 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Insights: Exploiting Structural Similarities for Reliable 3D Semantic Segmentation
Apr 09, 2024
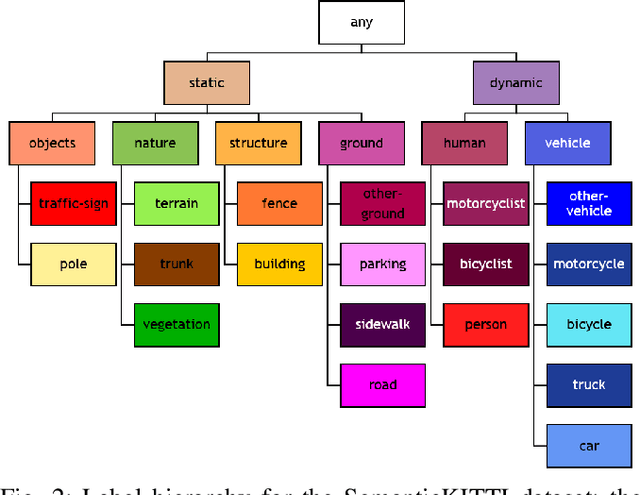
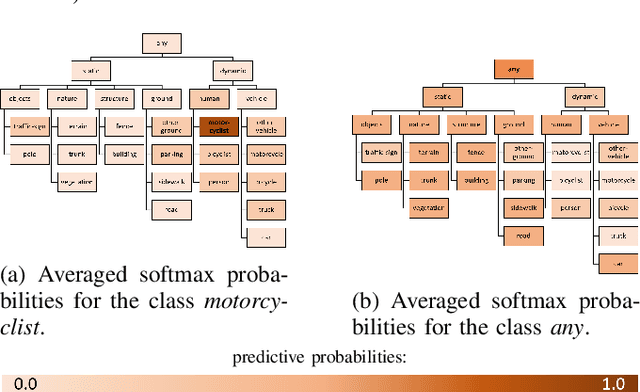

Safety-critical applications like autonomous driving call for robust 3D environment perception algorithms which can withstand highly diverse and ambiguous surroundings. The predictive performance of any classification model strongly depends on the underlying dataset and the prior knowledge conveyed by the annotated labels. While the labels provide a basis for the learning process, they usually fail to represent inherent relations between the classes - representations, which are a natural element of the human perception system. We propose a training strategy which enables a 3D LiDAR semantic segmentation model to learn structural relationships between the different classes through abstraction. We achieve this by implicitly modeling those relationships through a learning rule for hierarchical multi-label classification (HMC). With a detailed analysis we show, how this training strategy not only improves the model's confidence calibration, but also preserves additional information for downstream tasks like fusion, prediction and planning.
On the Calibration of Uncertainty Estimation in LiDAR-based Semantic Segmentation
Aug 04, 2023

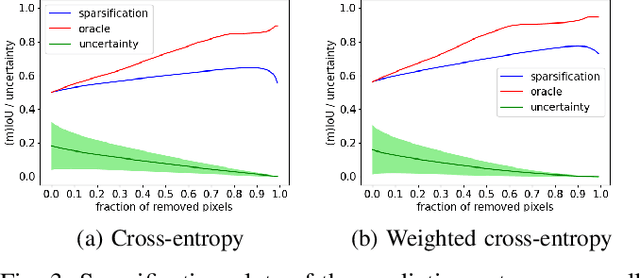

The confidence calibration of deep learning-based perception models plays a crucial role in their reliability. Especially in the context of autonomous driving, downstream tasks like prediction and planning depend on accurate confidence estimates. In point-wise multiclass classification tasks like sematic segmentation the model has to deal with heavy class imbalances. Due to their underrepresentation, the confidence calibration of classes with smaller instances is challenging but essential, not only for safety reasons. We propose a metric to measure the confidence calibration quality of a semantic segmentation model with respect to individual classes. It is calculated by computing sparsification curves for each class based on the uncertainty estimates. We use the classification calibration metric to evaluate uncertainty estimation methods with respect to their confidence calibration of underrepresented classes. We furthermore suggest a double use for the method to automatically find label problems to improve the quality of hand- or auto-annotated datasets.
