 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Together: Multi-Robot Cooperative Egocentric Spatial Reasoning with Multimodal Large Language Models
May 19, 2026Multimodal Large Language Models (MLLMs) have made substantial progress in egocentric video understanding, but their ability to reason cooperatively from multiple embodied viewpoints remains largely unexplored. We study this problem through multi-robot cooperative dynamic spatial reasoning, where a model must answer spatial, temporal, visibility, and coordination questions by integrating synchronized egocentric videos from a team of moving robots. To support this setting, we introduce CoopSR, the first benchmark for this task, together with EgoTeam, a multi-robot egocentric QA dataset. EgoTeam contains 114,227 QA pairs spanning 19 question types, four difficulty tiers, and three team sizes in Habitat and iGibson, along with a real-world test set of around 2,326 QAs collected using two quadruped robots. We further propose SP-CoR (Spectral and Physics-Informed Cooperative Reasoner), an MLLM framework for fine-grained cooperative spatial reasoning. SP-CoR combines dynamics-aware multi-robot frame sampling, spectral- and physics-guided view fusion, and physics-aligned prompt distillation, enabling the model to benefit from privileged robot-pose supervision during training while requiring only egocentric videos at test time. Across 22 MLLM baselines, SP-CoR consistently improves cooperative reasoning, outperforming the strongest fine-tuned baseline by +3.87% on Habitat and +7.12% on iGibson. It also shows stronger generalization to unseen team sizes and real-world robot tests. Code can be found at https://github.com/KPeng9510/seeing-together.git.
DriveXQA: Cross-modal Visual Question Answering for Adverse Driving Scene Understanding
Mar 11, 2026Fusing sensors with complementary modalities is crucial for maintaining a stable and comprehensive understanding of abnormal driving scenes. However, Multimodal Large Language Models (MLLMs) are underexplored for leveraging multi-sensor information to understand adverse driving scenarios in autonomous vehicles. To address this gap, we propose the DriveXQA, a multimodal dataset for autonomous driving VQA. In addition to four visual modalities, five sensor failure cases, and five weather conditions, it includes $102,505$ QA pairs categorized into three types: global scene level, allocentric level, and ego-vehicle centric level. Since no existing MLLM framework adopts multiple complementary visual modalities as input, we design MVX-LLM, a token-efficient architecture with a Dual Cross-Attention (DCA) projector that fuses the modalities to alleviate information redundancy. Experiments demonstrate that our DCA achieves improved performance under challenging conditions such as foggy (GPTScore: $53.5$ vs. $25.1$ for the baseline). The established dataset and source code will be made publicly available.
EReLiFM: Evidential Reliability-Aware Residual Flow Meta-Learning for Open-Set Domain Generalization under Noisy Labels
Oct 14, 2025
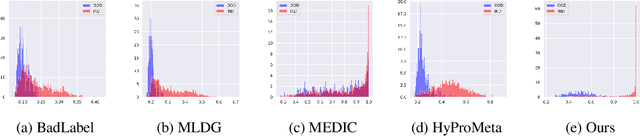


