar intelligence from passive animation to active, goal-oriented behavior.
Lay2Story: Extending Diffusion Transformers for Layout-Togglable Story Generation
Aug 12, 2025Storytelling tasks involving generating consistent subjects have gained significant attention recently. However, existing methods, whether training-free or training-based, continue to face challenges in maintaining subject consistency due to the lack of fine-grained guidance and inter-frame interaction. Additionally, the scarcity of high-quality data in this field makes it difficult to precisely control storytelling tasks, including the subject's position, appearance, clothing, expression, and posture, thereby hindering further advancements. In this paper, we demonstrate that layout conditions, such as the subject's position and detailed attributes, effectively facilitate fine-grained interactions between frames. This not only strengthens the consistency of the generated frame sequence but also allows for precise control over the subject's position, appearance, and other key details. Building on this, we introduce an advanced storytelling task: Layout-Togglable Storytelling, which enables precise subject control by incorporating layout conditions. To address the lack of high-quality datasets with layout annotations for this task, we develop Lay2Story-1M, which contains over 1 million 720p and higher-resolution images, processed from approximately 11,300 hours of cartoon videos. Building on Lay2Story-1M, we create Lay2Story-Bench, a benchmark with 3,000 prompts designed to evaluate the performance of different methods on this task. Furthermore, we propose Lay2Story, a robust framework based on the Diffusion Transformers (DiTs) architecture for Layout-Togglable Storytelling tasks. Through both qualitative and quantitative experiments, we find that our method outperforms the previous state-of-the-art (SOTA) techniques, achieving the best results in terms of consistency, semantic correlation, and aesthetic quality.
Distilling Textual Priors from LLM to Efficient Image Fusion
Apr 09, 2025



Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model's ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10\% of the parameters and inference time of the teacher network, retains 90\% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
WISA: World Simulator Assistant for Physics-Aware Text-to-Video Generation
Mar 11, 2025Recent rapid advancements in text-to-video (T2V) generation, such as SoRA and Kling, have shown great potential for building world simulators. However, current T2V models struggle to grasp abstract physical principles and generate videos that adhere to physical laws. This challenge arises primarily from a lack of clear guidance on physical information due to a significant gap between abstract physical principles and generation models. To this end, we introduce the World Simulator Assistant (WISA), an effective framework for decomposing and incorporating physical principles into T2V models. Specifically, WISA decomposes physical principles into textual physical descriptions, qualitative physical categories, and quantitative physical properties. To effectively embed these physical attributes into the generation process, WISA incorporates several key designs, including Mixture-of-Physical-Experts Attention (MoPA) and a Physical Classifier, enhancing the model's physics awareness. Furthermore, most existing datasets feature videos where physical phenomena are either weakly represented or entangled with multiple co-occurring processes, limiting their suitability as dedicated resources for learning explicit physical principles. We propose a novel video dataset, WISA-32K, collected based on qualitative physical categories. It consists of 32,000 videos, representing 17 physical laws across three domains of physics: dynamics, thermodynamics, and optics. Experimental results demonstrate that WISA can effectively enhance the compatibility of T2V models with real-world physical laws, achieving a considerable improvement on the VideoPhy benchmark. The visual exhibitions of WISA and WISA-32K are available in the https://360cvgroup.github.io/WISA/.
U-StyDiT: Ultra-high Quality Artistic Style Transfer Using Diffusion Transformers
Mar 11, 2025Ultra-high quality artistic style transfer refers to repainting an ultra-high quality content image using the style information learned from the style image. Existing artistic style transfer methods can be categorized into style reconstruction-based and content-style disentanglement-based style transfer approaches. Although these methods can generate some artistic stylized images, they still exhibit obvious artifacts and disharmonious patterns, which hinder their ability to produce ultra-high quality artistic stylized images. To address these issues, we propose a novel artistic image style transfer method, U-StyDiT, which is built on transformer-based diffusion (DiT) and learns content-style disentanglement, generating ultra-high quality artistic stylized images. Specifically, we first design a Multi-view Style Modulator (MSM) to learn style information from a style image from local and global perspectives, conditioning U-StyDiT to generate stylized images with the learned style information. Then, we introduce a StyDiT Block to learn content and style conditions simultaneously from a style image. Additionally, we propose an ultra-high quality artistic image dataset, Aes4M, comprising 10 categories, each containing 400,000 style images. This dataset effectively solves the problem that the existing style transfer methods cannot produce high-quality artistic stylized images due to the size of the dataset and the quality of the images in the dataset. Finally, the extensive qualitative and quantitative experiments validate that our U-StyDiT can create higher quality stylized images compared to state-of-the-art artistic style transfer methods. To our knowledge, our proposed method is the first to address the generation of ultra-high quality stylized images using transformer-based diffusion.
