 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Road Topology Learning for Urban Map-less Driving
Mar 31, 2021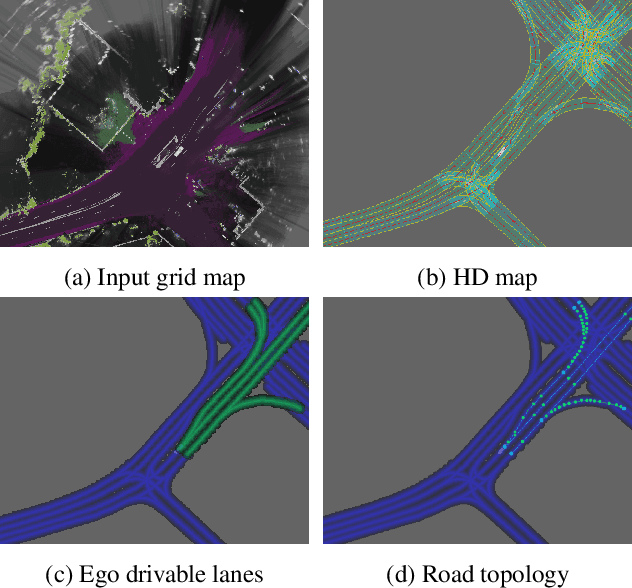

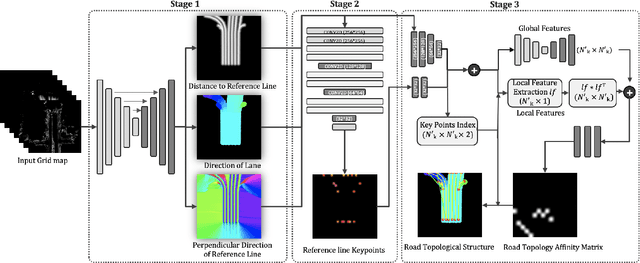

The majority of current approaches in autonomous driving rely on High-Definition (HD) maps which detail the road geometry and surrounding area. Yet, this reliance is one of the obstacles to mass deployment of autonomous vehicles due to poor scalability of such prior maps. In this paper, we tackle the problem of online road map extraction via leveraging the sensory system aboard the vehicle itself. To this end, we design a structured model where a graph representation of the road network is generated in a hierarchical fashion within a fully convolutional network. The method is able to handle complex road topology and does not require a user in the loop.
Holistic Grid Fusion Based Stop Line Estimation
Sep 18, 2020
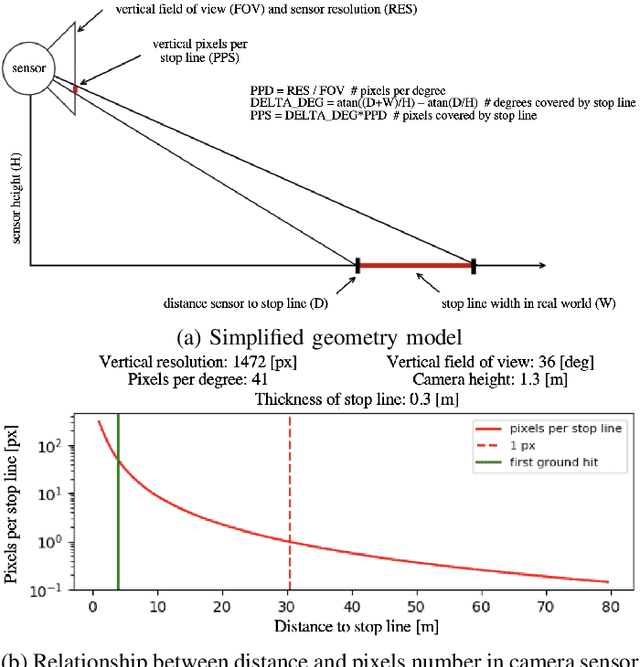
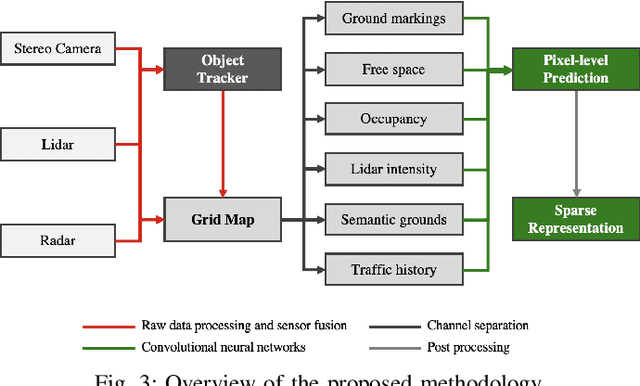