Open-Set Domain Generalization (OSDG) aims to enable deep learning models to recognize unseen categories in new domains, which is crucial for real-world applications. Label noise hinders open-set domain generalization by corrupting source-domain knowledge, making it harder to recognize known classes and reject unseen ones. While existing methods address OSDG under Noisy Labels (OSDG-NL) using hyperbolic prototype-guided meta-learning, they struggle to bridge domain gaps, especially with limited clean labeled data. In this paper, we propose Evidential Reliability-Aware Residual Flow Meta-Learning (EReLiFM). We first introduce an unsupervised two-stage evidential loss clustering method to promote label reliability awareness. Then, we propose a residual flow matching mechanism that models structured domain- and category-conditioned residuals, enabling diverse and uncertainty-aware transfer paths beyond interpolation-based augmentation. During this meta-learning process, the model is optimized such that the update direction on the clean set maximizes the loss decrease on the noisy set, using pseudo labels derived from the most confident predicted class for supervision. Experimental results show that EReLiFM outperforms existing methods on OSDG-NL, achieving state-of-the-art performance. The source code is available at https://github.com/KPeng9510/ERELIFM.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025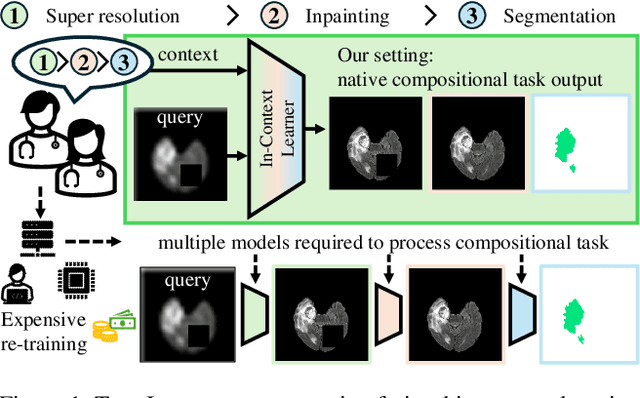
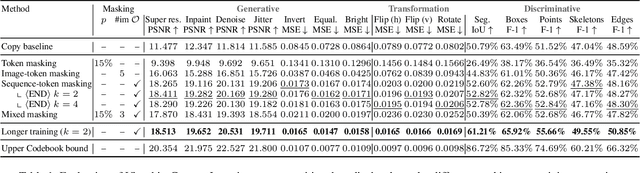
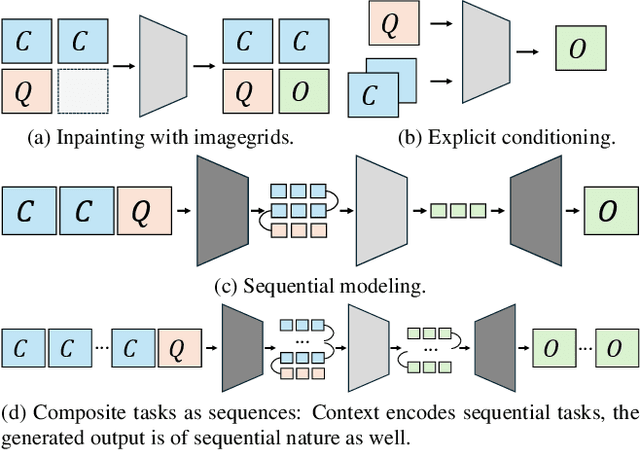
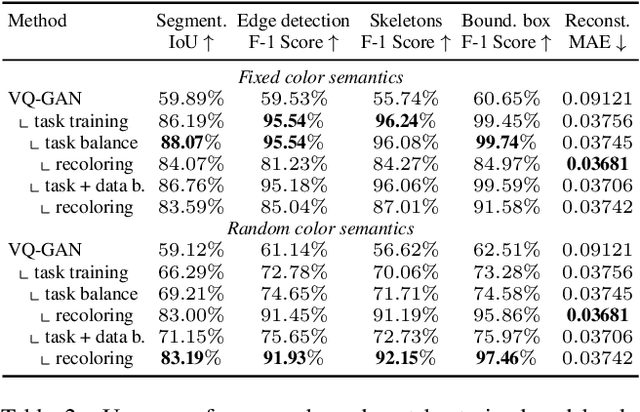
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Position: Pause Recycling LoRAs and Prioritize Mechanisms to Uncover Limits and Effectiveness
Jun 16, 2025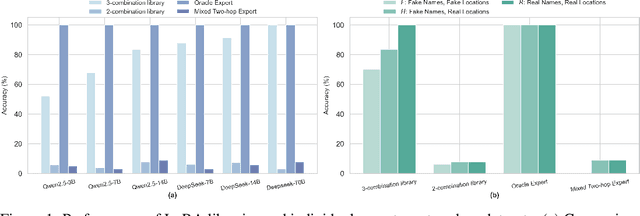



Merging or routing low-rank adapters (LoRAs) has emerged as a popular solution for enhancing large language models, particularly when data access is restricted by regulatory or domain-specific constraints. This position paper argues that the research community should shift its focus from developing new merging or routing algorithms to understanding the conditions under which reusing LoRAs is truly effective. Through theoretical analysis and synthetic two-hop reasoning and math word-problem tasks, we examine whether reusing LoRAs enables genuine compositional generalization or merely reflects shallow pattern matching. Evaluating two data-agnostic methods--parameter averaging and dynamic adapter selection--we found that reusing LoRAs often fails to logically integrate knowledge across disjoint fine-tuning datasets, especially when such knowledge is underrepresented during pretraining. Our empirical results, supported by theoretical insights into LoRA's limited expressiveness, highlight the preconditions and constraints of reusing them for unseen tasks and cast doubt on its feasibility as a truly data-free approach. We advocate for pausing the pursuit of novel methods for recycling LoRAs and emphasize the need for rigorous mechanisms to guide future academic research in adapter-based model merging and practical system designs for practitioners.
