 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGO: Adaptive Grounding for Open World 3D Occupancy Prediction
Apr 14, 2025Open-world 3D semantic occupancy prediction aims to generate a voxelized 3D representation from sensor inputs while recognizing both known and unknown objects. Transferring open-vocabulary knowledge from vision-language models (VLMs) offers a promising direction but remains challenging. However, methods based on VLM-derived 2D pseudo-labels with traditional supervision are limited by a predefined label space and lack general prediction capabilities. Direct alignment with pretrained image embeddings, on the other hand, fails to achieve reliable performance due to often inconsistent image and text representations in VLMs. To address these challenges, we propose AGO, a novel 3D occupancy prediction framework with adaptive grounding to handle diverse open-world scenarios. AGO first encodes surrounding images and class prompts into 3D and text embeddings, respectively, leveraging similarity-based grounding training with 3D pseudo-labels. Additionally, a modality adapter maps 3D embeddings into a space aligned with VLM-derived image embeddings, reducing modality gaps. Experiments on Occ3D-nuScenes show that AGO improves unknown object prediction in zero-shot and few-shot transfer while achieving state-of-the-art closed-world self-supervised performance, surpassing prior methods by 4.09 mIoU.
EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners
Nov 12, 2024



To handle the complexities of real-world traffic, learning planners for self-driving from data is a promising direction. While recent approaches have shown great progress, they typically assume a setting in which the ground-truth world state is available as input. However, when deployed, planning needs to be robust to the long-tail of errors incurred by a noisy perception system, which is often neglected in evaluation. To address this, previous work has proposed drawing adversarial samples from a perception error model (PEM) mimicking the noise characteristics of a target object detector. However, these methods use simple PEMs that fail to accurately capture all failure modes of detection. In this paper, we present EMPERROR, a novel transformer-based generative PEM, apply it to stress-test an imitation learning (IL)-based planner and show that it imitates modern detectors more faithfully than previous work. Furthermore, it is able to produce realistic noisy inputs that increase the planner's collision rate by up to 85%, demonstrating its utility as a valuable tool for a more complete evaluation of self-driving planners.
DualAD: Disentangling the Dynamic and Static World for End-to-End Driving
Jun 10, 2024State-of-the-art approaches for autonomous driving integrate multiple sub-tasks of the overall driving task into a single pipeline that can be trained in an end-to-end fashion by passing latent representations between the different modules. In contrast to previous approaches that rely on a unified grid to represent the belief state of the scene, we propose dedicated representations to disentangle dynamic agents and static scene elements. This allows us to explicitly compensate for the effect of both ego and object motion between consecutive time steps and to flexibly propagate the belief state through time. Furthermore, dynamic objects can not only attend to the input camera images, but also directly benefit from the inferred static scene structure via a novel dynamic-static cross-attention. Extensive experiments on the challenging nuScenes benchmark demonstrate the benefits of the proposed dual-stream design, especially for modelling highly dynamic agents in the scene, and highlight the improved temporal consistency of our approach. Our method titled DualAD not only outperforms independently trained single-task networks, but also improves over previous state-of-the-art end-to-end models by a large margin on all tasks along the functional chain of driving.
S.T.A.R.-Track: Latent Motion Models for End-to-End 3D Object Tracking with Adaptive Spatio-Temporal Appearance Representations
Jun 30, 2023


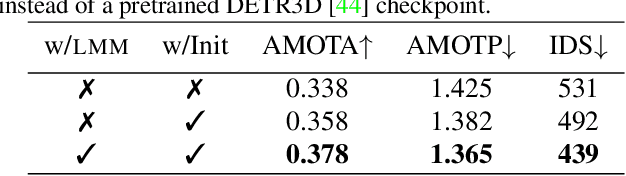
Following the tracking-by-attention paradigm, this paper introduces an object-centric, transformer-based framework for tracking in 3D. Traditional model-based tracking approaches incorporate the geometric effect of object- and ego motion between frames with a geometric motion model. Inspired by this, we propose S.T.A.R.-Track, which uses a novel latent motion model (LMM) to additionally adjust object queries to account for changes in viewing direction and lighting conditions directly in the latent space, while still modeling the geometric motion explicitly. Combined with a novel learnable track embedding that aids in modeling the existence probability of tracks, this results in a generic tracking framework that can be integrated with any query-based detector. Extensive experiments on the nuScenes benchmark demonstrate the benefits of our approach, showing state-of-the-art performance for DETR3D-based trackers while drastically reducing the number of identity switches of tracks at the same time.
PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird's-Eye View
Jun 19, 2023Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: https://github.com/EdwardLeeLPZ/PowerBEV.
KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients
Apr 28, 2022

