 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Focused Fine-Tuning of Time Series Foundation Models for Dispatchable Feeder Optimization
Mar 03, 2025Time series foundation models provide a universal solution for generating forecasts to support optimization problems in energy systems. Those foundation models are typically trained in a prediction-focused manner to maximize forecast quality. In contrast, decision-focused learning directly improves the resulting value of the forecast in downstream optimization rather than merely maximizing forecasting quality. The practical integration of forecast values into forecasting models is challenging, particularly when addressing complex applications with diverse instances, such as buildings. This becomes even more complicated when instances possess specific characteristics that require instance-specific, tailored predictions to increase the forecast value. To tackle this challenge, we use decision-focused fine-tuning within time series foundation models to offer a scalable and efficient solution for decision-focused learning applied to the dispatchable feeder optimization problem. To obtain more robust predictions for scarce building data, we use Moirai as a state-of-the-art foundation model, which offers robust and generalized results with few-shot parameter-efficient fine-tuning. Comparing the decision-focused fine-tuned Moirai with a state-of-the-art classical prediction-focused fine-tuning Morai, we observe an improvement of 9.45% in average total daily costs.
Optimizing Small Language Models for In-Vehicle Function-Calling
Jan 04, 2025



We propose a holistic approach for deploying Small Language Models (SLMs) as function-calling agents within vehicles as edge devices, offering a more flexible and robust alternative to traditional rule-based systems. By leveraging SLMs, we simplify vehicle control mechanisms and enhance the user experience. Given the in-vehicle hardware constraints, we apply state-of-the-art model compression techniques, including structured pruning, healing, and quantization, ensuring that the model fits within the resource limitations while maintaining acceptable performance. Our work focuses on optimizing a representative SLM, Microsoft's Phi-3 mini, and outlines best practices for enabling embedded models, including compression, task-specific fine-tuning, and vehicle integration. We demonstrate that, despite significant reduction in model size which removes up to 2 billion parameters from the original model, our approach preserves the model's ability to handle complex in-vehicle tasks accurately and efficiently. Furthermore, by executing the model in a lightweight runtime environment, we achieve a generation speed of 11 tokens per second, making real-time, on-device inference feasible without hardware acceleration. Our results demonstrate the potential of SLMs to transform vehicle control systems, enabling more intuitive interactions between users and their vehicles for an enhanced driving experience.
Generating peak-aware pseudo-measurements for low-voltage feeders using metadata of distribution system operators
Sep 29, 2024


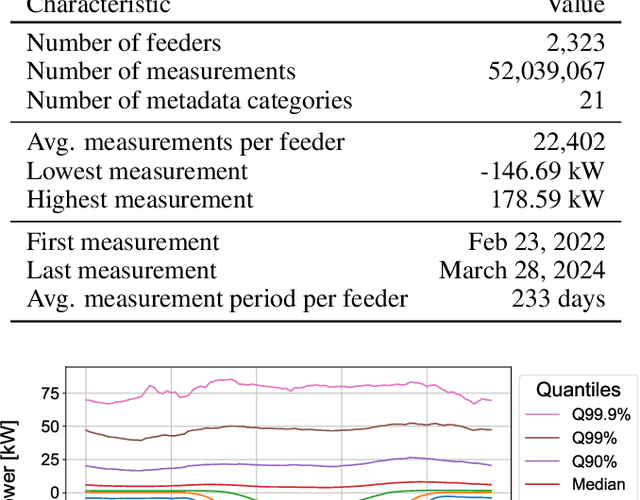
Distribution system operators (DSOs) must cope with new challenges such as the reconstruction of distribution grids along climate neutrality pathways or the ability to manage and control consumption and generation in the grid. In order to meet the challenges, measurements within the distribution grid often form the basis for DSOs. Hence, it is an urgent problem that measurement devices are not installed in many low-voltage (LV) grids. In order to overcome this problem, we present an approach to estimate pseudo-measurements for non-measured LV feeders based on the metadata of the respective feeder using regression models. The feeder metadata comprise information about the number of grid connection points, the installed power of consumers and producers, and billing data in the downstream LV grid. Additionally, we use weather data, calendar data and timestamp information as model features. The existing measurements are used as model target. We extensively evaluate the estimated pseudo-measurements on a large real-world dataset with 2,323 LV feeders characterized by both consumption and feed-in. For this purpose, we introduce peak metrics inspired by the BigDEAL challenge for the peak magnitude, timing and shape for both consumption and feed-in. As regression models, we use XGBoost, a multilayer perceptron (MLP) and a linear regression (LR). We observe that XGBoost and MLP outperform the LR. Furthermore, the results show that the approach adapts to different weather, calendar and timestamp conditions and produces realistic load curves based on the feeder metadata. In the future, the approach can be adapted to other grid levels like substation transformers and can supplement research fields like load modeling, state estimation and LV load forecasting.
Transformer Training Strategies for Forecasting Multiple Load Time Series
Jun 19, 2023Recent work uses Transformers for load forecasting, which are the state of the art for sequence modeling tasks in data-rich domains. In the smart grid of the future, accurate load forecasts must be provided on the level of individual clients of an energy supplier. While the total amount of electrical load data available to an energy supplier will increase with the ongoing smart meter rollout, the amount of data per client will always be limited. We test whether the Transformer benefits from a transfer learning strategy, where a global model is trained on the load time series data from multiple clients. We find that the global model is superior to two other training strategies commonly used in related work: multivariate models and local models. A comparison to linear models and multi-layer perceptrons shows that Transformers are effective for electrical load forecasting when they are trained with the right strategy.
ProbPNN: Enhancing Deep Probabilistic Forecasting with Statistical Information
Feb 06, 2023



