 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Depth Completion for Active Stereo
Oct 07, 2021


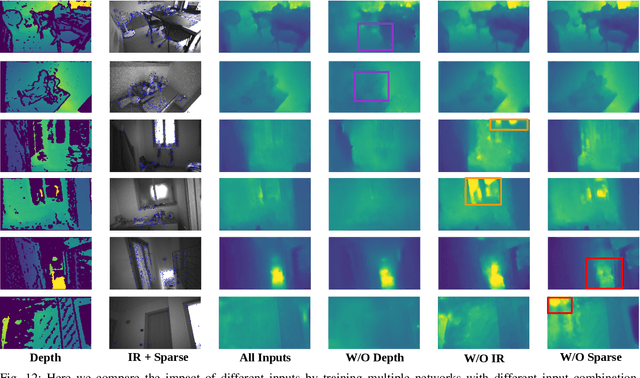
Active stereo systems are widely used in the robotics industry due to their low cost and high quality depth maps. These depth sensors, however, suffer from stereo artefacts and do not provide dense depth estimates. In this work, we present the first self-supervised depth completion method for active stereo systems that predicts accurate dense depth maps. Our system leverages a feature-based visual inertial SLAM system to produce motion estimates and accurate (but sparse) 3D landmarks. The 3D landmarks are used both as model input and as supervision during training. The motion estimates are used in our novel reconstruction loss that relies on a combination of passive and active stereo frames, resulting in significant improvements in textureless areas that are common in indoor environments. Due to the non-existence of publicly available active stereo datasets, we release a real dataset together with additional information for a publicly available synthetic dataset needed for active depth completion and prediction. Through rigorous evaluations we show that our method outperforms state of the art on both datasets. Additionally we show how our method obtains more complete, and therefore safer, 3D maps when used in a robotic platform
A Multi-Hypothesis Approach to Color Constancy
Mar 02, 2020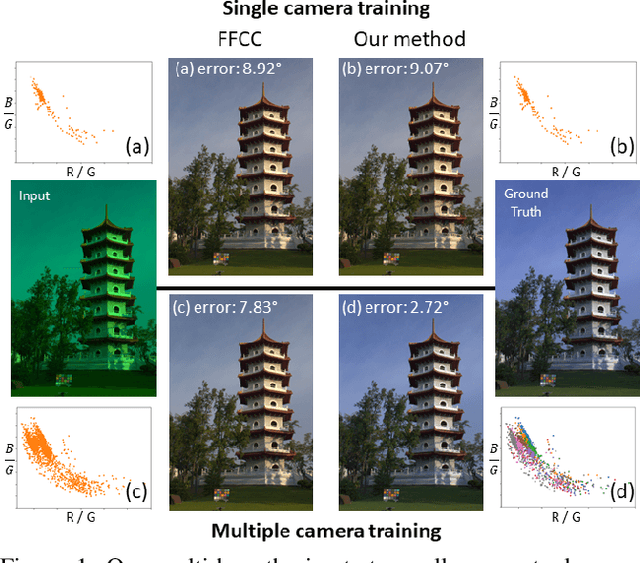
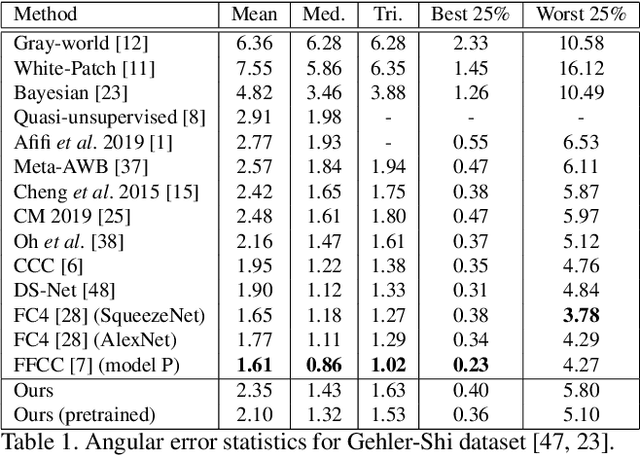
