 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Small Language Models for In-Vehicle Function-Calling
Jan 04, 2025



We propose a holistic approach for deploying Small Language Models (SLMs) as function-calling agents within vehicles as edge devices, offering a more flexible and robust alternative to traditional rule-based systems. By leveraging SLMs, we simplify vehicle control mechanisms and enhance the user experience. Given the in-vehicle hardware constraints, we apply state-of-the-art model compression techniques, including structured pruning, healing, and quantization, ensuring that the model fits within the resource limitations while maintaining acceptable performance. Our work focuses on optimizing a representative SLM, Microsoft's Phi-3 mini, and outlines best practices for enabling embedded models, including compression, task-specific fine-tuning, and vehicle integration. We demonstrate that, despite significant reduction in model size which removes up to 2 billion parameters from the original model, our approach preserves the model's ability to handle complex in-vehicle tasks accurately and efficiently. Furthermore, by executing the model in a lightweight runtime environment, we achieve a generation speed of 11 tokens per second, making real-time, on-device inference feasible without hardware acceleration. Our results demonstrate the potential of SLMs to transform vehicle control systems, enabling more intuitive interactions between users and their vehicles for an enhanced driving experience.
On the dissection of degenerate cosmologies with machine learning
Oct 25, 2018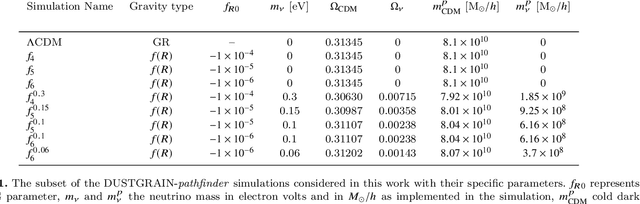
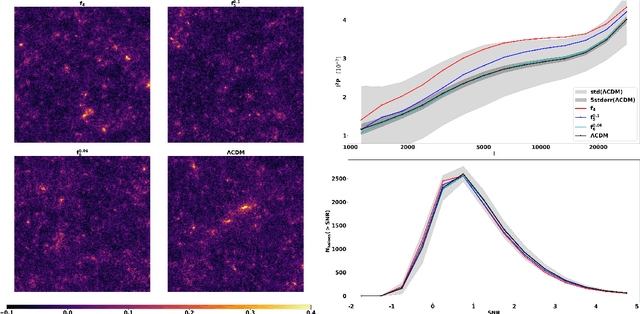

Based on the DUSTGRAIN-pathfinder suite of simulations, we investigate observational degeneracies between nine models of modified gravity and massive neutrinos. Three types of machine learning techniques are tested for their ability to discriminate lensing convergence maps by extracting dimensional reduced representations of the data. Classical map descriptors such as the power spectrum, peak counts and Minkowski functionals are combined into a joint feature vector and compared to the descriptors and statistics that are common to the field of digital image processing. To learn new features directly from the data we use a Convolutional Neural Network (CNN). For the mapping between feature vectors and the predictions of their underlying model, we implement two different classifiers; one based on a nearest-neighbour search and one that is based on a fully connected neural network. We find that the neural network provides a much more robust classification than the nearest-neighbour approach and that the CNN provides the most discriminating representation of the data. It achieves the cleanest separation between the different models and the highest classification success rate of 59% for a single source redshift. Once we perform a tomographic CNN analysis, the total classification accuracy increases significantly to 76% with no observational degeneracies remaining. Visualising the filter responses of the CNN at different network depths provides us with the unique opportunity to learn from very complex models and to understand better why they perform so well.