 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stixel-based Instance Segmentation
Jul 07, 2021Stixels have been successfully applied to a wide range of vision tasks in autonomous driving, recently including instance segmentation. However, due to their sparse occurrence in the image, until now Stixels seldomly served as input for Deep Learning algorithms, restricting their utility for such approaches. In this work we present StixelPointNet, a novel method to perform fast instance segmentation directly on Stixels. By regarding the Stixel representation as unstructured data similar to point clouds, architectures like PointNet are able to learn features from Stixels. We use a bounding box detector to propose candidate instances, for which the relevant Stixels are extracted from the input image. On these Stixels, a PointNet models learns binary segmentations, which we then unify throughout the whole image in a final selection step. StixelPointNet achieves state-of-the-art performance on Stixel-level, is considerably faster than pixel-based segmentation methods, and shows that with our approach the Stixel domain can be introduced to many new 3D Deep Learning tasks.
Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometry Constrained Keypoints in Real-Time
Jun 23, 2020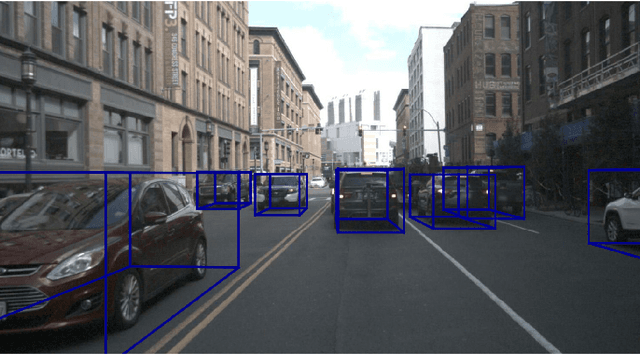
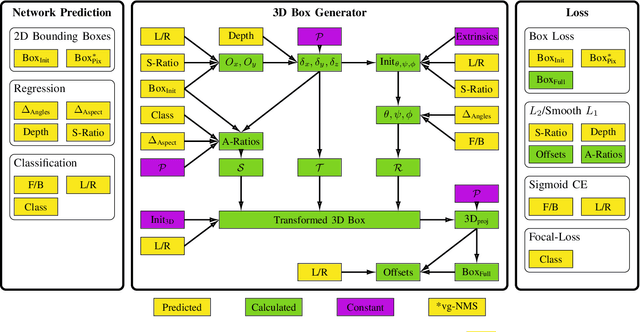
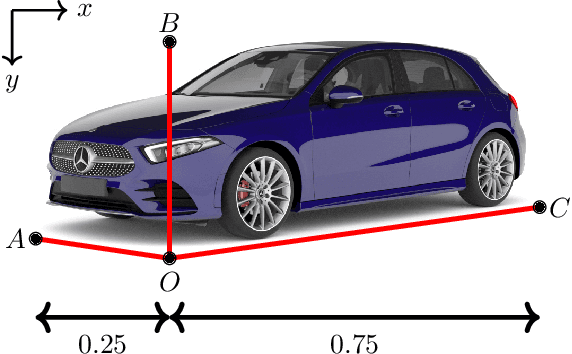

In this paper we propose a novel 3D single-shot object detection method for detecting vehicles in monocular RGB images. Our approach lifts 2D detections to 3D space by predicting additional regression and classification parameters and hence keeping the runtime close to pure 2D object detection. The additional parameters are transformed to 3D bounding box keypoints within the network under geometric constraints. Our proposed method features a full 3D description including all three angles of rotation without supervision by any labeled ground truth data for the object's orientation, as it focuses on certain keypoints within the image plane. While our approach can be combined with any modern object detection framework with only little computational overhead, we exemplify the extension of SSD for the prediction of 3D bounding boxes. We test our approach on different datasets for autonomous driving and evaluate it using the challenging KITTI 3D Object Detection as well as the novel nuScenes Object Detection benchmarks. While we achieve competitive results on both benchmarks we outperform current state-of-the-art methods in terms of speed with more than 20 FPS for all tested datasets and image resolutions.