Probabilistic forecasts are essential for various downstream applications such as business development, traffic planning, and electrical grid balancing. Many of these probabilistic forecasts are performed on time series data that contain calendar-driven periodicities. However, existing probabilistic forecasting methods do not explicitly take these periodicities into account. Therefore, in the present paper, we introduce a deep learning-based method that considers these calendar-driven periodicities explicitly. The present paper, thus, has a twofold contribution: First, we apply statistical methods that use calendar-driven prior knowledge to create rolling statistics and combine them with neural networks to provide better probabilistic forecasts. Second, we benchmark ProbPNN with state-of-the-art benchmarks by comparing the achieved normalised continuous ranked probability score (nCRPS) and normalised Pinball Loss (nPL) on two data sets containing in total more than 1000 time series. The results of the benchmarks show that using statistical forecasting components improves the probabilistic forecast performance and that ProbPNN outperforms other deep learning forecasting methods whilst requiring less computation costs.
Creating Probabilistic Forecasts from Arbitrary Deterministic Forecasts using Conditional Invertible Neural Networks
Feb 03, 2023



In various applications, probabilistic forecasts are required to quantify the inherent uncertainty associated with the forecast. However, numerous modern forecasting methods are still designed to create deterministic forecasts. Transforming these deterministic forecasts into probabilistic forecasts is often challenging and based on numerous assumptions that may not hold in real-world situations. Therefore, the present article proposes a novel approach for creating probabilistic forecasts from arbitrary deterministic forecasts. In order to implement this approach, we use a conditional Invertible Neural Network (cINN). More specifically, we apply a cINN to learn the underlying distribution of the data and then combine the uncertainty from this distribution with an arbitrary deterministic forecast to generate accurate probabilistic forecasts. Our approach enables the simple creation of probabilistic forecasts without complicated statistical loss functions or further assumptions. Besides showing the mathematical validity of our approach, we empirically show that our approach noticeably outperforms traditional methods for including uncertainty in deterministic forecasts and generally outperforms state-of-the-art probabilistic forecasting benchmarks.
AutoPV: Automated photovoltaic forecasts with limited information using an ensemble of pre-trained models
Dec 13, 2022



Accurate PhotoVoltaic (PV) power generation forecasting is vital for the efficient operation of Smart Grids. The automated design of such accurate forecasting models for individual PV plants includes two challenges: First, information about the PV mounting configuration (i.e. inclination and azimuth angles) is often missing. Second, for new PV plants, the amount of historical data available to train a forecasting model is limited (cold-start problem). We address these two challenges by proposing a new method for day-ahead PV power generation forecasts called AutoPV. AutoPV is a weighted ensemble of forecasting models that represent different PV mounting configurations. This representation is achieved by pre-training each forecasting model on a separate PV plant and by scaling the model's output with the peak power rating of the corresponding PV plant. To tackle the cold-start problem, we initially weight each forecasting model in the ensemble equally. To tackle the problem of missing information about the PV mounting configuration, we use new data that become available during operation to adapt the ensemble weights to minimize the forecasting error. AutoPV is advantageous as the unknown PV mounting configuration is implicitly reflected in the ensemble weights, and only the PV plant's peak power rating is required to re-scale the ensemble's output. AutoPV also allows to represent PV plants with panels distributed on different roofs with varying alignments, as these mounting configurations can be reflected proportionally in the weighting. Additionally, the required computing memory is decoupled when scaling AutoPV to hundreds of PV plants, which is beneficial in Smart Grids with limited computing capabilities. For a real-world data set with 11 PV plants, the accuracy of AutoPV is comparable to a model trained on two years of data and outperforms an incrementally trained model.
Smart Data Representations: Impact on the Accuracy of Deep Neural Networks
Nov 17, 2021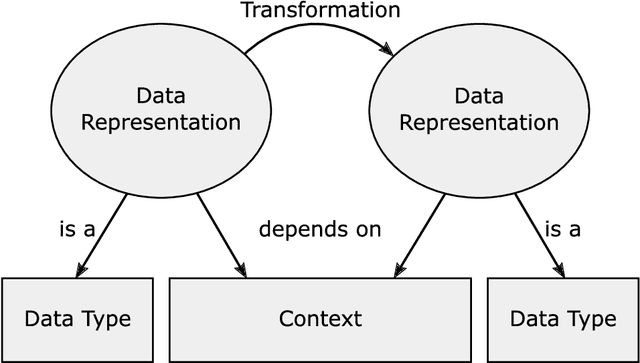