Optimizing Small Language Models for In-Vehicle Function-Calling
Jan 04, 2025



We propose a holistic approach for deploying Small Language Models (SLMs) as function-calling agents within vehicles as edge devices, offering a more flexible and robust alternative to traditional rule-based systems. By leveraging SLMs, we simplify vehicle control mechanisms and enhance the user experience. Given the in-vehicle hardware constraints, we apply state-of-the-art model compression techniques, including structured pruning, healing, and quantization, ensuring that the model fits within the resource limitations while maintaining acceptable performance. Our work focuses on optimizing a representative SLM, Microsoft's Phi-3 mini, and outlines best practices for enabling embedded models, including compression, task-specific fine-tuning, and vehicle integration. We demonstrate that, despite significant reduction in model size which removes up to 2 billion parameters from the original model, our approach preserves the model's ability to handle complex in-vehicle tasks accurately and efficiently. Furthermore, by executing the model in a lightweight runtime environment, we achieve a generation speed of 11 tokens per second, making real-time, on-device inference feasible without hardware acceleration. Our results demonstrate the potential of SLMs to transform vehicle control systems, enabling more intuitive interactions between users and their vehicles for an enhanced driving experience.
Muscles in Time: Learning to Understand Human Motion by Simulating Muscle Activations
Oct 31, 2024



Exploring the intricate dynamics between muscular and skeletal structures is pivotal for understanding human motion. This domain presents substantial challenges, primarily attributed to the intensive resources required for acquiring ground truth muscle activation data, resulting in a scarcity of datasets. In this work, we address this issue by establishing Muscles in Time (MinT), a large-scale synthetic muscle activation dataset. For the creation of MinT, we enriched existing motion capture datasets by incorporating muscle activation simulations derived from biomechanical human body models using the OpenSim platform, a common approach in biomechanics and human motion research. Starting from simple pose sequences, our pipeline enables us to extract detailed information about the timing of muscle activations within the human musculoskeletal system. Muscles in Time contains over nine hours of simulation data covering 227 subjects and 402 simulated muscle strands. We demonstrate the utility of this dataset by presenting results on neural network-based muscle activation estimation from human pose sequences with two different sequence-to-sequence architectures. Data and code are provided under https://simplexsigil.github.io/mint.
Advancing Open-Set Domain Generalization Using Evidential Bi-Level Hardest Domain Scheduler
Sep 26, 2024



In Open-Set Domain Generalization (OSDG), the model is exposed to both new variations of data appearance (domains) and open-set conditions, where both known and novel categories are present at test time. The challenges of this task arise from the dual need to generalize across diverse domains and accurately quantify category novelty, which is critical for applications in dynamic environments. Recently, meta-learning techniques have demonstrated superior results in OSDG, effectively orchestrating the meta-train and -test tasks by employing varied random categories and predefined domain partition strategies. These approaches prioritize a well-designed training schedule over traditional methods that focus primarily on data augmentation and the enhancement of discriminative feature learning. The prevailing meta-learning models in OSDG typically utilize a predefined sequential domain scheduler to structure data partitions. However, a crucial aspect that remains inadequately explored is the influence brought by strategies of domain schedulers during training. In this paper, we observe that an adaptive domain scheduler benefits more in OSDG compared with prefixed sequential and random domain schedulers. We propose the Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) to achieve an adaptive domain scheduler. This method strategically sequences domains by assessing their reliabilities in utilizing a follower network, trained with confidence scores learned in an evidential manner, regularized by max rebiasing discrepancy, and optimized in a bi-level manner. The results show that our method substantially improves OSDG performance and achieves more discriminative embeddings for both the seen and unseen categories. The source code will be available at https://github.com/KPeng9510/EBiL-HaDS.
