 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARETE: Attention-based Rasterized Encoding for Topology Estimation using HSV-transformed Crowdsourced Vehicle Fleet Data
Apr 27, 2026The continuous advancement of autonomous driving (AD) introduces challenges across multiple disciplines to ensure safe and efficient driving. One such challenge is the generation of High-Definition (HD) maps, which must remain up to date and highly accurate for downstream automotive tasks. One promising approach is the use of crowdsourced data from a vehicle fleet, representing road topology and lane-level features. This work focuses on the generation of centerlines and lane dividers from crowdsourced vehicle trajectories. We adopt a Detection Transformer (DETR)-based approach, where a rasterized representation of vehicle trajectories is used as input to predict vectorized lane representations. Each lane consists of a centerline with an associated direction and corresponding lane dividers that are geometrically constrained by the centerline. Our method includes the extraction of local tiles, from which crowdsourced vehicle trajectories are aggregated. Each tile undergoes a transformation into a rasterized representation encoding both the presence and direction of each trajectory, enabling the prediction of vectorized directed lanes. Experiments are conducted on an internal dataset as well as on the public datasets nuScenes and nuPlan.
SearchAD: Large-Scale Rare Image Retrieval Dataset for Autonomous Driving
Apr 09, 2026Retrieving rare and safety-critical driving scenarios from large-scale datasets is essential for building robust autonomous driving (AD) systems. As dataset sizes continue to grow, the key challenge shifts from collecting more data to efficiently identifying the most relevant samples. We introduce SearchAD, a large-scale rare image retrieval dataset for AD containing over 423k frames drawn from 11 established datasets. SearchAD provides high-quality manual annotations of more than 513k bounding boxes covering 90 rare categories. It specifically targets the needle-in-a-haystack problem of locating extremely rare classes, with some appearing fewer than 50 times across the entire dataset. Unlike existing benchmarks, which focused on instance-level retrieval, SearchAD emphasizes semantic image retrieval with a well-defined data split, enabling text-to-image and image-to-image retrieval, few-shot learning, and fine-tuning of multi-modal retrieval models. Comprehensive evaluations show that text-based methods outperform image-based ones due to stronger inherent semantic grounding. While models directly aligning spatial visual features with language achieve the best zero-shot results, and our fine-tuning baseline significantly improves performance, absolute retrieval capabilities remain unsatisfactory. With a held-out test set on a public benchmark server, SearchAD establishes the first large-scale dataset for retrieval-driven data curation and long-tail perception research in AD: https://iis-esslingen.github.io/searchad/
Surprised by Attention: Predictable Query Dynamics for Time Series Anomaly Detection
Mar 16, 2026Multivariate time series anomalies often manifest as shifts in cross-channel dependencies rather than simple amplitude excursions. In autonomous driving, for instance, a steering command might be internally consistent but decouple from the resulting lateral acceleration. Residual-based detectors can miss such anomalies when flexible sequence models still reconstruct signals plausibly despite altered coordination. We introduce AxonAD, an unsupervised detector that treats multi-head attention query evolution as a short horizon predictable process. A gradient-updated reconstruction pathway is coupled with a history-only predictor that forecasts future query vectors from past context. This is trained via a masked predictor-target objective against an exponential moving average (EMA) target encoder. At inference, reconstruction error is combined with a tail-aggregated query mismatch score, which measures cosine deviation between predicted and target queries on recent timesteps. This dual approach provides sensitivity to structural dependency shifts while retaining amplitude-level detection. On proprietary in-vehicle telemetry with interval annotations and on the TSB-AD multi-variate suite (17 datasets, 180 series) with threshold-free and range-aware metrics, AxonAD improves ranking quality and temporal localization over strong baselines. Ablations confirm that query prediction and combined scoring are the primary drivers of the observed gains. Code is available at the URL https://github.com/iis-esslingen/AxonAD.
