 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Object-Level Monocular Depth Estimation for UAVs
Feb 17, 2023Computer vision-based object detection is a key modality for advanced Detect-And-Avoid systems that allow for autonomous flight missions of UAVs. While standard object detection frameworks do not predict the actual depth of an object, this information is crucial to avoid collisions. In this paper, we propose several novel extensions to state-of-the-art methods for monocular object detection from images at long range. Firstly, we propose Sigmoid and ReLU-like encodings when modeling depth estimation as a regression task. Secondly, we frame the depth estimation as a classification problem and introduce a Soft-Argmax function in the calculation of the training loss. The extensions are exemplarily applied to the YOLOX object detection framework. We evaluate the performance using the Amazon Airborne Object Tracking dataset. In addition, we introduce the Fitness score as a new metric that jointly assesses both object detection and depth estimation performance. Our results show that the proposed methods outperform state-of-the-art approaches w.r.t. existing, as well as the proposed metrics.
Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometry Constrained Keypoints in Real-Time
Jun 23, 2020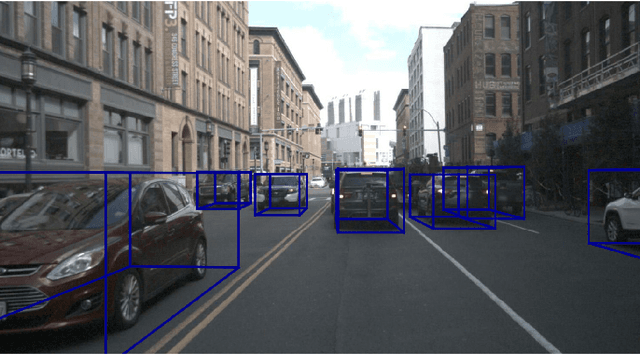
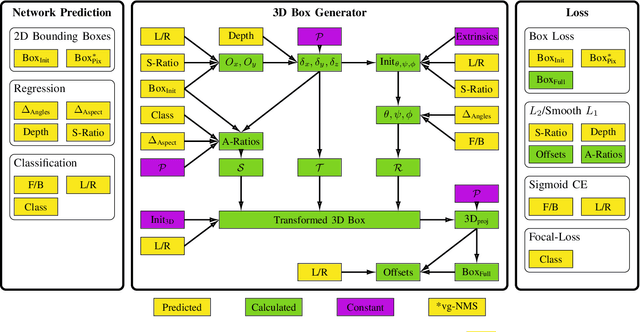
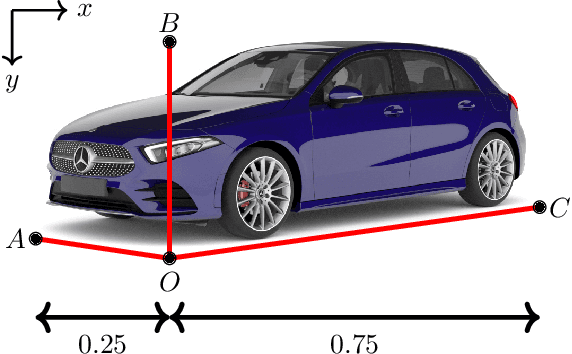

In this paper we propose a novel 3D single-shot object detection method for detecting vehicles in monocular RGB images. Our approach lifts 2D detections to 3D space by predicting additional regression and classification parameters and hence keeping the runtime close to pure 2D object detection. The additional parameters are transformed to 3D bounding box keypoints within the network under geometric constraints. Our proposed method features a full 3D description including all three angles of rotation without supervision by any labeled ground truth data for the object's orientation, as it focuses on certain keypoints within the image plane. While our approach can be combined with any modern object detection framework with only little computational overhead, we exemplify the extension of SSD for the prediction of 3D bounding boxes. We test our approach on different datasets for autonomous driving and evaluate it using the challenging KITTI 3D Object Detection as well as the novel nuScenes Object Detection benchmarks. While we achieve competitive results on both benchmarks we outperform current state-of-the-art methods in terms of speed with more than 20 FPS for all tested datasets and image resolutions.
Visibility Guided NMS: Efficient Boosting of Amodal Object Detection in Crowded Traffic Scenes
Jun 15, 2020
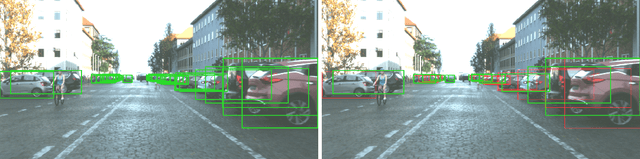

Object detection is an important task in environment perception for autonomous driving. Modern 2D object detection frameworks such as Yolo, SSD or Faster R-CNN predict multiple bounding boxes per object that are refined using Non-Maximum-Suppression (NMS) to suppress all but one bounding box. While object detection itself is fully end-to-end learnable and does not require any manual parameter selection, standard NMS is parametrized by an overlap threshold that has to be chosen by hand. In practice, this often leads to an inability of standard NMS strategies to distinguish different objects in crowded scenes in the presence of high mutual occlusion, e.g. for parked cars or crowds of pedestrians. Our novel Visibility Guided NMS (vg-NMS) leverages both pixel-based as well as amodal object detection paradigms and improves the detection performance especially for highly occluded objects with little computational overhead. We evaluate vg-NMS using KITTI, VIPER as well as the Synscapes dataset and show that it outperforms current state-of-the-art NMS.