Survey on LiDAR Perception in Adverse Weather Conditions
Apr 13, 2023
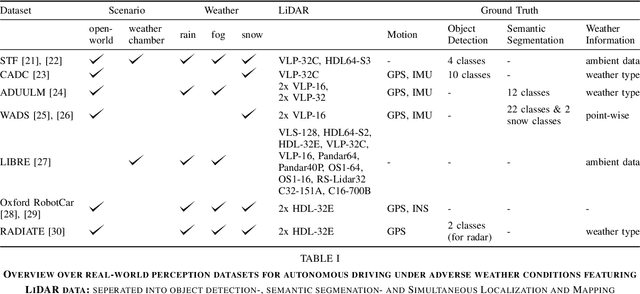
Autonomous vehicles rely on a variety of sensors to gather information about their surrounding. The vehicle's behavior is planned based on the environment perception, making its reliability crucial for safety reasons. The active LiDAR sensor is able to create an accurate 3D representation of a scene, making it a valuable addition for environment perception for autonomous vehicles. Due to light scattering and occlusion, the LiDAR's performance change under adverse weather conditions like fog, snow or rain. This limitation recently fostered a large body of research on approaches to alleviate the decrease in perception performance. In this survey, we gathered, analyzed, and discussed different aspects on dealing with adverse weather conditions in LiDAR-based environment perception. We address topics such as the availability of appropriate data, raw point cloud processing and denoising, robust perception algorithms and sensor fusion to mitigate adverse weather induced shortcomings. We furthermore identify the most pressing gaps in the current literature and pinpoint promising research directions.
On the calibration of underrepresented classes in LiDAR-based semantic segmentation
Oct 13, 2022
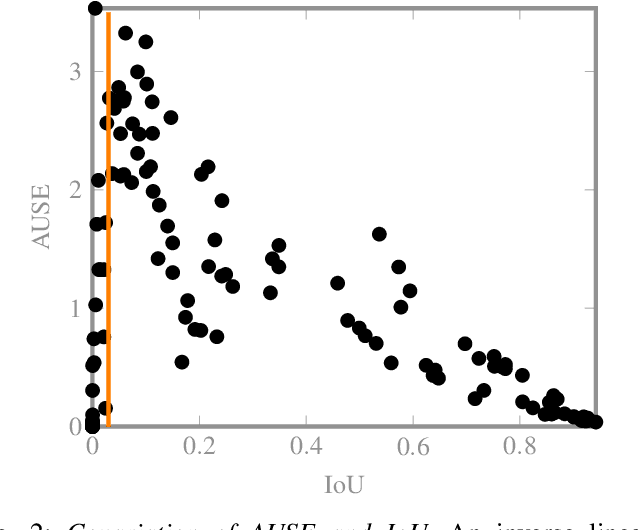
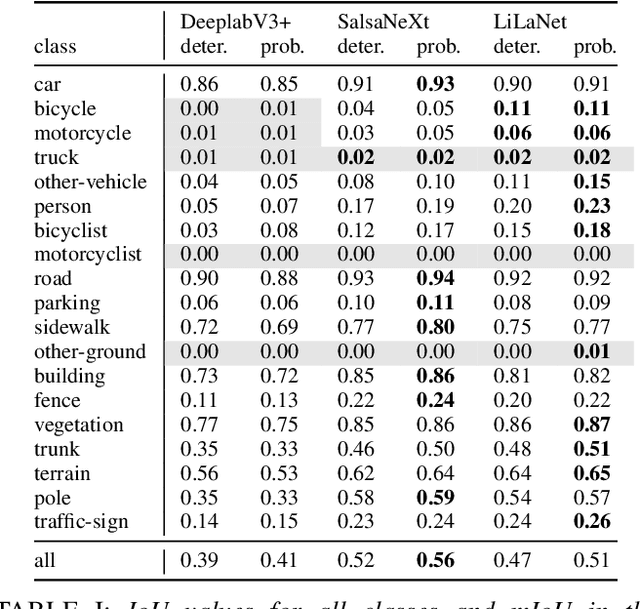
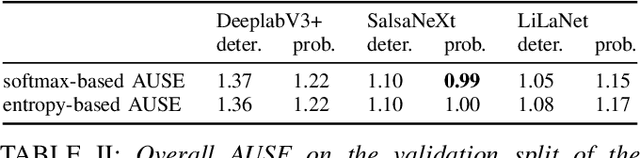
The calibration of deep learning-based perception models plays a crucial role in their reliability. Our work focuses on a class-wise evaluation of several model's confidence performance for LiDAR-based semantic segmentation with the aim of providing insights into the calibration of underrepresented classes. Those classes often include VRUs and are thus of particular interest for safety reasons. With the help of a metric based on sparsification curves we compare the calibration abilities of three semantic segmentation models with different architectural concepts, each in a in deterministic and a probabilistic version. By identifying and describing the dependency between the predictive performance of a class and the respective calibration quality we aim to facilitate the model selection and refinement for safety-critical applications.