RelaCtrl: Relevance-Guided Efficient Control for Diffusion Transformers
Feb 21, 2025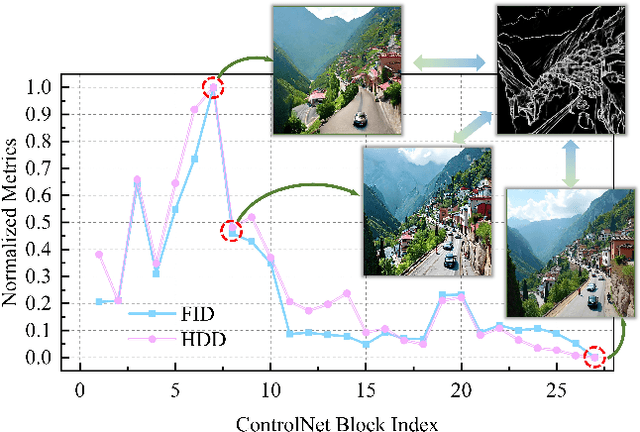
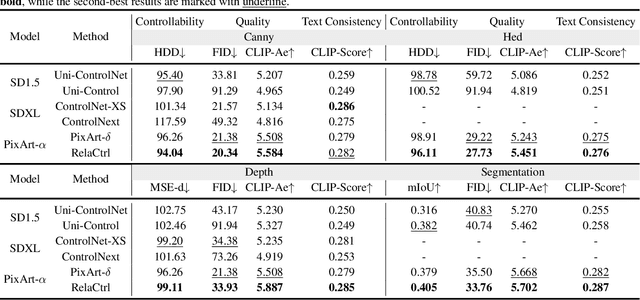
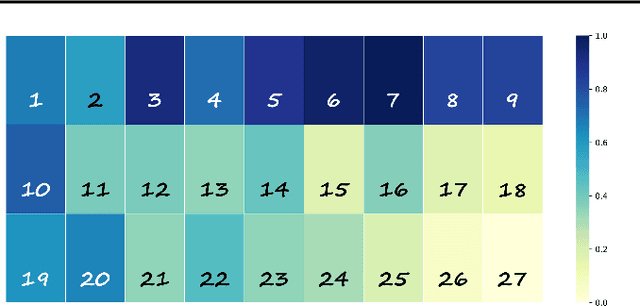
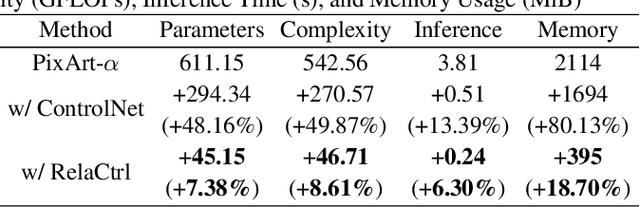
The Diffusion Transformer plays a pivotal role in advancing text-to-image and text-to-video generation, owing primarily to its inherent scalability. However, existing controlled diffusion transformer methods incur significant parameter and computational overheads and suffer from inefficient resource allocation due to their failure to account for the varying relevance of control information across different transformer layers. To address this, we propose the Relevance-Guided Efficient Controllable Generation framework, RelaCtrl, enabling efficient and resource-optimized integration of control signals into the Diffusion Transformer. First, we evaluate the relevance of each layer in the Diffusion Transformer to the control information by assessing the "ControlNet Relevance Score"-i.e., the impact of skipping each control layer on both the quality of generation and the control effectiveness during inference. Based on the strength of the relevance, we then tailor the positioning, parameter scale, and modeling capacity of the control layers to reduce unnecessary parameters and redundant computations. Additionally, to further improve efficiency, we replace the self-attention and FFN in the commonly used copy block with the carefully designed Two-Dimensional Shuffle Mixer (TDSM), enabling efficient implementation of both the token mixer and channel mixer. Both qualitative and quantitative experimental results demonstrate that our approach achieves superior performance with only 15% of the parameters and computational complexity compared to PixArt-delta.
Shuffle Mamba: State Space Models with Random Shuffle for Multi-Modal Image Fusion
Sep 03, 2024



Multi-modal image fusion integrates complementary information from different modalities to produce enhanced and informative images. Although State-Space Models, such as Mamba, are proficient in long-range modeling with linear complexity, most Mamba-based approaches use fixed scanning strategies, which can introduce biased prior information. To mitigate this issue, we propose a novel Bayesian-inspired scanning strategy called Random Shuffle, supplemented by an theoretically-feasible inverse shuffle to maintain information coordination invariance, aiming to eliminate biases associated with fixed sequence scanning. Based on this transformation pair, we customized the Shuffle Mamba Framework, penetrating modality-aware information representation and cross-modality information interaction across spatial and channel axes to ensure robust interaction and an unbiased global receptive field for multi-modal image fusion. Furthermore, we develop a testing methodology based on Monte-Carlo averaging to ensure the model's output aligns more closely with expected results. Extensive experiments across multiple multi-modal image fusion tasks demonstrate the effectiveness of our proposed method, yielding excellent fusion quality over state-of-the-art alternatives. Code will be available upon acceptance.
Training-Free Large Model Priors for Multiple-in-One Image Restoration
Jul 18, 2024Image restoration aims to reconstruct the latent clear images from their degraded versions. Despite the notable achievement, existing methods predominantly focus on handling specific degradation types and thus require specialized models, impeding real-world applications in dynamic degradation scenarios. To address this issue, we propose Large Model Driven Image Restoration framework (LMDIR), a novel multiple-in-one image restoration paradigm that leverages the generic priors from large multi-modal language models (MMLMs) and the pretrained diffusion models. In detail, LMDIR integrates three key prior knowledges: 1) global degradation knowledge from MMLMs, 2) scene-aware contextual descriptions generated by MMLMs, and 3) fine-grained high-quality reference images synthesized by diffusion models guided by MMLM descriptions. Standing on above priors, our architecture comprises a query-based prompt encoder, degradation-aware transformer block injecting global degradation knowledge, content-aware transformer block incorporating scene description, and reference-based transformer block incorporating fine-grained image priors. This design facilitates single-stage training paradigm to address various degradations while supporting both automatic and user-guided restoration. Extensive experiments demonstrate that our designed method outperforms state-of-the-art competitors on multiple evaluation benchmarks.