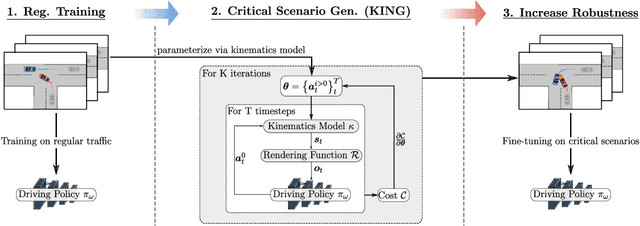
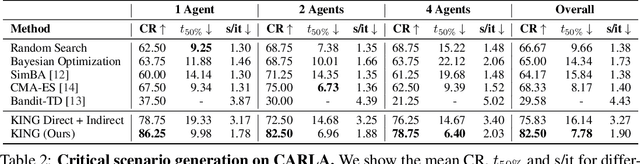
Simulators offer the possibility of safe, low-cost development of self-driving systems. However, current driving simulators exhibit na\"ive behavior models for background traffic. Hand-tuned scenarios are typically added during simulation to induce safety-critical situations. An alternative approach is to adversarially perturb the background traffic trajectories. In this paper, we study this approach to safety-critical driving scenario generation using the CARLA simulator. We use a kinematic bicycle model as a proxy to the simulator's true dynamics and observe that gradients through this proxy model are sufficient for optimizing the background traffic trajectories. Based on this finding, we propose KING, which generates safety-critical driving scenarios with a 20% higher success rate than black-box optimization. By solving the scenarios generated by KING using a privileged rule-based expert algorithm, we obtain training data for an imitation learning policy. After fine-tuning on this new data, we show that the policy becomes better at avoiding collisions. Importantly, our generated data leads to reduced collisions on both held-out scenarios generated via KING as well as traditional hand-crafted scenarios, demonstrating improved robustness.
Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
Jul 09, 2021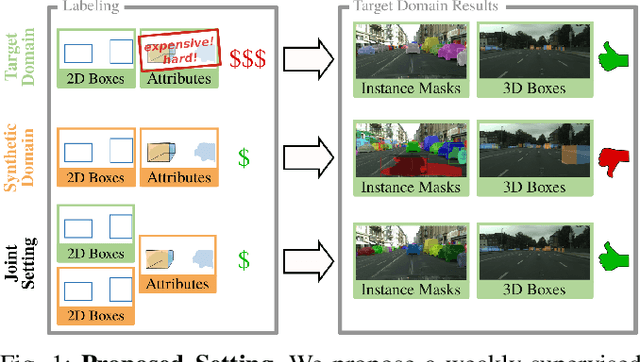
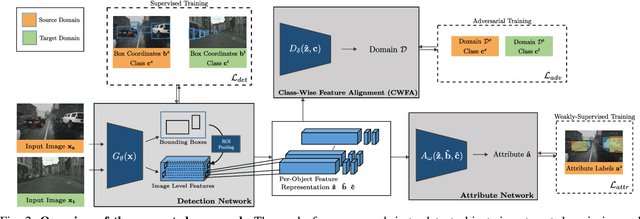


In order to handle the challenges of autonomous driving, deep learning has proven to be crucial in tackling increasingly complex tasks, such as 3D detection or instance segmentation. State-of-the-art approaches for image-based detection tasks tackle this complexity by operating in a cascaded fashion: they first extract a 2D bounding box based on which additional attributes, e.g. instance masks, are inferred. While these methods perform well, a key challenge remains the lack of accurate and cheap annotations for the growing variety of tasks. Synthetic data presents a promising solution but, despite the effort in domain adaptation research, the gap between synthetic and real data remains an open problem. In this work, we propose a weakly supervised domain adaptation setting which exploits the structure of cascaded detection tasks. In particular, we learn to infer the attributes solely from the source domain while leveraging 2D bounding boxes as weak labels in both domains to explain the domain shift. We further encourage domain-invariant features through class-wise feature alignment using ground-truth class information, which is not available in the unsupervised setting. As our experiments demonstrate, the approach is competitive with fully supervised settings while outperforming unsupervised adaptation approaches by a large margin.
Visibility Guided NMS: Efficient Boosting of Amodal Object Detection in Crowded Traffic Scenes
Jun 15, 2020
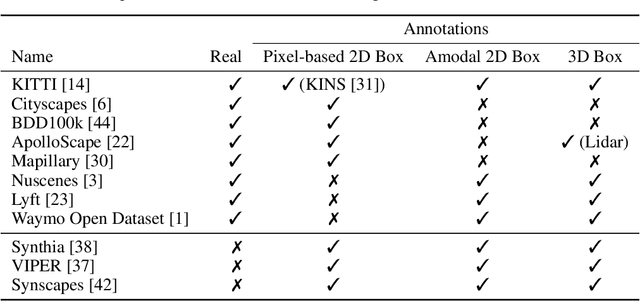
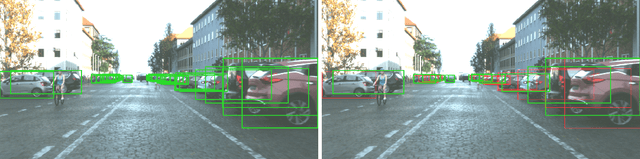

Object detection is an important task in environment perception for autonomous driving. Modern 2D object detection frameworks such as Yolo, SSD or Faster R-CNN predict multiple bounding boxes per object that are refined using Non-Maximum-Suppression (NMS) to suppress all but one bounding box. While object detection itself is fully end-to-end learnable and does not require any manual parameter selection, standard NMS is parametrized by an overlap threshold that has to be chosen by hand. In practice, this often leads to an inability of standard NMS strategies to distinguish different objects in crowded scenes in the presence of high mutual occlusion, e.g. for parked cars or crowds of pedestrians. Our novel Visibility Guided NMS (vg-NMS) leverages both pixel-based as well as amodal object detection paradigms and improves the detection performance especially for highly occluded objects with little computational overhead. We evaluate vg-NMS using KITTI, VIPER as well as the Synscapes dataset and show that it outperforms current state-of-the-art NMS.