ECoLAD: Deployment-Oriented Evaluation for Automotive Time-Series Anomaly Detection
Mar 11, 2026Time-series anomaly detectors are commonly compared on workstation-class hardware under unconstrained execution. In-vehicle monitoring, however, requires predictable latency and stable behavior under limited CPU parallelism. Accuracy-only leaderboards can therefore misrepresent which methods remain feasible under deployment-relevant constraints. We present ECoLAD (Efficiency Compute Ladder for Anomaly Detection), a deployment-oriented evaluation protocol instantiated as an empirical study on proprietary automotive telemetry (anomaly rate ${\approx}$0.022) and complementary public benchmarks. ECoLAD applies a monotone compute-reduction ladder across heterogeneous detector families using mechanically determined, integer-only scaling rules and explicit CPU thread caps, while logging every applied configuration change. Throughput-constrained behavior is characterized by sweeping target scoring rates and reporting (i) coverage (the fraction of entities meeting the target) and (ii) the best AUC-PR achievable among measured ladder configurations satisfying the target. On constrained automotive telemetry, lightweight classical detectors sustain both coverage and detection lift above the random baseline across the full throughput sweep. Several deep methods lose feasibility before they lose accuracy.
LAD-Drive: Bridging Language and Trajectory with Action-Aware Diffusion Transformers
Mar 02, 2026While multimodal large language models (MLLMs) provide advanced reasoning for autonomous driving, translating their discrete semantic knowledge into continuous trajectories remains a fundamental challenge. Existing methods often rely on unimodal planning heads that inherently limit their ability to represent multimodal driving behavior. Furthermore, most generative approaches frequently condition on one-hot encoded actions, discarding the nuanced navigational uncertainty critical for complex scenarios. To resolve these limitations, we introduce LAD-Drive, a generative framework that structurally disentangles high-level intention from low-level spatial planning. LAD-Drive employs an action decoder to infer a probabilistic meta-action distribution, establishing an explicit belief state that preserves the nuanced intent typically lost by one-hot encodings. This distribution, fused with the vehicle's kinematic state, conditions an action-aware diffusion decoder that utilizes a truncated denoising process to refine learned motion anchors into safe, kinematically feasible trajectories. Extensive evaluations on the LangAuto benchmark demonstrate that LAD-Drive achieves state-of-the-art results, outperforming competitive baselines by up to 59% in Driving Score while significantly reducing route deviations and collisions. We will publicly release the code and models on https://github.com/iis-esslingen/lad-drive.
STREAM-VAE: Dual-Path Routing for Slow and Fast Dynamics in Vehicle Telemetry Anomaly Detection
Nov 19, 2025Automotive telemetry data exhibits slow drifts and fast spikes, often within the same sequence, making reliable anomaly detection challenging. Standard reconstruction-based methods, including sequence variational autoencoders (VAEs), use a single latent process and therefore mix heterogeneous time scales, which can smooth out spikes or inflate variances and weaken anomaly separation. In this paper, we present STREAM-VAE, a variational autoencoder for anomaly detection in automotive telemetry time-series data. Our model uses a dual-path encoder to separate slow drift and fast spike signal dynamics, and a decoder that represents transient deviations separately from the normal operating pattern. STREAM-VAE is designed for deployment, producing stable anomaly scores across operating modes for both in-vehicle monitors and backend fleet analytics. Experiments on an automotive telemetry dataset and the public SMD benchmark show that explicitly separating drift and spike dynamics improves robustness compared to strong forecasting, attention, graph, and VAE baselines.
Enhancing LLM-based Autonomous Driving with Modular Traffic Light and Sign Recognition
Nov 18, 2025Large Language Models (LLMs) are increasingly used for decision-making and planning in autonomous driving, showing promising reasoning capabilities and potential to generalize across diverse traffic situations. However, current LLM-based driving agents lack explicit mechanisms to enforce traffic rules and often struggle to reliably detect small, safety-critical objects such as traffic lights and signs. To address this limitation, we introduce TLS-Assist, a modular redundancy layer that augments LLM-based autonomous driving agents with explicit traffic light and sign recognition. TLS-Assist converts detections into structured natural language messages that are injected into the LLM input, enforcing explicit attention to safety-critical cues. The framework is plug-and-play, model-agnostic, and supports both single-view and multi-view camera setups. We evaluate TLS-Assist in a closed-loop setup on the LangAuto benchmark in CARLA. The results demonstrate relative driving performance improvements of up to 14% over LMDrive and 7% over BEVDriver, while consistently reducing traffic light and sign infractions. We publicly release the code and models on https://github.com/iis-esslingen/TLS-Assist.