Visibility Guided NMS: Efficient Boosting of Amodal Object Detection in Crowded Traffic Scenes
Jun 15, 2020
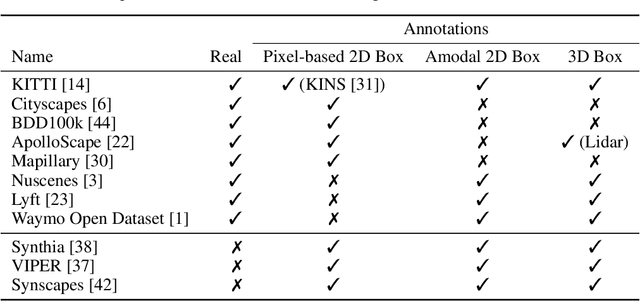
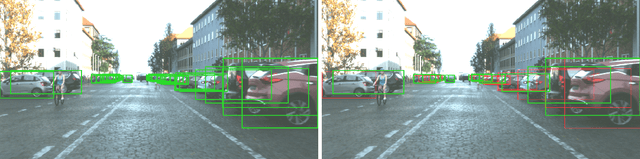

Object detection is an important task in environment perception for autonomous driving. Modern 2D object detection frameworks such as Yolo, SSD or Faster R-CNN predict multiple bounding boxes per object that are refined using Non-Maximum-Suppression (NMS) to suppress all but one bounding box. While object detection itself is fully end-to-end learnable and does not require any manual parameter selection, standard NMS is parametrized by an overlap threshold that has to be chosen by hand. In practice, this often leads to an inability of standard NMS strategies to distinguish different objects in crowded scenes in the presence of high mutual occlusion, e.g. for parked cars or crowds of pedestrians. Our novel Visibility Guided NMS (vg-NMS) leverages both pixel-based as well as amodal object detection paradigms and improves the detection performance especially for highly occluded objects with little computational overhead. We evaluate vg-NMS using KITTI, VIPER as well as the Synscapes dataset and show that it outperforms current state-of-the-art NMS.
Cityscapes 3D: Dataset and Benchmark for 9 DoF Vehicle Detection
Jun 14, 2020
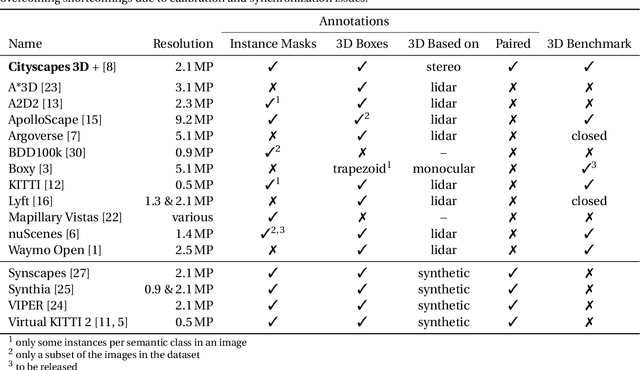
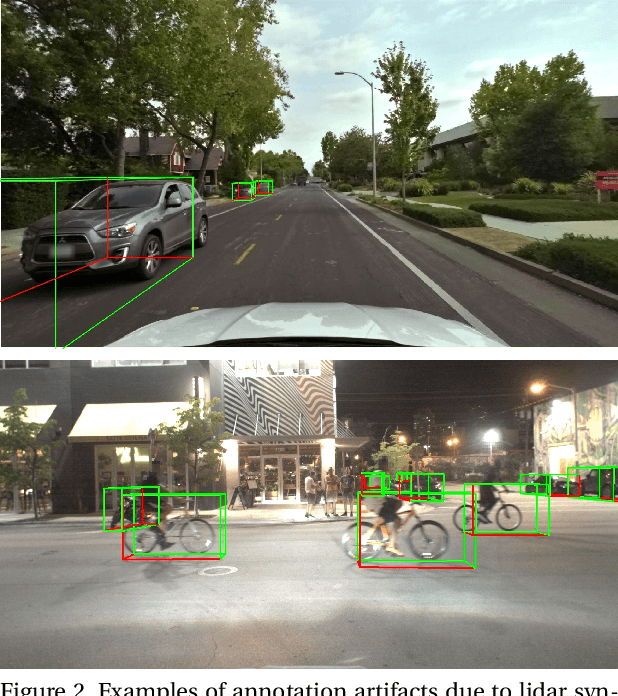
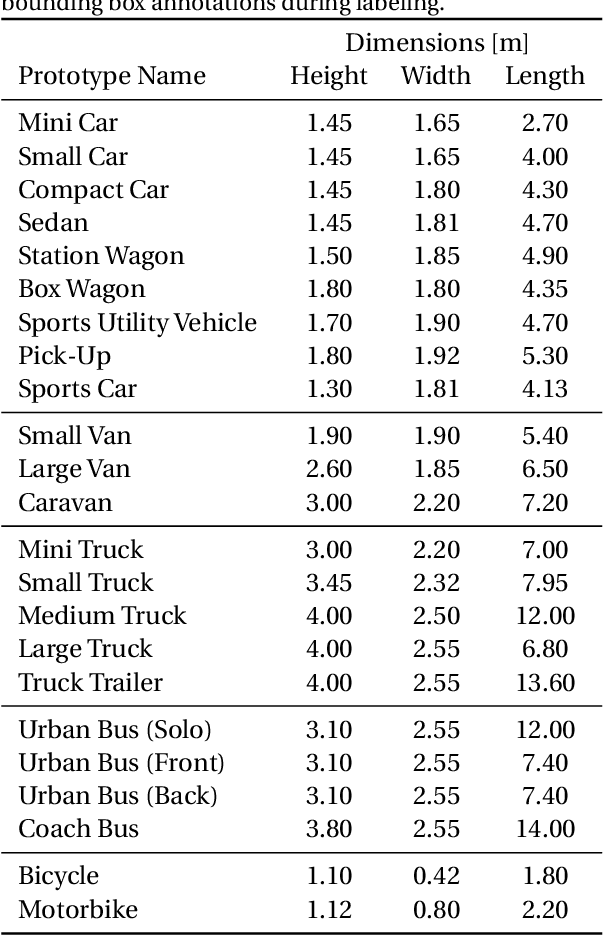
Detecting vehicles and representing their position and orientation in the three dimensional space is a key technology for autonomous driving. Recently, methods for 3D vehicle detection solely based on monocular RGB images gained popularity. In order to facilitate this task as well as to compare and drive state-of-the-art methods, several new datasets and benchmarks have been published. Ground truth annotations of vehicles are usually obtained using lidar point clouds, which often induces errors due to imperfect calibration or synchronization between both sensors. To this end, we propose Cityscapes 3D, extending the original Cityscapes dataset with 3D bounding box annotations for all types of vehicles. In contrast to existing datasets, our 3D annotations were labeled using stereo RGB images