 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Small Language Models for In-Vehicle Function-Calling
Jan 04, 2025



We propose a holistic approach for deploying Small Language Models (SLMs) as function-calling agents within vehicles as edge devices, offering a more flexible and robust alternative to traditional rule-based systems. By leveraging SLMs, we simplify vehicle control mechanisms and enhance the user experience. Given the in-vehicle hardware constraints, we apply state-of-the-art model compression techniques, including structured pruning, healing, and quantization, ensuring that the model fits within the resource limitations while maintaining acceptable performance. Our work focuses on optimizing a representative SLM, Microsoft's Phi-3 mini, and outlines best practices for enabling embedded models, including compression, task-specific fine-tuning, and vehicle integration. We demonstrate that, despite significant reduction in model size which removes up to 2 billion parameters from the original model, our approach preserves the model's ability to handle complex in-vehicle tasks accurately and efficiently. Furthermore, by executing the model in a lightweight runtime environment, we achieve a generation speed of 11 tokens per second, making real-time, on-device inference feasible without hardware acceleration. Our results demonstrate the potential of SLMs to transform vehicle control systems, enabling more intuitive interactions between users and their vehicles for an enhanced driving experience.
Hierarchical Road Topology Learning for Urban Map-less Driving
Mar 31, 2021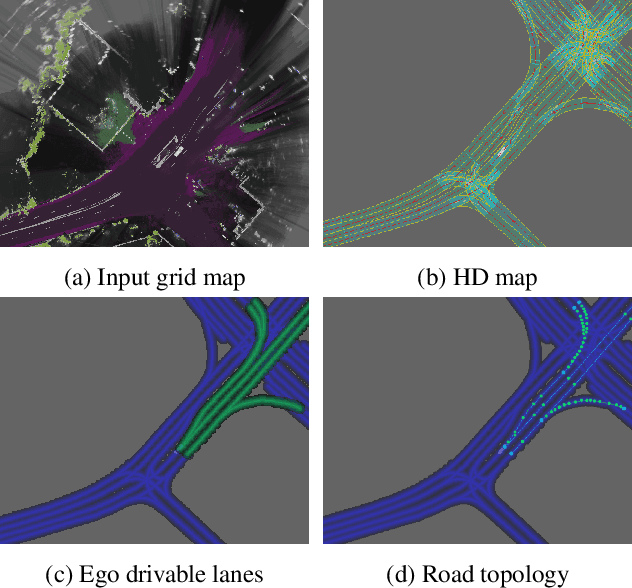

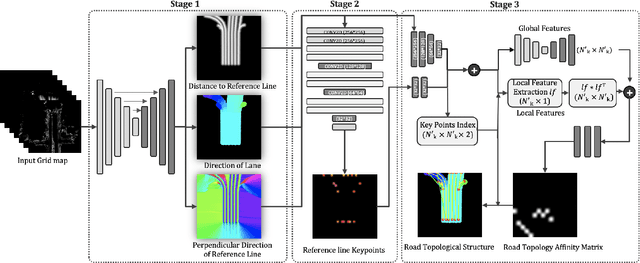

The majority of current approaches in autonomous driving rely on High-Definition (HD) maps which detail the road geometry and surrounding area. Yet, this reliance is one of the obstacles to mass deployment of autonomous vehicles due to poor scalability of such prior maps. In this paper, we tackle the problem of online road map extraction via leveraging the sensory system aboard the vehicle itself. To this end, we design a structured model where a graph representation of the road network is generated in a hierarchical fashion within a fully convolutional network. The method is able to handle complex road topology and does not require a user in the loop.
Holistic Grid Fusion Based Stop Line Estimation
Sep 18, 2020
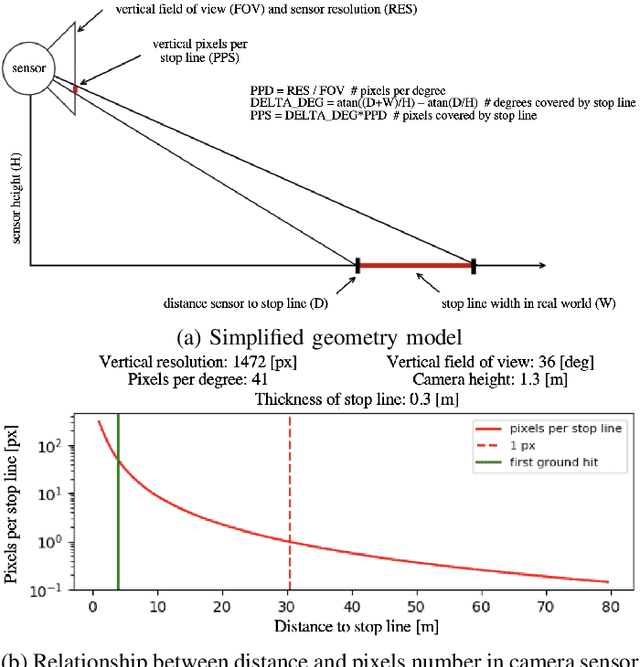
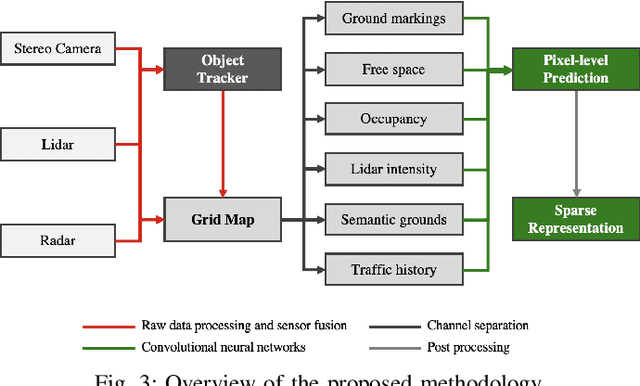

Intersection scenarios provide the most complex traffic situations in Autonomous Driving and Driving Assistance Systems. Knowing where to stop in advance in an intersection is an essential parameter in controlling the longitudinal velocity of the vehicle. Most of the existing methods in literature solely use cameras to detect stop lines, which is typically not sufficient in terms of detection range. To address this issue, we propose a method that takes advantage of fused multi-sensory data including stereo camera and lidar as input and utilizes a carefully designed convolutional neural network architecture to detect stop lines. Our experiments show that the proposed approach can improve detection range compared to camera data alone, works under heavy occlusion without observing the ground markings explicitly, is able to predict stop lines for all lanes and allows detection at a distance up to 50 meters.