Intersection scenarios provide the most complex traffic situations in Autonomous Driving and Driving Assistance Systems. Knowing where to stop in advance in an intersection is an essential parameter in controlling the longitudinal velocity of the vehicle. Most of the existing methods in literature solely use cameras to detect stop lines, which is typically not sufficient in terms of detection range. To address this issue, we propose a method that takes advantage of fused multi-sensory data including stereo camera and lidar as input and utilizes a carefully designed convolutional neural network architecture to detect stop lines. Our experiments show that the proposed approach can improve detection range compared to camera data alone, works under heavy occlusion without observing the ground markings explicitly, is able to predict stop lines for all lanes and allows detection at a distance up to 50 meters.
Fully Convolutional Neural Networks for Dynamic Object Detection in Grid Maps
Sep 10, 2017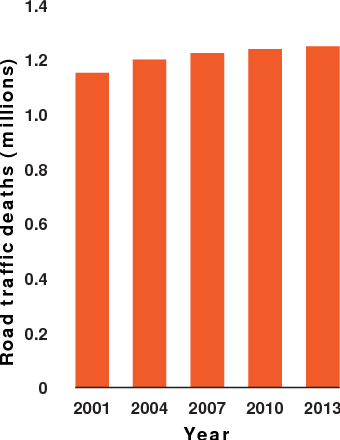
Grid maps are widely used in robotics to represent obstacles in the environment and differentiating dynamic objects from static infrastructure is essential for many practical applications. In this work, we present a methods that uses a deep convolutional neural network (CNN) to infer whether grid cells are covering a moving object or not. Compared to tracking approaches, that use e.g. a particle filter to estimate grid cell velocities and then make a decision for individual grid cells based on this estimate, our approach uses the entire grid map as input image for a CNN that inspects a larger area around each cell and thus takes the structural appearance in the grid map into account to make a decision. Compared to our reference method, our concept yields a performance increase from 83.9% to 97.2%. A runtime optimized version of our approach yields similar improvements with an execution time of just 10 milliseconds.
The Stixel world: A medium-level representation of traffic scenes
Apr 02, 2017

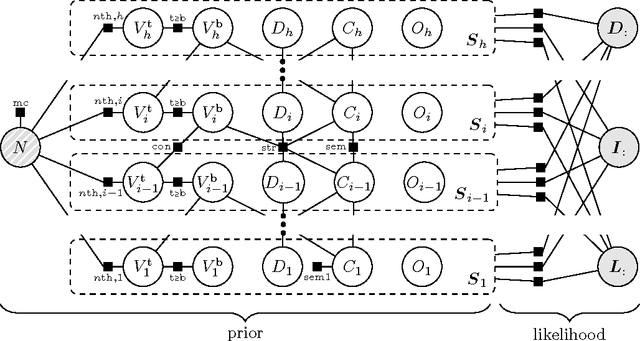

Recent progress in advanced driver assistance systems and the race towards autonomous vehicles is mainly driven by two factors: (1) increasingly sophisticated algorithms that interpret the environment around the vehicle and react accordingly, and (2) the continuous improvements of sensor technology itself. In terms of cameras, these improvements typically include higher spatial resolution, which as a consequence requires more data to be processed. The trend to add multiple cameras to cover the entire surrounding of the vehicle is not conducive in that matter. At the same time, an increasing number of special purpose algorithms need access to the sensor input data to correctly interpret the various complex situations that can occur, particularly in urban traffic. By observing those trends, it becomes clear that a key challenge for vision architectures in intelligent vehicles is to share computational resources. We believe this challenge should be faced by introducing a representation of the sensory data that provides compressed and structured access to all relevant visual content of the scene. The Stixel World discussed in this paper is such a representation. It is a medium-level model of the environment that is specifically designed to compress information about obstacles by leveraging the typical layout of outdoor traffic scenes. It has proven useful for a multitude of automotive vision applications, including object detection, tracking, segmentation, and mapping. In this paper, we summarize the ideas behind the model and generalize it to take into account multiple dense input streams: the image itself, stereo depth maps, and semantic class probability maps that can be generated, e.g., by CNNs. Our generalization is embedded into a novel mathematical formulation for the Stixel model. We further sketch how the free parameters of the model can be learned using structured SVMs.
The Cityscapes Dataset for Semantic Urban Scene Understanding
Apr 07, 2016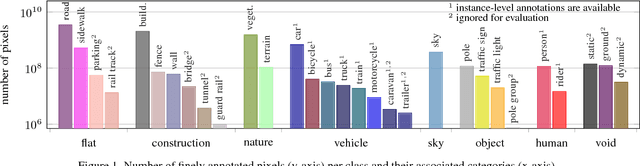

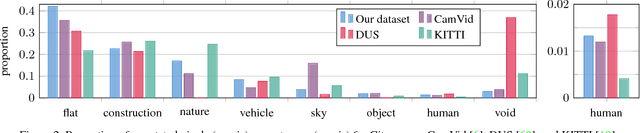
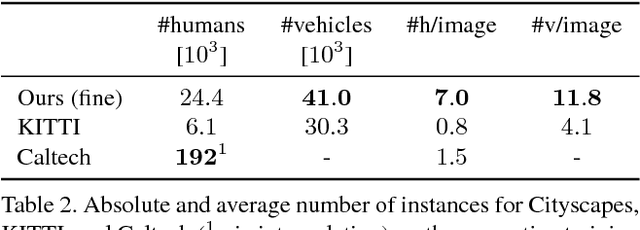
Visual understanding of complex urban street scenes is an enabling factor for a wide range of applications. Object detection has benefited enormously from large-scale datasets, especially in the context of deep learning. For semantic urban scene understanding, however, no current dataset adequately captures the complexity of real-world urban scenes. To address this, we introduce Cityscapes, a benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling. Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities. 5000 of these images have high quality pixel-level annotations; 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data. Crucially, our effort exceeds previous attempts in terms of dataset size, annotation richness, scene variability, and complexity. Our accompanying empirical study provides an in-depth analysis of the dataset characteristics, as well as a performance evaluation of several state-of-the-art approaches based on our benchmark.