GraphPilot: Grounded Scene Graph Conditioning for Language-Based Autonomous Driving
Nov 14, 2025Vision-language models have recently emerged as promising planners for autonomous driving, where success hinges on topology-aware reasoning over spatial structure and dynamic interactions from multimodal input. However, existing models are typically trained without supervision that explicitly encodes these relational dependencies, limiting their ability to infer how agents and other traffic entities influence one another from raw sensor data. In this work, we bridge this gap with a novel model-agnostic method that conditions language-based driving models on structured relational context in the form of traffic scene graphs. We serialize scene graphs at various abstraction levels and formats, and incorporate them into the models via structured prompt templates, enabling a systematic analysis of when and how relational supervision is most beneficial. Extensive evaluations on the public LangAuto benchmark show that scene graph conditioning of state-of-the-art approaches yields large and persistent improvement in driving performance. Notably, we observe up to a 15.6\% increase in driving score for LMDrive and 17.5\% for BEVDriver, indicating that models can better internalize and ground relational priors through scene graph-conditioned training, even without requiring scene graph input at test-time. Code, fine-tuned models, and our scene graph dataset are publicly available at https://github.com/iis-esslingen/GraphPilot.
Integration of Visual SLAM into Consumer-Grade Automotive Localization
Nov 10, 2025

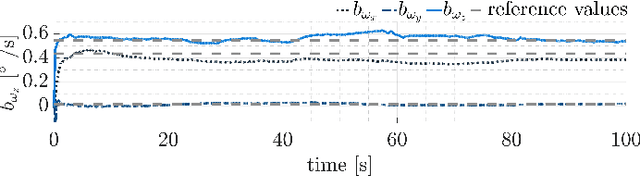
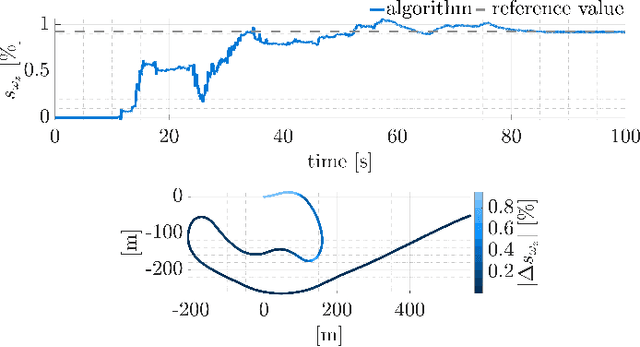
Accurate ego-motion estimation in consumer-grade vehicles currently relies on proprioceptive sensors, i.e. wheel odometry and IMUs, whose performance is limited by systematic errors and calibration. While visual-inertial SLAM has become a standard in robotics, its integration into automotive ego-motion estimation remains largely unexplored. This paper investigates how visual SLAM can be integrated into consumer-grade vehicle localization systems to improve performance. We propose a framework that fuses visual SLAM with a lateral vehicle dynamics model to achieve online gyroscope calibration under realistic driving conditions. Experimental results demonstrate that vision-based integration significantly improves gyroscope calibration accuracy and thus enhances overall localization performance, highlighting a promising path toward higher automotive localization accuracy. We provide results on both proprietary and public datasets, showing improved performance and superior localization accuracy on a public benchmark compared to state-of-the-art methods.
Robust Radar SLAM for Vehicle Parking Applications
Sep 10, 2025We address ego-motion estimation for automated parking, where centimeter-level accuracy is crucial due to tight spaces and nearby obstacles. Traditional methods using inertial-measurement units and wheel encoders require calibration, making them costly and time-consuming. To overcome this, we propose a radar-based simultaneous localization and mapping (SLAM) approach that leverages the robustness of radar to adverse weather and support for online calibration. Our robocentric formulation fuses feature positions and Doppler velocities for robust data association and filter convergence. Key contributions include a Doppler-augmented radar SLAM method, multi-radar support and an information-based feature-pruning strategy. Experiments demonstrate high-accuracy localization and improved robustness over state-of-the-art methods, meeting the demands of automated parking.