only and capture all nine degrees of freedom. This leads to a pixel-accurate reprojection in the RGB image and a higher range of annotations compared to lidar-based approaches. In order to ease multitask learning, we provide a pairing of 2D instance segments with 3D bounding boxes. In addition, we complement the Cityscapes benchmark suite with 3D vehicle detection based on the new annotations as well as metrics presented in this work. Dataset and benchmark are available online.
Slanted Stixels: A way to represent steep streets
Oct 02, 2019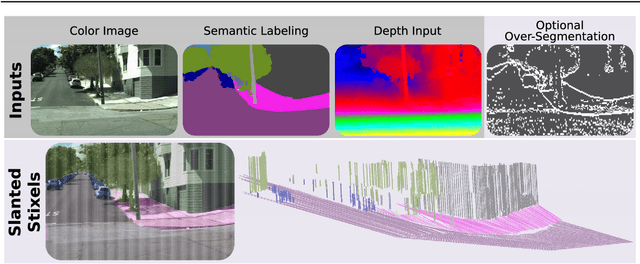
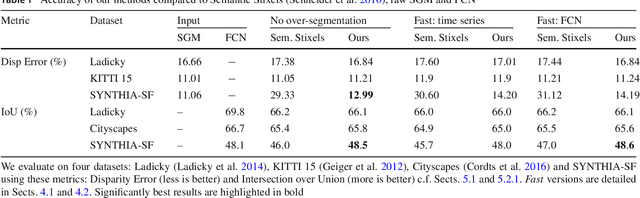

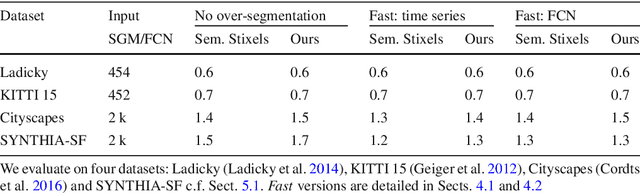
This work presents and evaluates a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced in order to significantly reduce the computational complexity of the Stixel algorithm, and then achieve real-time computation capabilities. The idea is to first perform an over-segmentation of the image, discarding the unlikely Stixel cuts, and apply the algorithm only on the remaining Stixel cuts. This work presents a novel over-segmentation strategy based on a Fully Convolutional Network (FCN), which outperforms an approach based on using local extrema of the disparity map. We evaluate the proposed methods in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
* Journal preprint (published in IJCV 2019: https://link.springer.com/article/10.1007/s11263-019-01226-9). arXiv admin note: text overlap with arXiv:1707.05397
Sparsity Invariant CNNs
Aug 30, 2017
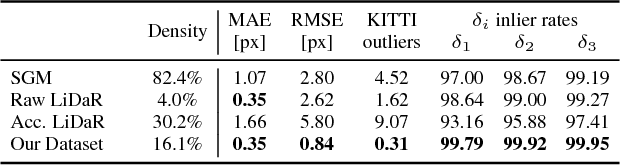

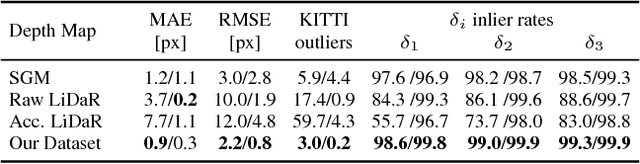
In this paper, we consider convolutional neural networks operating on sparse inputs with an application to depth upsampling from sparse laser scan data. First, we show that traditional convolutional networks perform poorly when applied to sparse data even when the location of missing data is provided to the network. To overcome this problem, we propose a simple yet effective sparse convolution layer which explicitly considers the location of missing data during the convolution operation. We demonstrate the benefits of the proposed network architecture in synthetic and real experiments with respect to various baseline approaches. Compared