CNN-based Lidar Point Cloud De-Noising in Adverse Weather
Dec 09, 2019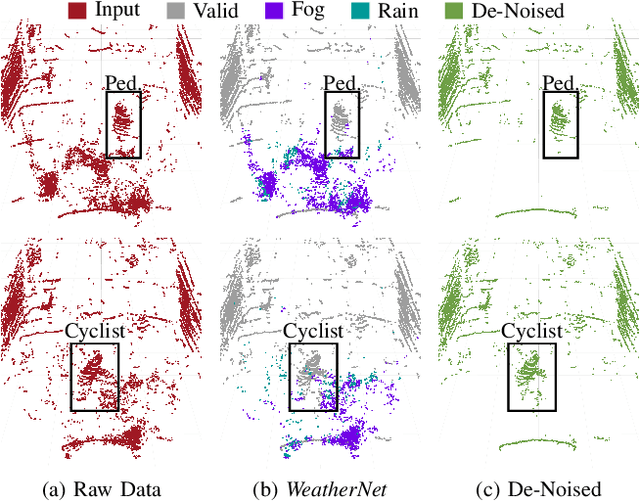

Lidar sensors are frequently used in environment perception for autonomous vehicles and mobile robotics to complement camera, radar, and ultrasonic sensors. Adverse weather conditions are significantly impacting the performance of lidar-based scene understanding by causing undesired measurement points that in turn effect missing detections and false positives. In heavy rain or dense fog, water drops could be misinterpreted as objects in front of the vehicle which brings a mobile robot to a full stop. In this paper, we present the first CNN-based approach to understand and filter out such adverse weather effects in point cloud data. Using a large data set obtained in controlled weather environments, we demonstrate a significant performance improvement of our method over state-of-the-art involving geometric filtering. Data is available at https://github.com/rheinzler/PointCloudDeNoising.
Analyzing the Cross-Sensor Portability of Neural Network Architectures for LiDAR-based Semantic Labeling
Jul 03, 2019


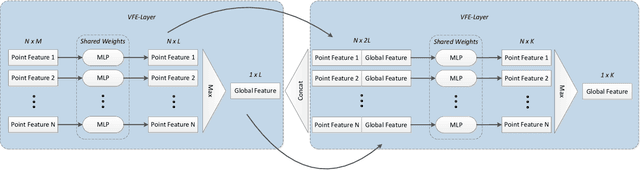
State-of-the-art approaches for the semantic labeling of LiDAR point clouds heavily rely on the use of deep Convolutional Neural Networks (CNNs). However, transferring network architectures across different LiDAR sensor types represents a significant challenge, especially due to sensor specific design choices with regard to network architecture as well as data representation. In this paper we propose a new CNN architecture for the point-wise semantic labeling of LiDAR data which achieves state-of-the-art results while increasing portability across sensor types. This represents a significant advantage given the fast-paced development of LiDAR hardware technology. We perform a thorough quantitative cross-sensor analysis of semantic labeling performance in comparison to a state-of-the-art reference method. Our evaluation shows that the proposed architecture is indeed highly portable, yielding an improvement of 10 percentage points in the Intersection-over-Union (IoU) score when compared to the reference approach. Further, the results indicate that the proposed network architecture can provide an efficient way for the automated generation of large-scale training data for novel LiDAR sensor types without the need for extensive manual annotation or multi-modal label transfer.