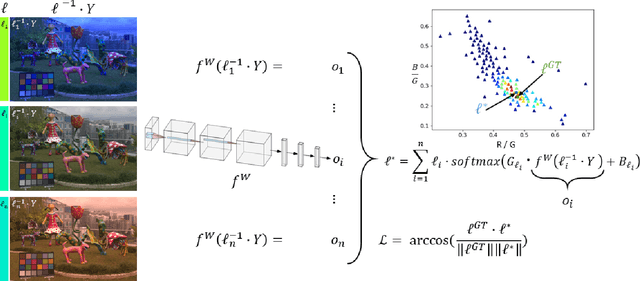
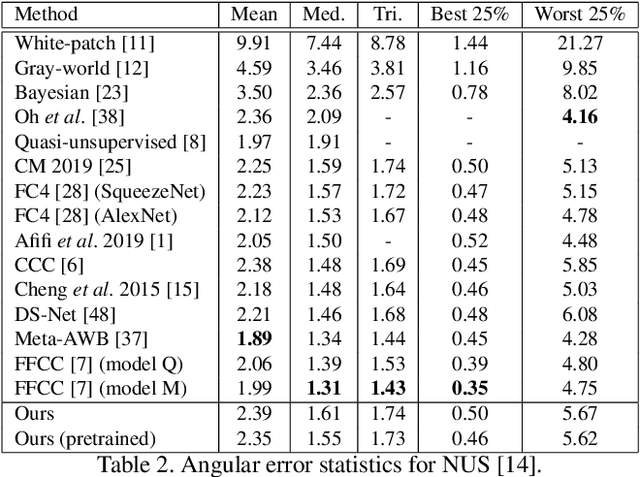
Contemporary approaches frame the color constancy problem as learning camera specific illuminant mappings. While high accuracy can be achieved on camera specific data, these models depend on camera spectral sensitivity and typically exhibit poor generalisation to new devices. Additionally, regression methods produce point estimates that do not explicitly account for potential ambiguities among plausible illuminant solutions, due to the ill-posed nature of the problem. We propose a Bayesian framework that naturally handles color constancy ambiguity via a multi-hypothesis strategy. Firstly, we select a set of candidate scene illuminants in a data-driven fashion and apply them to a target image to generate of set of corrected images. Secondly, we estimate, for each corrected image, the likelihood of the light source being achromatic using a camera-agnostic CNN. Finally, our method explicitly learns a final illumination estimate from the generated posterior probability distribution. Our likelihood estimator learns to answer a camera-agnostic question and thus enables effective multi-camera training by disentangling illuminant estimation from the supervised learning task. We extensively evaluate our proposed approach and additionally set a benchmark for novel sensor generalisation without re-training. Our method provides state-of-the-art accuracy on multiple public datasets (up to 11% median angular error improvement) while maintaining real-time execution.