Cityscapes 3D: Dataset and Benchmark for 9 DoF Vehicle Detection
Jun 14, 2020
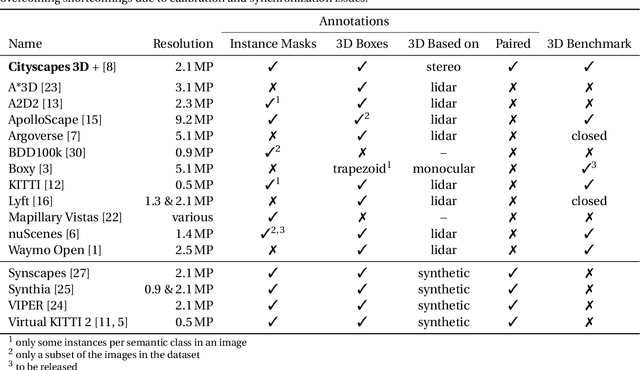
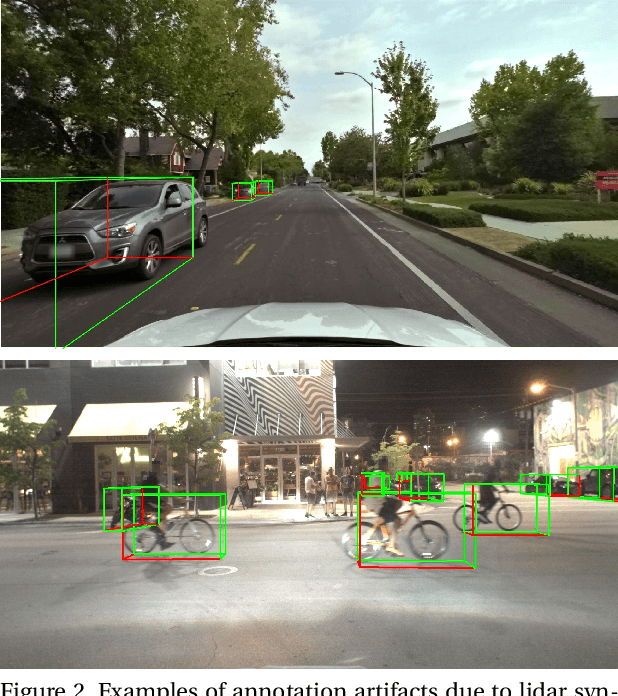
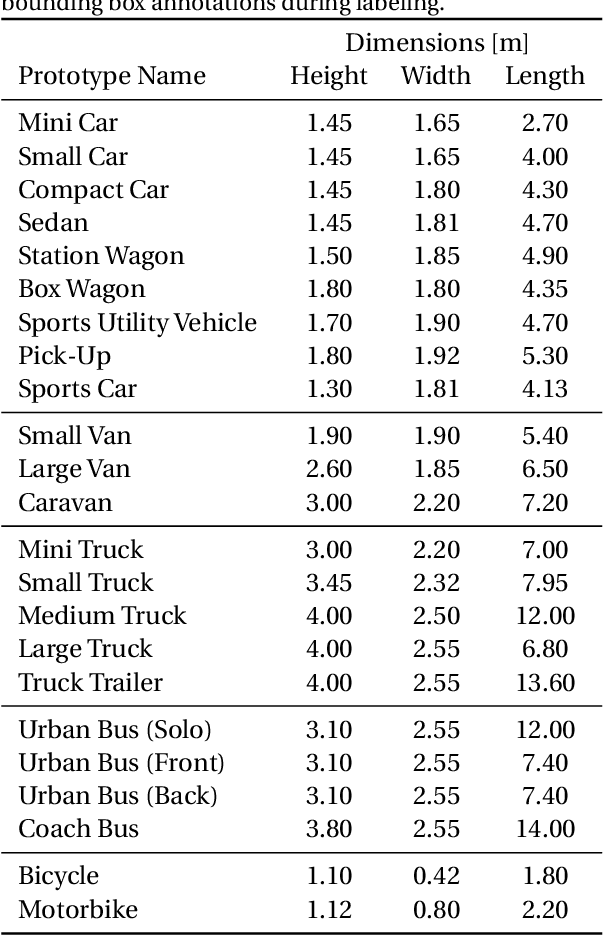
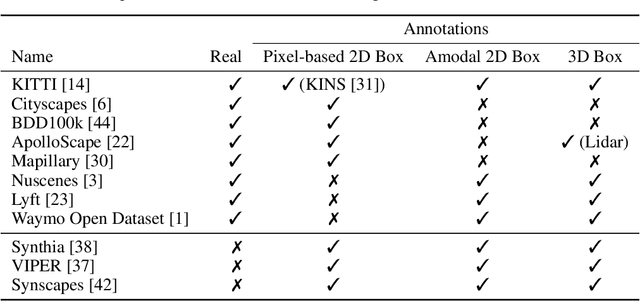
Detecting vehicles and representing their position and orientation in the three dimensional space is a key technology for autonomous driving. Recently, methods for 3D vehicle detection solely based on monocular RGB images gained popularity. In order to facilitate this task as well as to compare and drive state-of-the-art methods, several new datasets and benchmarks have been published. Ground truth annotations of vehicles are usually obtained using lidar point clouds, which often induces errors due to imperfect calibration or synchronization between both sensors. To this end, we propose Cityscapes 3D, extending the original Cityscapes dataset with 3D bounding box annotations for all types of vehicles. In contrast to existing datasets, our 3D annotations were labeled using stereo RGB images only and capture all nine degrees of freedom. This leads to a pixel-accurate reprojection in the RGB image and a higher range of annotations compared to lidar-based approaches. In order to ease multitask learning, we provide a pairing of 2D instance segments with 3D bounding boxes. In addition, we complement the Cityscapes benchmark suite with 3D vehicle detection based on the new annotations as well as metrics presented in this work. Dataset and benchmark are available online.