Deep Neural Networks are able to solve many complex tasks with less engineering effort and better performance. However, these networks often use data for training and evaluation without investigating its representation, i.e.~the form of the used data. In the present paper, we analyze the impact of data representations on the performance of Deep Neural Networks using energy time series forecasting. Based on an overview of exemplary data representations, we select four exemplary data representations and evaluate them using two different Deep Neural Network architectures and three forecasting horizons on real-world energy time series. The results show that, depending on the forecast horizon, the same data representations can have a positive or negative impact on the accuracy of Deep Neural Networks.
pyWATTS: Python Workflow Automation Tool for Time Series
Jun 18, 2021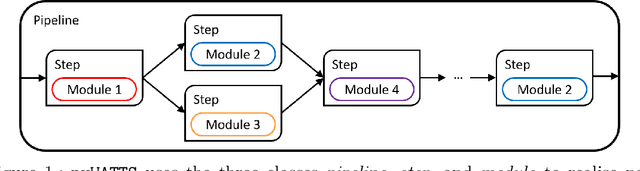
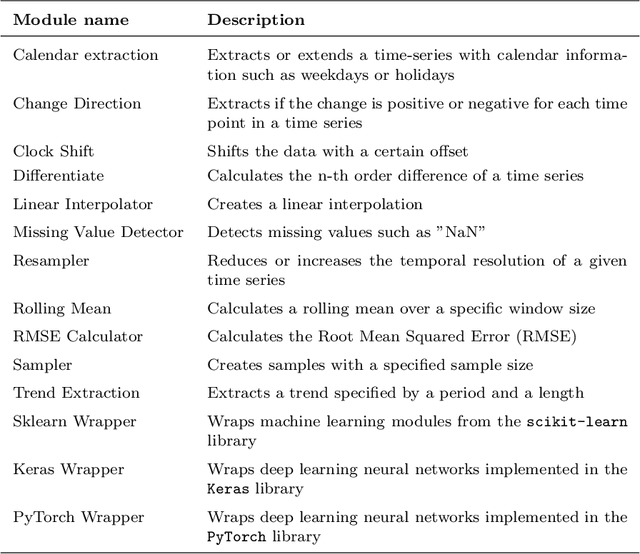
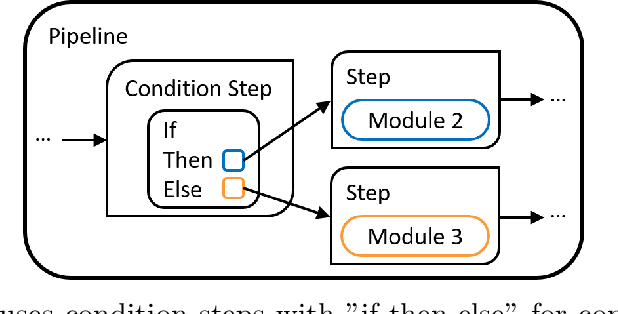
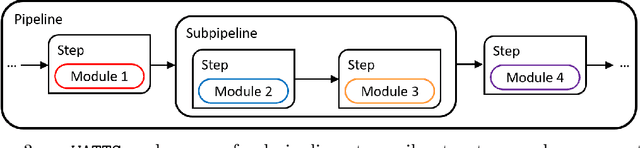
Time series data are fundamental for a variety of applications, ranging from financial markets to energy systems. Due to their importance, the number and complexity of tools and methods used for time series analysis is constantly increasing. However, due to unclear APIs and a lack of documentation, researchers struggle to integrate them into their research projects and replicate results. Additionally, in time series analysis there exist many repetitive tasks, which are often re-implemented for each project, unnecessarily costing time. To solve these problems we present \texttt{pyWATTS}, an open-source Python-based package that is a non-sequential workflow automation tool for the analysis of time series data. pyWATTS includes modules with clearly defined interfaces to enable seamless integration of new or existing methods, subpipelining to easily reproduce repetitive tasks, load and save functionality to simply replicate results, and native support for key Python machine learning libraries such as scikit-learn, PyTorch, and Keras.