Slanted Stixels: A way to represent steep streets
Oct 02, 2019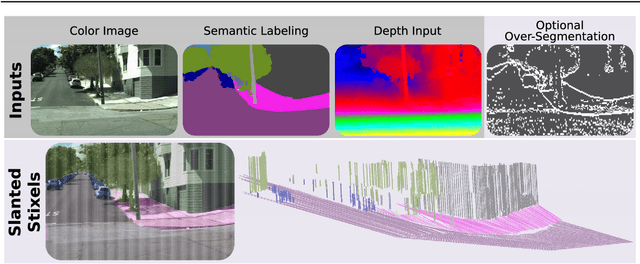
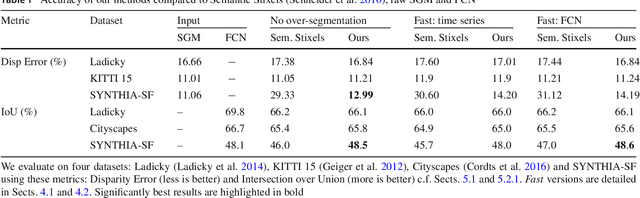

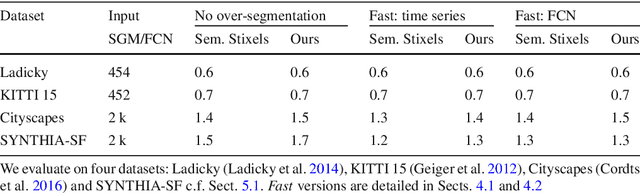
This work presents and evaluates a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced in order to significantly reduce the computational complexity of the Stixel algorithm, and then achieve real-time computation capabilities. The idea is to first perform an over-segmentation of the image, discarding the unlikely Stixel cuts, and apply the algorithm only on the remaining Stixel cuts. This work presents a novel over-segmentation strategy based on a Fully Convolutional Network (FCN), which outperforms an approach based on using local extrema of the disparity map. We evaluate the proposed methods in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
* Journal preprint (published in IJCV 2019: https://link.springer.com/article/10.1007/s11263-019-01226-9). arXiv admin note: text overlap with arXiv:1707.05397
Slanted Stixels: Representing San Francisco's Steepest Streets
Jul 17, 2017
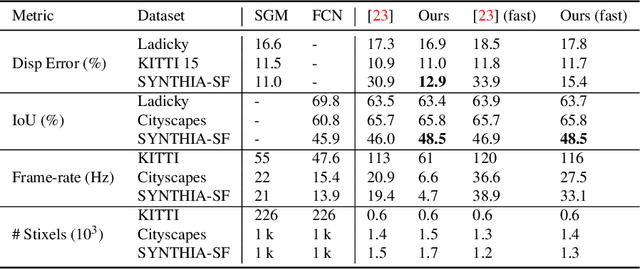
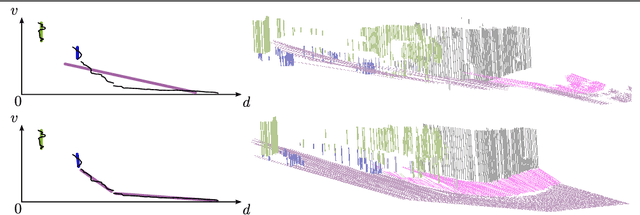
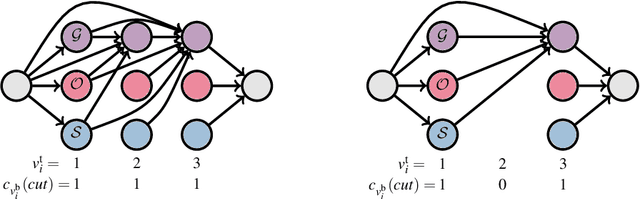
In this work we present a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced that uses an extremely efficient over-segmentation. In doing so, the computational complexity of the Stixel inference algorithm is reduced significantly, achieving real-time computation capabilities with only a slight drop in accuracy. We evaluate the proposed approach in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
GPU-accelerated real-time stixel computation