to dense baselines, the proposed sparse convolution network generalizes well to novel datasets and is invariant to the level of sparsity in the data. For our evaluation, we derive a novel dataset from the KITTI benchmark, comprising 93k depth annotated RGB images. Our dataset allows for training and evaluating depth upsampling and depth prediction techniques in challenging real-world settings and will be made available upon publication.
Slanted Stixels: Representing San Francisco's Steepest Streets
Jul 17, 2017
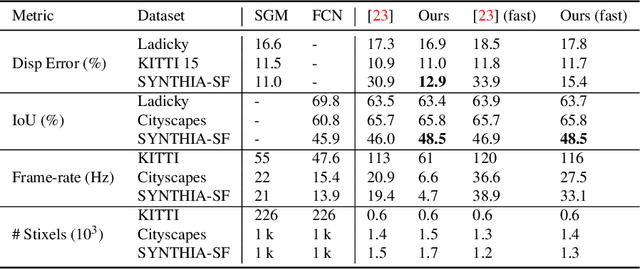
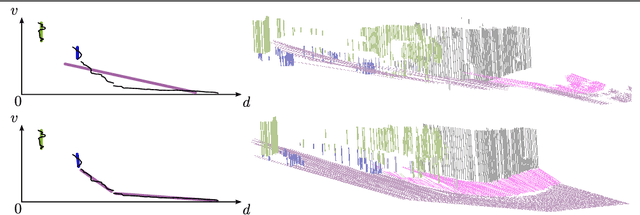
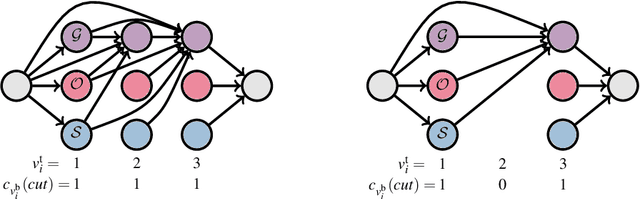
In this work we present a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced that uses an extremely efficient over-segmentation. In doing so, the computational complexity of the Stixel inference algorithm is reduced significantly, achieving real-time computation capabilities with only a slight drop in accuracy. We evaluate the proposed approach in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
RegNet: Multimodal Sensor Registration Using Deep Neural Networks
Jul 11, 2017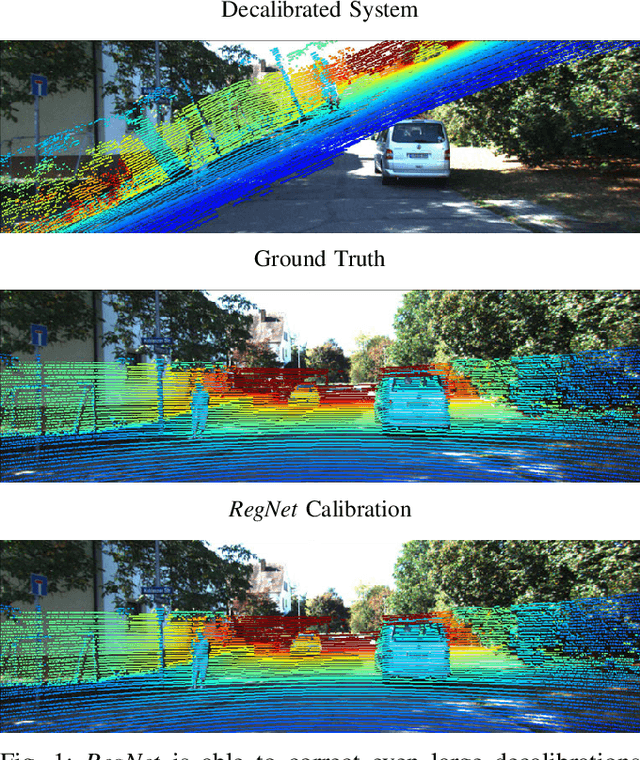
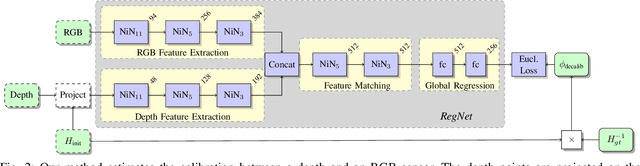

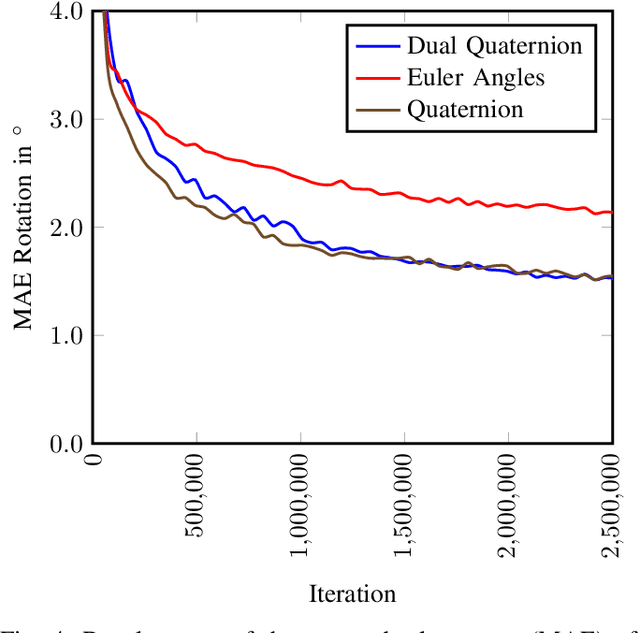
In this paper, we present RegNet, the first deep convolutional neural network (CNN) to infer a 6 degrees of freedom (DOF) extrinsic calibration between multimodal sensors, exemplified using a scanning LiDAR and a monocular camera. Compared to existing approaches, RegNet casts all three conventional calibration steps (feature extraction, feature matching and global regression) into a single real-time capable CNN. Our method does not require any human interaction and bridges the gap between classical offline and target-less online calibration approaches as it provides both a stable initial estimation as well as a continuous online correction of the extrinsic parameters. During training we randomly decalibrate our system in order to train RegNet to infer the correspondence between projected depth measurements and RGB image and finally regress the extrinsic calibration. Additionally, with an iterative execution of multiple CNNs, that are trained on different magnitudes of decalibration, our approach compares favorably to state-of-the-art methods in terms of a mean calibration error of 0.28 degrees for the rotational and 6 cm for the translation components even for large decalibrations up to 1.5 m and 20 degrees.