Improved Semantic Stixels via Multimodal Sensor Fusion
Sep 27, 2018
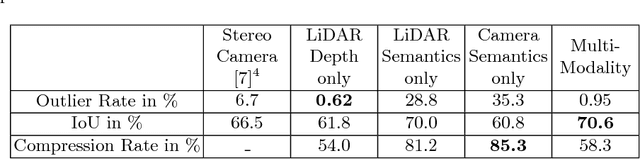
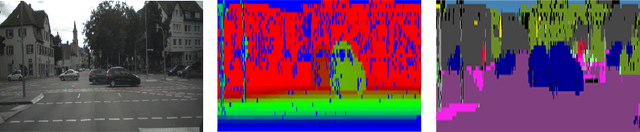
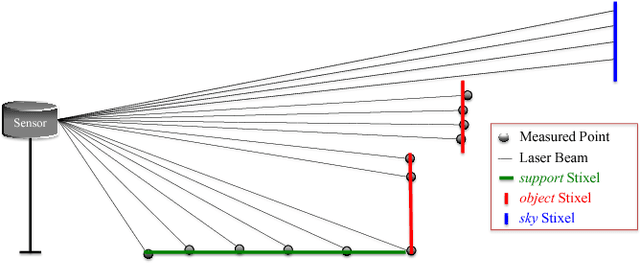
This paper presents a compact and accurate representation of 3D scenes that are observed by a LiDAR sensor and a monocular camera. The proposed method is based on the well-established Stixel model originally developed for stereo vision applications. We extend this Stixel concept to incorporate data from multiple sensor modalities. The resulting mid-level fusion scheme takes full advantage of the geometric accuracy of LiDAR measurements as well as the high resolution and semantic detail of RGB images. The obtained environment model provides a geometrically and semantically consistent representation of the 3D scene at a significantly reduced amount of data while minimizing information loss at the same time. Since the different sensor modalities are considered as input to a joint optimization problem, the solution is obtained with only minor computational overhead. We demonstrate the effectiveness of the proposed multimodal Stixel algorithm on a manually annotated ground truth dataset. Our results indicate that the proposed mid-level fusion of LiDAR and camera data improves both the geometric and semantic accuracy of the Stixel model significantly while reducing the computational overhead as well as the amount of generated data in comparison to using a single modality on its own.
Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation
Apr 26, 2018



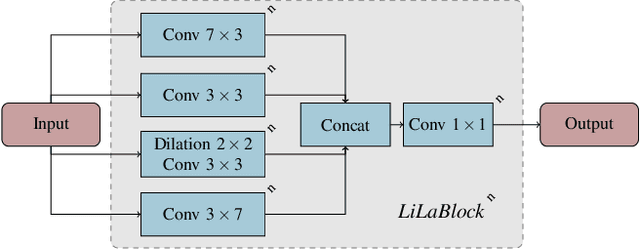
Mobile robots and autonomous vehicles rely on multi-modal sensor setups to perceive and understand their surroundings. Aside from cameras, LiDAR sensors represent a central component of state-of-the-art perception systems. In addition to accurate spatial perception, a comprehensive semantic understanding of the environment is essential for efficient and safe operation. In this paper we present a novel deep neural network architecture called LiLaNet for point-wise, multi-class semantic labeling of semi-dense LiDAR data. The network utilizes virtual image projections of the 3D point clouds for efficient inference. Further, we propose an automated process for large-scale cross-modal training data generation called Autolabeling, in order to boost semantic labeling performance while keeping the manual annotation effort low. The effectiveness of the proposed network architecture as well as the automated data generation process is demonstrated on a manually annotated ground truth dataset. LiLaNet is shown to significantly outperform current state-of-the-art CNN architectures for LiDAR data. Applying our automatically generated large-scale training data yields a boost of up to 14 percentage points compared to networks trained on manually annotated data only.
Fully Convolutional Neural Networks for Dynamic Object Detection in Grid Maps
Sep 10, 2017
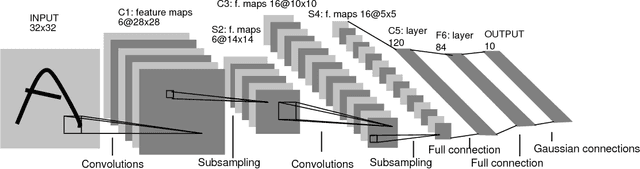
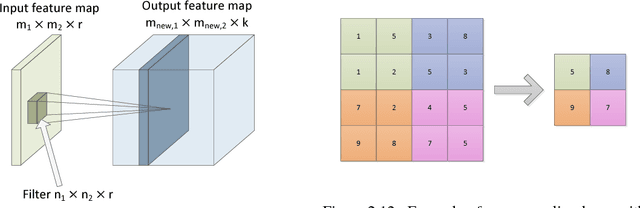
Grid maps are widely used in robotics to represent obstacles in the environment and differentiating dynamic objects from static infrastructure is essential for many practical applications. In this work, we present a methods that uses a deep convolutional neural network (CNN) to infer whether grid cells are covering a moving object or not. Compared to tracking approaches, that use e.g. a particle filter to estimate grid cell velocities and then make a decision for individual grid cells based on this estimate, our approach uses the entire grid map as input image for a CNN that inspects a larger area around each cell and thus takes the structural appearance in the grid map into account to make a decision. Compared to our reference method, our concept yields a performance increase from 83.9% to 97.2%. A runtime optimized version of our approach yields similar improvements with an execution time of just 10 milliseconds.