Oct 13, 2016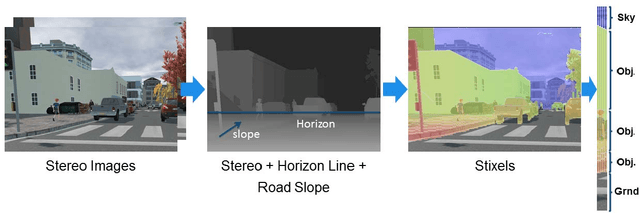

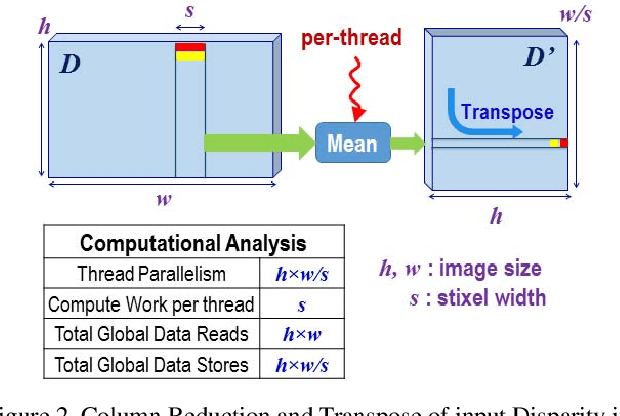
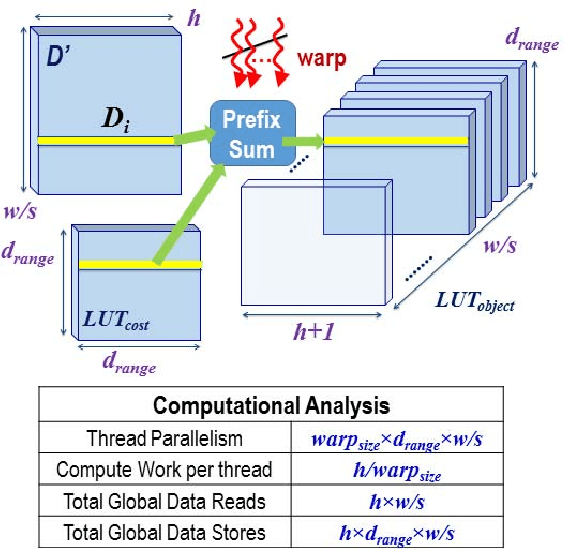
The Stixel World is a medium-level, compact representation of road scenes that abstracts millions of disparity pixels into hundreds or thousands of stixels. The goal of this work is to implement and evaluate a complete multi-stixel estimation pipeline on an embedded, energy-efficient, GPU-accelerated device. This work presents a full GPU-accelerated implementation of stixel estimation that produces reliable results at 26 frames per second (real-time) on the Tegra X1 for disparity images of 1024x440 pixels and stixel widths of 5 pixels, and achieves more than 400 frames per second on a high-end Titan X GPU card.
Embedded real-time stereo estimation via Semi-Global Matching on the GPU
Oct 13, 2016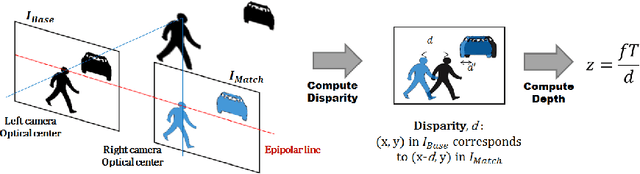
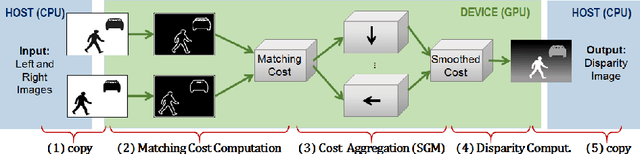
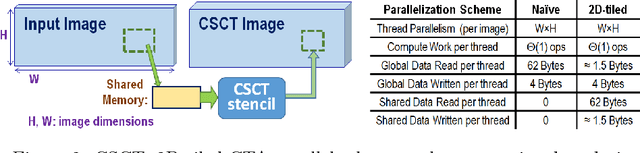
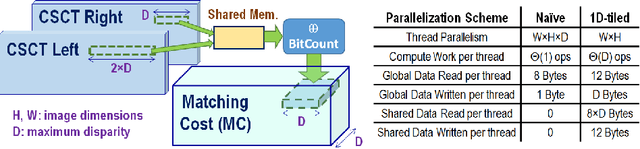
Dense, robust and real-time computation of depth information from stereo-camera systems is a computationally demanding requirement for robotics, advanced driver assistance systems (ADAS) and autonomous vehicles. Semi-Global Matching (SGM) is a widely used algorithm that propagates consistency constraints along several paths across the image. This work presents a real-time system producing reliable disparity estimation results on the new embedded energy-efficient GPU devices. Our design runs on a Tegra X1 at 42 frames per second (fps) for an image size of 640x480, 128 disparity levels, and using 4 path directions for the SGM method.