The Stixel world: A medium-level representation of traffic scenes
Apr 02, 2017

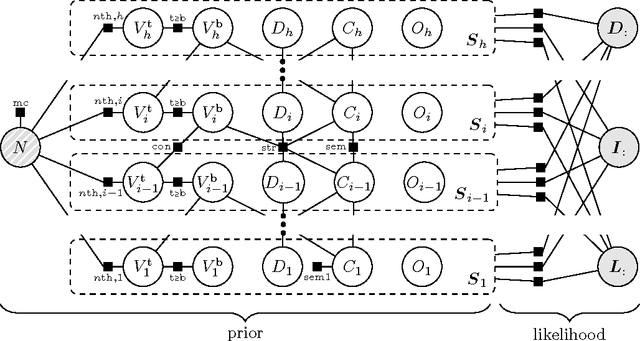

Recent progress in advanced driver assistance systems and the race towards autonomous vehicles is mainly driven by two factors: (1) increasingly sophisticated algorithms that interpret the environment around the vehicle and react accordingly, and (2) the continuous improvements of sensor technology itself. In terms of cameras, these improvements typically include higher spatial resolution, which as a consequence requires more data to be processed. The trend to add multiple cameras to cover the entire surrounding of the vehicle is not conducive in that matter. At the same time, an increasing number of special purpose algorithms need access to the sensor input data to correctly interpret the various complex situations that can occur, particularly in urban traffic. By observing those trends, it becomes clear that a key challenge for vision architectures in intelligent vehicles is to share computational resources. We believe this challenge should be faced by introducing a representation of the sensory data that provides compressed and structured access to all relevant visual content of the scene. The Stixel World discussed in this paper is such a representation. It is a medium-level model of the environment that is specifically designed to compress information about obstacles by leveraging the typical layout of outdoor traffic scenes. It has proven useful for a multitude of automotive vision applications, including object detection, tracking, segmentation, and mapping. In this paper, we summarize the ideas behind the model and generalize it to take into account multiple dense input streams: the image itself, stereo depth maps, and semantic class probability maps that can be generated, e.g., by CNNs. Our generalization is embedded into a novel mathematical formulation for the Stixel model. We further sketch how the free parameters of the model can be learned using structured SVMs.
Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
Dec 20, 2016
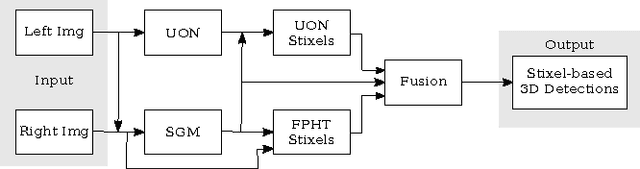

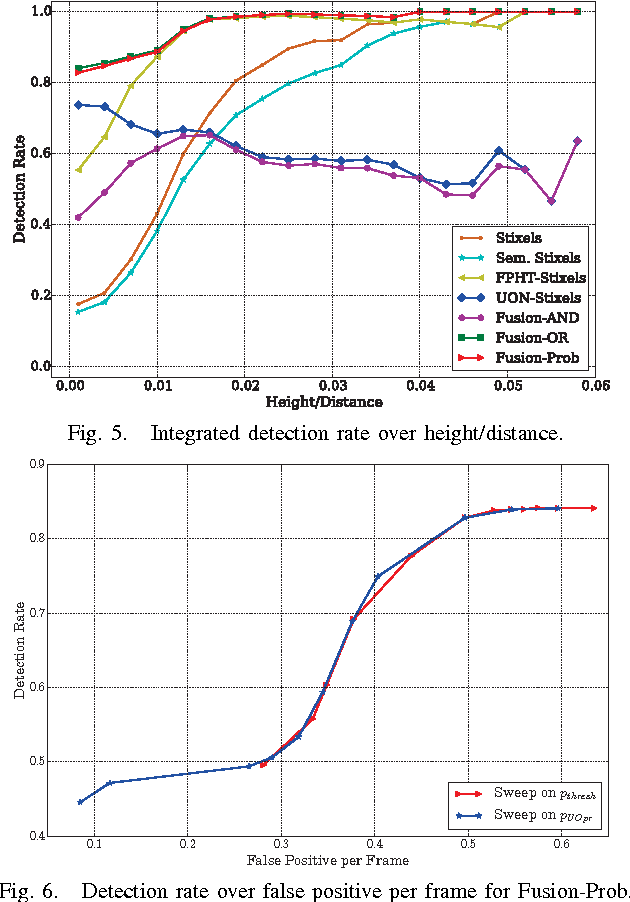
The detection of small road hazards, such as lost cargo, is a vital capability for self-driving cars. We tackle this challenging and rarely addressed problem with a vision system that leverages appearance, contextual as well as geometric cues. To utilize the appearance and contextual cues, we propose a new deep learning-based obstacle detection framework. Here a variant of a fully convolutional network is used to predict a pixel-wise semantic labeling of (i) free-space, (ii) on-road unexpected obstacles, and (iii) background. The geometric cues are exploited using a state-of-the-art detection approach that predicts obstacles from stereo input images via model-based statistical hypothesis tests. We present a principled Bayesian framework to fuse the semantic and stereo-based detection results. The mid-level Stixel representation is used to describe obstacles in a flexible, compact and robust manner. We evaluate our new obstacle detection system on the Lost and Found dataset, which includes very challenging scenes with obstacles of only 5 cm height. Overall, we report a major improvement over the state-of-the-art, with relative performance gains of up to 50%. In particular, we achieve a detection rate of over 90% for distances of up to 50 m. Our system operates at 22 Hz on our self-driving platform.