Spacewalker: Traversing Representation Spaces for Fast Interactive Exploration and Annotation of Unstructured Data
Sep 25, 2024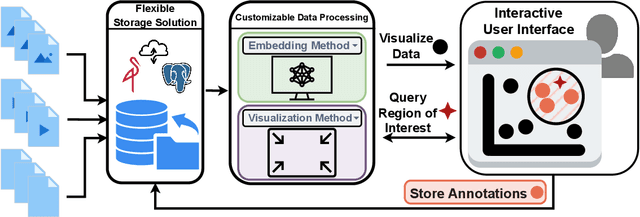
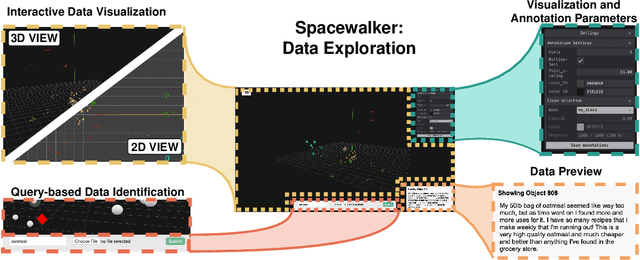

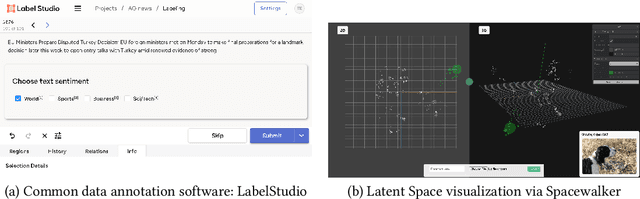
Unstructured data in industries such as healthcare, finance, and manufacturing presents significant challenges for efficient analysis and decision making. Detecting patterns within this data and understanding their impact is critical but complex without the right tools. Traditionally, these tasks relied on the expertise of data analysts or labor-intensive manual reviews. In response, we introduce Spacewalker, an interactive tool designed to explore and annotate data across multiple modalities. Spacewalker allows users to extract data representations and visualize them in low-dimensional spaces, enabling the detection of semantic similarities. Through extensive user studies, we assess Spacewalker's effectiveness in data annotation and integrity verification. Results show that the tool's ability to traverse latent spaces and perform multi-modal queries significantly enhances the user's capacity to quickly identify relevant data. Moreover, Spacewalker allows for annotation speed-ups far superior to conventional methods, making it a promising tool for efficiently navigating unstructured data and improving decision making processes. The code of this work is open-source and can be found at: https://github.com/code-lukas/Spacewalker
Referring Atomic Video Action Recognition
Jul 02, 2024We introduce a new task called Referring Atomic Video Action Recognition (RAVAR), aimed at identifying atomic actions of a particular person based on a textual description and the video data of this person. This task differs from traditional action recognition and localization, where predictions are delivered for all present individuals. In contrast, we focus on recognizing the correct atomic action of a specific individual, guided by text. To explore this task, we present the RefAVA dataset, containing 36,630 instances with manually annotated textual descriptions of the individuals. To establish a strong initial benchmark, we implement and validate baselines from various domains, e.g., atomic action localization, video question answering, and text-video retrieval. Since these existing methods underperform on RAVAR, we introduce RefAtomNet -- a novel cross-stream attention-driven method specialized for the unique challenges of RAVAR: the need to interpret a textual referring expression for the targeted individual, utilize this reference to guide the spatial localization and harvest the prediction of the atomic actions for the referring person. The key ingredients are: (1) a multi-stream architecture that connects video, text, and a new location-semantic stream, and (2) cross-stream agent attention fusion and agent token fusion which amplify the most relevant information across these streams and consistently surpasses standard attention-based fusion on RAVAR. Extensive experiments demonstrate the effectiveness of RefAtomNet and its building blocks for recognizing the action of the described individual. The dataset and code will be made publicly available at https://github.com/KPeng9510/RAVAR.